15445-11-Sorting&AggregationsAlgorithms
发布于 • 作者: Ethan
到目前为止,我们讨论了访问方法。现在需要实际执行查询。
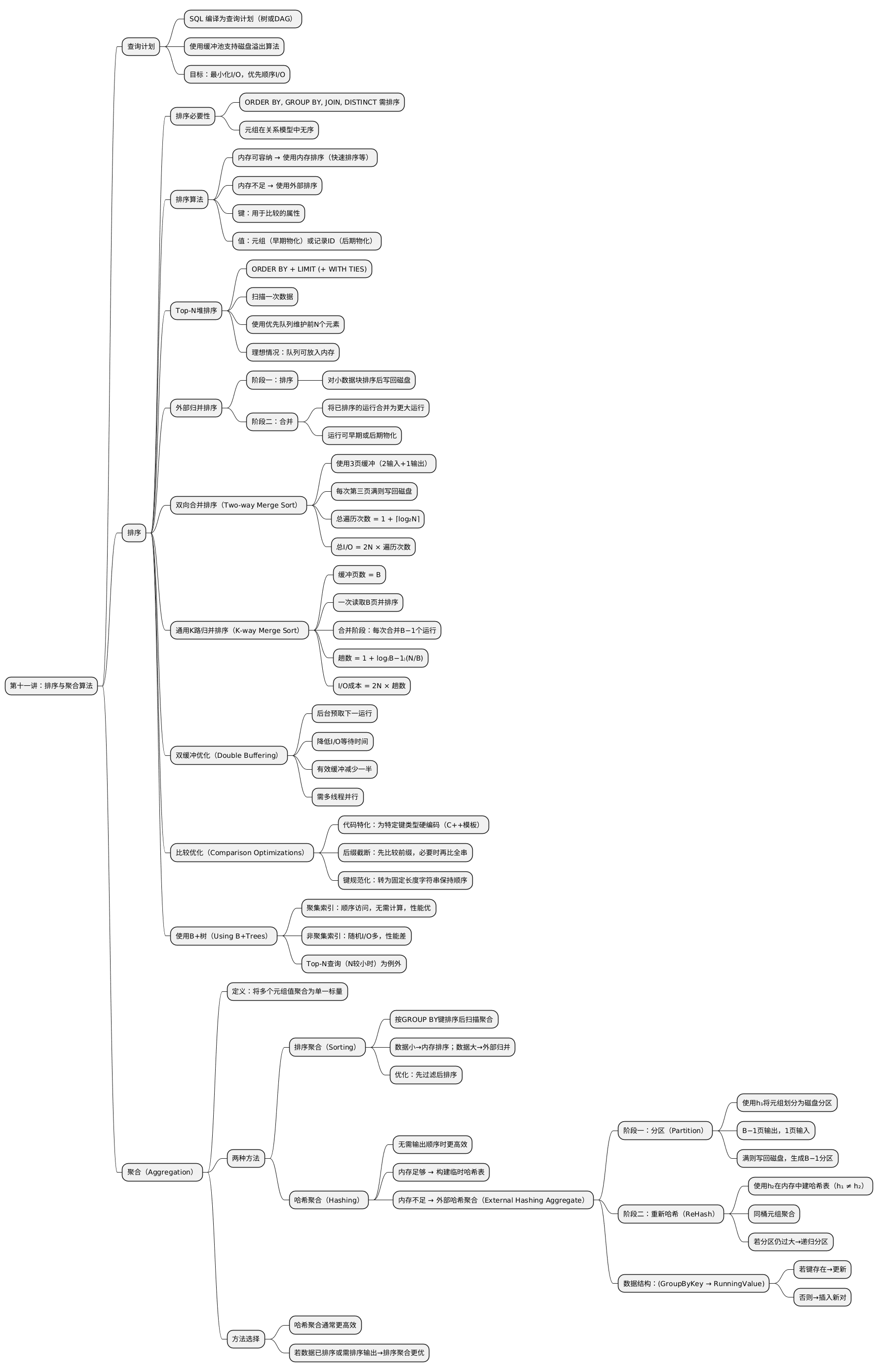
数据库系统会将 SQL 编译为一个查询计划(Query Plan),这是一个由操作符组成的树或有向无环图(DAG)。 在后续课程中将更详细地介绍操作符等内容。
对于面向磁盘的数据库系统,我们使用缓冲池(Buffer Pool)来实现需要溢出到磁盘的算法。 我们的目标是最小化 I/O,并优先使用顺序 I/O而非随机 I/O。
DBMS 需要排序,因为在关系模型下,表中的元组没有特定顺序。
ORDER BY、GROUP BY、JOIN、DISTINCT 等操作符都可能依赖排序。
若数据能装入内存,DBMS 可使用常规的内存排序算法(如快速排序、vergesort); 若数据过大,则需使用外部排序(External Sorting),以考虑磁盘操作成本。
排序算法处理输入运行(run)时,将键值对按比较函数和排序参数进行排序。 键用于确定排序顺序,值可以是:
若查询包含 ORDER BY 与 LIMIT(以及可选的 WITH TIES),
DBMS 只需扫描一次数据,并维护一个优先队列(priority queue)以记录前 N 个元素。
若包含 WITH TIES,则在遇到并列元素时动态扩展优先队列。
理想情况下,若前 N 个元素可存入内存,则整个过程可在内存中完成。
外部归并排序是排序无法完全放入内存数据的标准算法。 它是一种分治算法,主要包含两个阶段:
将可装入内存的小块数据排序后写回磁盘。
将已排序的运行逐步合并成更大的已排序运行。
运行可为早期物化或后期物化形式。
算法在排序阶段读取每页数据,排序后写回磁盘。 合并阶段使用三页缓冲:
每组已排序的页称为一个“运行(run)”,算法递归合并这些运行。
设:
则总遍历次数为:
1 + ⌈log₂N⌉
总 I/O 成本为:
2N × (遍历次数)
因为每趟均需对每页执行一次读取和写入。
若缓冲页总数为 B,则:
合并阶段可在每趟合并最多 B−1 个运行(B−1 页输入 + 1 页输出)。
