15445-03-Storage(I)
发布于 • 作者: Ethan
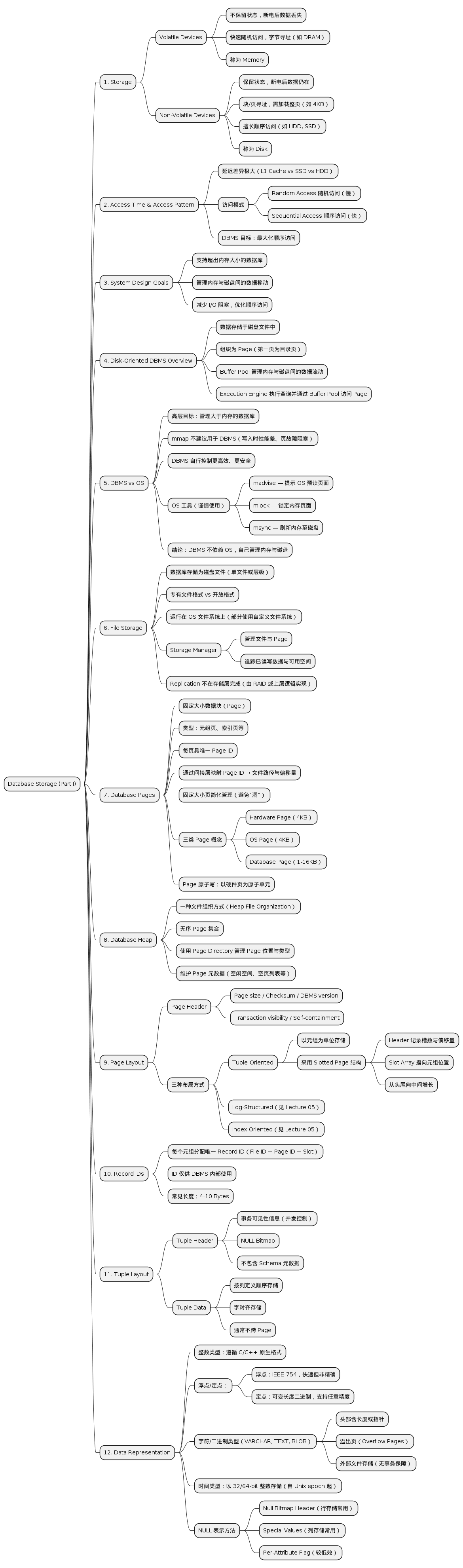
In this class, we focus on a “disk-oriented” DBMS architecture that assumes that the primary storage location of the database is on non-volatile disk(s). 在本课程中,我们关注一种“面向磁盘”的 DBMS 架构,该架构假设数据库的主要存储位置在非易失性磁盘上。
At the top of the storage hierarchy, you have the devices that are closest to the CPU. This is the fastest storage, but it is also the smallest and most expensive. The further you get away from the CPU, the larger but slower the storage devices get. These devices also get cheaper per GB. 在存储层次结构的顶层,您拥有最接近 CPU 的设备。这是最快的存储,但它也是最小且最昂贵的。您离 CPU 越远,存储设备就越大但速度越慢。这些设备每 GB 的价格也越便宜。
There’s also a demarcation line in the middle of the hierarchy that separates volatile devices from non-volatile devices. 在层次结构的中部还有一个分界线,将易失性设备与非易失性设备分开。
There is a large latency contrast between volatile and non-volatile devices. 易失性设备和非易失性设备之间存在较大的延迟差异。 If reading from the L1 cache took 1 second, then: 如果从 L1 缓存读取需要 1 秒,那么:
Two major access patterns exist: random access and sequential access. 存在两种主要的访问模式:随机访问和顺序访问。 Random access on disk is much slower, so DBMSs aim to maximize sequential access — sometimes buffering random writes sequentially and flushing asynchronously. 磁盘上的随机访问速度要慢得多,因此 DBMS(数据库管理系统)旨在最大化顺序访问——有时将随机写入顺序缓冲并异步刷新。
The disk-oriented DBMS must manage databases larger than memory capacity. 面向磁盘的数据库管理系统必须管理大于内存容量的数据库。 Frequent movement between disk and memory requires careful management to: 频繁地在磁盘和内存之间移动需要仔细管理,以:
The database resides on disk, organized into pages. 数据库驻留在磁盘上,组织成页。 To operate, the DBMS brings data pages into memory via a buffer pool. 为了运行,DBMS 通过缓冲池将数据页带入内存。
Like virtual memory, the DBMS manages data larger than physical memory. 如同虚拟内存一样,数据库管理系统(DBMS)管理的数据比物理内存要大。 However, the DBMS does not rely on the OS to manage page swapping. 然而,数据库管理系统不依赖操作系统来管理页面交换。
mmap() for correctness and performance reasons.
数据库管理系统出于正确性和性能的考虑,避免使用 mmap() 。OS utilities (optional use): 操作系统工具(可选使用):
madvise: hints for read-ahead.
madvise : 预读提示。mlock: prevents swapping memory to disk.
mlock : 防止内存交换到磁盘。msync: flushes memory to disk.
msync : 将内存刷新到磁盘。The operating system is not your friend. 操作系统不是你的朋友。
Implementing these functions inside the DBMS allows better performance and control. 在 DBMS 中实现这些功能可以更好地提高性能和控制。
A DBMS stores databases as files on disk. 一个数据库管理系统将数据库存储为磁盘上的文件。
DBMSs typically use OS-provided file systems, though enterprise systems (e.g., Oracle ASM) may use custom ones. 数据库管理系统通常使用操作系统提供的文件系统,尽管企业系统(例如 Oracle ASM)可能会使用自定义的文件系统。
The storage manager: 存储管理器:
Databases are organized into fixed-size blocks (pages). 数据库被组织成固定大小的块(页面)。 Pages may contain tuples, indexes, or metadata. 页面可以包含元组、索引或元数据。
Larger pages → better for read-heavy workloads (≥1MB) 大页 → 更适合读密集型工作负载(≥1MB) Smaller pages → better for write-heavy workloads (4–16KB) 较小的页面 → 更适合写密集型工作负载(4–16KB)
If a DBMS page > hardware page, crash recovery mechanisms are needed to ensure atomic writes. 如果数据库管理系统页面 > 硬件页面,需要崩溃恢复机制来确保原子写入。
Heap File Organization: 堆文件组织: Unordered pages where tuples are stored arbitrarily. 无序页面,其中元组被任意存储。
Each page includes a header with metadata: 每页包含一个带有元数据的页眉:
Full page: when slot array meets tuple data. 满页:当插槽数组遇到元组数据时。
(Log-structured and index-oriented layouts are covered in Lecture 05.) (日志结构化和索引导向布局在第五讲中讲解。)
Each logical tuple has a unique record identifier (RID) representing its physical location: 每个逻辑元组都有一个唯一的记录标识符(RID),代表其物理位置:
A tuple is a sequence of bytes representing attribute values. 元组是一个表示属性值的字节序列。
INTEGER, BIGINT, SMALLINT, TINYINT:
Stored in native C/C++ format.
以原生 C/C++格式存储。
FLOAT / REAL: IEEE-754 (inexact, fast).
FLOAT / REAL : IEEE-754(不精确,快速)。NUMERIC / DECIMAL: Fixed-point (exact, slower).
NUMERIC / DECIMAL : 固定点(精确,较慢)。VARCHAR, VARBINARY, TEXT, BLOB:
Stored as (header + data) or pointer to external page.
以(header + 数据)或指向外部页面的指针形式存储。
TIME, DATE, TIMESTAMP, INTERVAL:
Stored as 32/64-bit integers of micro/milliseconds since Unix epoch.
存储为自 Unix 纪元以来的 32/64 位微秒/毫秒整数。
INT32_MIN), used in column-stores.
特殊值——用于列式存储的空值占位符(例如, INT32_MIN )。