15445-07-HashTables
发布于 • 作者: Ethan
数据库管理系统(DBMS)在系统的不同部分使用多种数据结构。常见示例包括:
内部元数据:用于跟踪数据库信息及系统状态。
例如:页表(Page Tables)、页目录(Page Directories)
核心数据存储:数据结构存储数据库中的实际元组(记录)。
临时数据结构:DBMS 在查询执行时可以动态构建临时结构以加速处理。
例如:用于连接操作的哈希表。
表索引:辅助数据结构,用于高效定位特定元组。
实现这些数据结构时,需要考虑两项关键设计决策:
哈希表实现了一个将“键”映射到“值”的关联数组(associative array)。
其平均操作复杂度为 O(1)(最坏为 O(n)),存储复杂度为 O(n)。
即使平均复杂度为常数,也需注意常数因子的性能优化。哈希表不保证键的顺序性,因此无法顺序遍历。
哈希表由两部分组成:
哈希函数(Hash Function):将大的键空间映射到较小的索引空间(桶/槽)。
哈希方案(Hashing Scheme):定义冲突处理机制。
需权衡空间浪费与冲突时的额外操作代价。
哈希函数接受任意键作为输入,输出其整数表示(哈希值)。
输出必须确定性(deterministic):相同键必须生成相同哈希。
当前最先进的哈希函数是 Facebook 的 XXHash3。
静态哈希方案的哈希表大小在创建前固定。若空间耗尽,必须整体重建更大表(通常扩容为原来的两倍),代价高昂。
为减少冲突,应预留充足空间(常取预期元素数量的两倍槽位)。
常见的错误假设包括:
因此,必须合理选择哈希函数与方案。
最基本且通常最快的方案。
其原理是使用**环形缓冲区(circular buffer)**存储槽位。
实例: Google 的
absl::flat_hash_map是线性探测哈希的先进实现。
通过多个哈希函数将键映射到不同槽(通常位于同一个表中)。
哈希函数算法相同,但使用不同种子以生成不同哈希值。
O(1);教授注:布谷鸟哈希的本质是利用多个哈希函数映射到不同槽。
实际实现中,这些槽通常位于单个哈希表中。
静态哈希表需要预知元素数量,否则需整体重建。
动态哈希方案能按需调整大小,无需重建全部数据。其扩展方式可偏向读或写优化。
最常见的动态方案。
每个槽对应一个桶链表,所有哈希到同一槽的键插入同一链表。
查找时,哈希到桶后遍历链表即可。
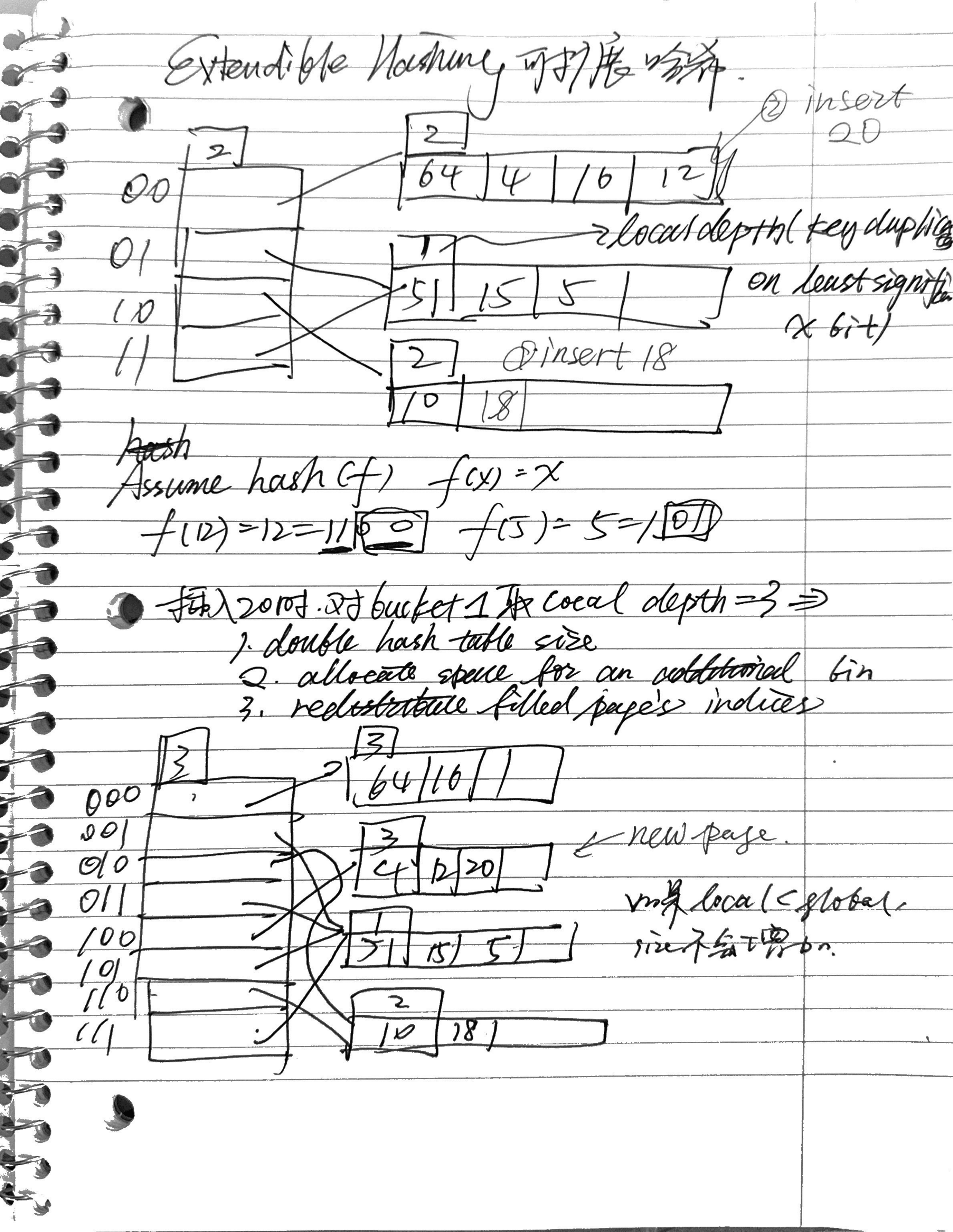
链式哈希的改进版本,通过拆分桶而非无限延长链表。
支持多个槽指向同一桶链,从而减少重组开销。
关键机制:
维护一个分裂指针(split pointer),记录下一个待分裂的桶。
当任意桶溢出时,总是分裂指针所指桶。分裂规则灵活。
操作流程:
优势:
线性哈希能逐步扩展或收缩表,避免整体重建的高成本。