遍历总数为:
1 + log₍B−1₎ (N / B)
总 I/O 成本同样为:
2N × (遍历次数)
通过后台预取下一运行并存入第二组缓冲区,可减少等待 I/O 的时间。 此法提高磁盘利用率,但有效缓冲区数减半,且需多线程并行执行。
键比较代价较高,可采用以下优化:
代码特化(Code Specialization): 将排序函数针对特定键类型硬编码,例如 C++ 模板特化。
后缀截断(Suffix Truncation): 对字符串键,先比较前缀;若相等再比较全字符串。
键规范化(Key Normalization): 将可变长度键转换为定长编码字符串,保持排序顺序。
若存在适当的 B+ 树索引,DBMS 可直接使用索引来完成排序。
若索引为聚集索引(Clustered Index), 则遍历索引即可获得顺序访问,效率优于外部归并排序。
若为非聚集索引(Unclustered Index), 则可能导致大量随机 I/O,通常性能更差。 例外情况:当执行 Top-N 查询且 N 相对较小时。
聚合操作符将多个元组的值合并为一个标量值。 主要有两种实现方式:
DBMS 先根据 GROUP BY 键排序,然后顺序扫描计算聚合结果。
若数据量小,可使用内存排序算法(如快速排序); 若数据量大,则使用外部归并排序。
优化建议: 若查询包含过滤条件,应先过滤后排序,以减少排序数据量。
哈希聚合在输出顺序不重要时通常更高效。
若哈希表可放入内存:
若哈希表过大,需采用外部哈希聚合(External Hashing Aggregate), 其为一种分治算法,包括两个阶段:
使用哈希函数 h₁ 将数据按键划分为磁盘分区。 若总缓冲页为 B,则有:
逐个读入分区,并使用另一个哈希函数 h₂(h₁ ≠ h₂) 在内存中构建哈希表。 将匹配元组放入相同桶中并执行聚合。
若分区仍过大,可递归继续分区直到能放入内存。
在 ReHash 阶段,存储形如:
(GroupByKey → RunningValue)
其中 RunningValue 依赖聚合函数(如 COUNT 与 SUM 用于 AVG 计算)。
插入逻辑:
二者选择取决于查询特性与系统优化: