15445-04-MemoryManagement
发布于 • 作者: Ethan
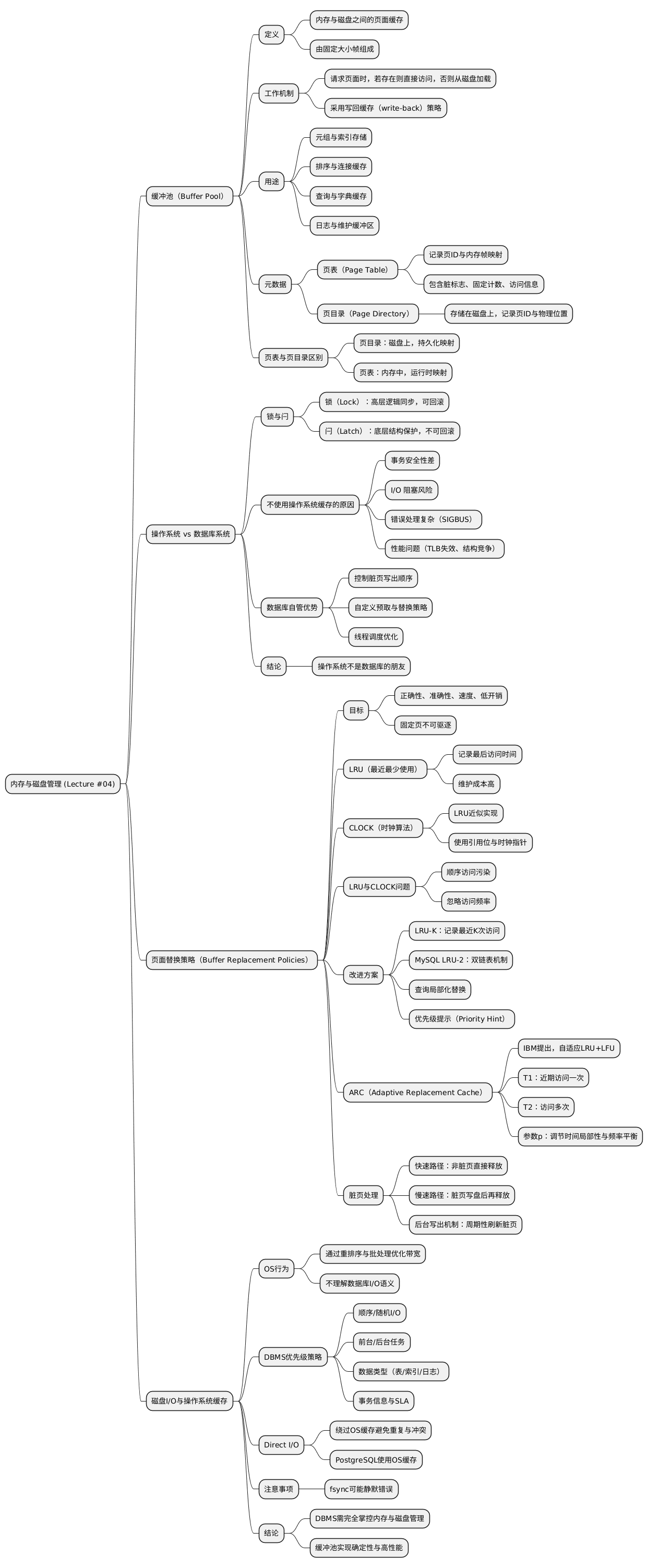
缓冲池是位于内存与磁盘之间的页面缓存区,用于临时存储数据库页面。
其本质是数据库内部的一块大内存区域,由固定大小的帧(frame)组成。
当数据库请求页面时:
缓冲池一般采用**写回缓存(write-back cache)机制:
被修改的脏页不会立即写回磁盘,而是暂时保留在内存中,等待后台刷新。
这与直写缓存(write-through cache)**不同。
部分结构可直接使用系统内存分配(如 malloc),不一定经过缓冲池管理。
磁盘上维护有页目录(page directory),用于记录页面 ID 与其在文件中的位置映射。
目录在数据库重启后用于恢复定位,通常在内存中也保留一份以减少访问延迟。
缓冲池管理器需要维护多种元数据:
若页面的固定计数 > 0,则不可被驱逐;
若所有页均被固定且缓冲池已满,则会触发“内存耗尽”错误。
| 名称 | 存储位置 | 功能 |
|---|---|---|
| 页目录(Page Directory) | 磁盘 | 记录页面在物理文件中的位置,持久化保存。 |
| 页表(Page Table) | 内存 | 记录页面在缓冲池中的帧号映射,仅驻留内存。 |
锁(Lock):
高层逻辑同步机制,用于保护数据库内容(如元组、表等),支持事务回滚,可被用户查询。
闩(Latch):
低层内部同步原语,用于保护数据库内部结构(如哈希表、内存区域),通常由互斥锁或条件变量实现,不支持回滚,仅在操作期间持有。
如果使用操作系统的页缓存(如 mmap),会带来以下问题:
SIGBUS);虽然系统调用如 madvise、mlock、msync 能一定程度改善,但管理复杂。
数据库系统通常选择自行管理,以实现:
结论: 操作系统不是数据库的朋友。
当缓冲池空间不足时,DBMS 需要决定驱逐哪一页。
驱逐策略目标包括:正确性、准确性、速度与低元数据开销。
固定页(Pinned Page)不可被驱逐。
维护每页最后访问时间戳,驱逐时间最久未访问的页。
可借助队列或链表排序,但维护代价高(尤其是时间戳更新开销大)。
LRU 的近似实现,无需时间戳。
每页有一个引用位(reference bit):
二者容易受到顺序访问污染(Sequential Flooding):
顺序扫描会快速替换整个缓冲池,使其他查询的页被逐出。
此外,它们不考虑访问频率:
若某页长期频繁访问但近期未访问,也可能被错误驱逐。
LRU-K:
记录最近 K 次访问时间,计算访问间隔,预测下次访问时间;
需较大存储开销,并需维护“幽灵缓存”(Ghost Cache)记录最近驱逐页。
MySQL LRU-2 近似算法:
采用两条链表(旧链表与年轻链表);
若访问的页在旧链表中,则移入年轻链表;驱逐从旧链表尾部进行。
查询局部化(Localization per Query):
每个查询独立选择驱逐页,避免跨查询污染。
优先级提示(Priority Hints):
查询根据执行上下文标注页面重要性。
由 IBM 研究院提出,结合 LRU 与 LFU 的自适应替换算法。
通过动态调整两种缓存区比例来适应访问模式变化。
被修改的页需在驱逐前写回磁盘:
为避免写盘瓶颈,可使用**后台写出(Background Writing)**机制:
周期性扫描页表并刷新脏页,写回成功后可清除脏标志或释放页。
操作系统与硬件会通过请求重排序与批处理优化磁盘带宽,
但不了解数据库请求的语义与优先级。
由于操作系统不了解这些上下文,常会干扰性能。
多数 DBMS 使用 Direct I/O(O_DIRECT) 绕过 OS 缓存,
避免重复缓存与策略冲突。
例如:PostgreSQL 依赖操作系统缓存,而其他系统多采用直接 I/O。
注意:
fsync默认可能静默忽略错误,并错误地标记页面为“已干净”。
总结:
数据库系统通常需要完全掌控自身的内存与磁盘管理。
操作系统的缓存与调度机制在数据库场景下往往低效甚至有害。
因此,现代 DBMS 通过缓冲池管理器独立实现缓存、替换与写出策略,以获得确定性与高性能。


