15445-09-IndexesFilters(II)
发布于 • 作者: Ethan
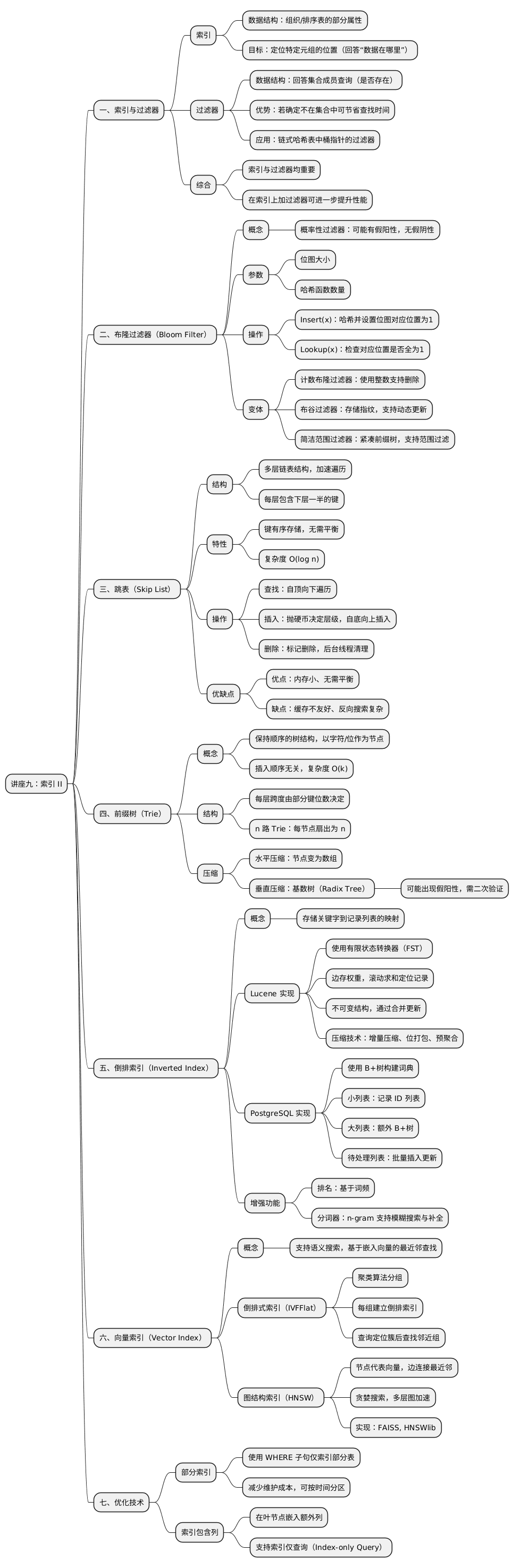
索引是一种数据结构,它将表的部分属性组织并/或排序,以便使用这些属性定位特定元组的位置,回答“数据在哪里”的问题。 过滤器是一种数据结构,用于回答集合成员查询——“该元素是否存在于集合中?”
如果数据库管理系统(DBMS)知道某个元素不在集合中,就能节省查找时间。例如,在链式哈希表中,可在每个桶指针处放置过滤器;若过滤器返回否定,则可跳过整个链表查找。 索引与过滤器在数据库中均不可或缺,有时在索引上叠加过滤器能进一步提升性能。
布隆过滤器是一种基于位图的概率性过滤器,即它可能出现假阳性(false positive),但绝不会出现假阴性(false negative)。
布隆过滤器需定义:
布隆过滤器 API 仅支持两种操作,且不能删除元素:
对元素 x 使用多个预定义哈希函数,每个函数输出的哈希值对位图大小取模,并将对应位置设为 1。
对元素 x 执行相同的哈希计算。若位图中的任意对应位置不为 1,则返回 false;否则返回 true,但仍需进一步验证。
其他变体:
跳表通过多层链表结构“跳过”部分节点以加速遍历。
每层包含下层一半的键:底层含所有键,上一层连接每隔一个键,依此类推。
与 B+ 树类似,键有序存储,但跳表无需重平衡,插入与删除仍保持 O(log n) 搜索复杂度。
从顶层链表开始,遍历至大于目标值的位置后下降一层,重复该过程直至找到目标键。
通过抛硬币决定节点应插入的层级。自底向上插入以保持结构一致,避免读写线程间的竞态问题。
节点通过布尔标志标记删除,实际物理删除通常由后台线程周期执行。删除时自上而下逐层移除以维持结构完整性。
优点:
缺点:
B+ 树无法判断内部节点下是否存在目标节点,需访问叶节点确认,代价高昂。
Trie 是一种保持顺序的数据结构,以“数字”或“字符”作为节点表示前缀。
树形结构仅依赖键的内容与长度,而非插入顺序,所有操作复杂度为 O(k)(k 为键长)。
每层跨度由每部分键的位数决定。若该位存在则存储指针,否则为空。 n 路 Trie 表示每节点扇出为 n。
水平压缩:若层跨度固定,可将节点压缩为数组(而非映射)。
垂直压缩(基数树 Radix Tree):若节点仅有单一子节点,可合并下层节点。
传统索引适用于点查询与范围查询,但不支持关键字搜索。 倒排索引存储“关键字→包含该词的记录列表(倒排列表)”的映射。
Lucene 使用类似 Trie 的有限状态转换器(Finite State Transducer)。 不同于 Trie 的指针存储,它在每条边上存储权重。 沿路径遍历时,权重累积可精确定位目标记录在字典中的偏移位置。
该结构为不可变(Immutable),增量更新通过构建新转换器并后台合并实现。 词典使用增量压缩、位打包等技术,并支持预聚合加速查询。
PostgreSQL 的**广义倒排索引(GIN)**采用 B+ 树构建词典:
倒排索引仅支持关键字匹配,无法理解语义相似度。 大型语言模型可生成文本嵌入(embedding)——浮点向量,语义相似的向量在几何空间中接近。 向量索引用于最近邻搜索(Nearest Neighbor Search)。
将向量通过聚类算法分组,每组对应一个簇中心并建立倒排索引。 搜索时定位查询所属簇,再查找组内及邻近组向量。 常用实现:IVFFlat。
构建图表示向量邻接关系,每节点连接其 n 个最近邻。 搜索时贪婪地沿边移动至目标向量,可采用多层图加速(类似跳表)。 常用实现:FAISS、HNSWlib。
在索引定义中加入 WHERE 子句,仅索引表的子集以减小体积与维护开销。
例如,可按日期分区,为每月或每年创建独立索引。
在索引叶节点中嵌入额外列以支持仅索引查询(Index-only Query)。 若查询所需属性皆在索引中,DBMS 无需回表访问元组。



