xv6:一个简单的unix-like操作系统译文(一)
发布于 • 作者: Russ Cox, Frans Kaashoek, Robert Morris
操作系统的任务是在多个程序之间共享计算机资源,并提供比硬件本身更有用的一组服务。操作系统负责管理和抽象底层硬件,使得例如文字处理程序不必关心具体使用的是哪一种磁盘硬件。操作系统还在多个程序之间共享硬件,使它们能够同时运行(或看起来像是同时运行)。此外,操作系统还为程序之间的交互提供受控的方式,使它们能够共享数据或协同工作。
操作系统通过接口向用户程序提供服务。设计一个良好的接口并不容易。一方面,我们希望接口简单而精炼,这样更容易保证实现的正确性;另一方面,我们又可能希望为应用程序提供丰富而复杂的功能。解决这种矛盾的关键在于设计一组可以组合使用的基础机制,从而获得高度的通用性。
本书使用一个具体的操作系统作为例子来说明操作系统的概念。这个操作系统是 xv6,它提供了 Ken Thompson 和 Dennis Ritchie 的 Unix 操作系统所引入的基本接口,并在内部设计上模仿了 Unix。Unix 提供了一种简洁但高度可组合的接口,从而具备了令人惊讶的通用性。这种接口非常成功,以至于现代操作系统——如 BSD、Linux、macOS、Solaris,甚至在一定程度上包括 Microsoft Windows——都具有类 Unix 的接口。理解 xv6 是理解这些系统以及许多其他系统的良好起点。
如图 1.1 所示,xv6 采用传统的内核结构:一个称为内核的特殊程序为正在运行的程序提供服务。每个正在运行的程序称为一个进程。每个进程都拥有包含指令、数据和栈的内存。指令实现程序的计算逻辑,数据是计算所操作的变量,而栈用于组织过程调用。通常,一台计算机上会有多个进程,但只有一个内核。
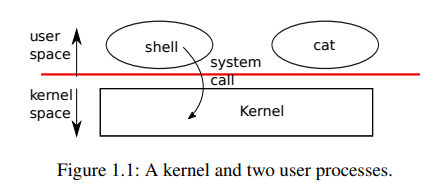
当一个进程需要请求内核提供服务时,它会发起一次系统调用,这是操作系统接口中的一种调用方式。系统调用会使控制权进入内核,由内核执行相应的服务并返回。因此,一个进程会在用户空间和内核空间之间交替执行。
如后续章节将详细说明的那样,内核利用 CPU 提供的硬件保护机制,确保每个在用户空间执行的进程只能访问属于自己的内存。内核以具备相应硬件特权的方式执行,从而能够实现这些保护机制;而用户程序则在不具备这些特权的情况下执行。当用户程序发起系统调用时,硬件会提升特权级别,并开始执行内核中预先约定的函数。
内核所提供的系统调用集合构成了用户程序所看到的接口。xv6 内核提供了 Unix 内核传统上所提供服务和系统调用的一个子集。图 1.2 列出了 xv6 的全部系统调用。
本章的其余部分将概述 xv6 提供的服务——包括进程、内存、文件描述符、管道和文件系统——并通过代码片段展示 shell(Unix 的命令行用户界面)如何使用这些服务。shell 对系统调用的使用方式很好地展示了这些接口的精心设计。
shell 是一个普通的程序,用于读取用户输入的命令并执行它们。shell 并不是内核的一部分,这一点体现了系统调用接口的强大之处:shell 并没有任何特殊地位。这也意味着 shell 很容易被替换;因此,现代 Unix 系统中存在多种 shell,每种都有其独特的用户界面和脚本特性。xv6 的 shell 是 Unix Bourne shell 本质特性的一个简化实现。
xv6 shell 的实现可以在(7850)处找到。(该链接指向 https://github.com/mit-pdos/xv6-riscv/ 中相关的 xv6 源代码,而数字指的是 xv6-src-booklet.pdf 中的页码和行号,类似于《UNIX 第六版注释》(Lions’ Commentary)中的引用方式。)一个良好的学习方法是先自行阅读源代码(在你喜欢的开发环境、GitHub 或 PDF 阅读器中),然后再回到本书中。到本书结束时,你应该能够在不借助本书的情况下理解 xv6 的每一行源代码。
一个 xv6 进程由用户态内存(指令、数据和栈)以及内核私有的、与该进程相关的状态组成。xv6 对进程进行时间共享:它在等待运行的一组进程之间透明地切换可用的 CPU。当一个进程未在运行时,xv6 会保存该进程的 CPU 寄存器状态,并在下次运行该进程时恢复这些寄存器。内核为每个进程分配一个进程标识符(process identifier,PID)。
一个进程可以通过系统调用 fork 创建一个新的进程。fork 会为新进程创建调用进程内存的一个完整副本:包括指令、数据和栈。fork 在父进程和子进程中都会返回。在父进程中,fork 返回新创建子进程的 PID;在子进程中,fork 返回 0。原进程和新进程通常分别称为父进程和子进程。
例如,考虑下面这段用 C 语言编写的程序片段:
int pid = fork();
if(pid > 0){
printf("parent: child=%d\n", pid);
pid = wait((int *) 0);
printf("child %d is done\n", pid);
} else if(pid == 0){
printf("child: exiting\n");
exit(0);
} else {
printf("fork error\n");
}
exit 系统调用使调用进程终止执行,并释放诸如内存和打开文件等资源。exit 接受一个整数作为状态参数,通常约定 0 表示成功,1 表示失败。wait 系统调用返回一个已经退出(或被杀死)的子进程的 PID,并将该子进程的退出状态复制到传入的地址中;如果调用进程的子进程都尚未退出,wait 会阻塞等待;如果调用进程没有任何子进程,wait 会立即返回 −1。若父进程不关心子进程的退出状态,可以向 wait 传递一个空指针(0)。
在上述示例中,输出结果:
parent: child=1234
child: exiting
可能以任意顺序出现(甚至交错出现),这取决于父进程和子进程中谁先执行到 printf。在子进程退出之后,父进程中的 wait 返回,从而打印出:
parent: child 1234 is done
尽管子进程最初拥有父进程内存的一个副本,但父子进程在执行时拥有彼此独立的内存和寄存器;在一个进程中修改变量不会影响另一个进程。例如,当父进程将 wait 的返回值赋给变量 pid 时,并不会改变子进程中的 pid,子进程中的该变量仍然为 0。
exec 系统调用会用从文件系统中加载的新内存映像替换当前进程的内存。该文件必须具有特定格式,用于说明哪些部分是指令、哪些是数据,以及从哪条指令开始执行。xv6 使用 ELF 格式,第三章将对此进行更详细的讨论。通常,该文件是由程序源代码编译生成的。当 exec 成功时,它不会返回到调用程序,而是从 ELF 头中指定的入口点开始执行新程序的指令。
exec 接受两个参数:可执行文件的路径名,以及一个字符串参数数组。例如:
char *argv[3];
argv[0] = "echo";
argv[1] = "hello";
argv[2] = 0;
exec("/bin/echo", argv);
printf("exec error\n");
这段代码会用 /bin/echo 程序替换当前进程,并以参数列表 echo hello 运行。大多数程序会忽略参数数组的第一个元素,该元素按照约定是程序名。
xv6 的 shell 使用上述系统调用来代表用户运行程序。shell 的整体结构非常简单;其主函数见(8001)。主循环通过 getcmd 从用户读取一行输入,然后调用 fork 创建一个 shell 进程的副本。父进程调用 wait,而子进程执行命令。例如,当用户在 shell 中输入 echo hello 时,runcmd 会以字符串 "echo hello" 作为参数被调用。runcmd(7903)执行实际的命令;对于 echo hello,它会调用 exec(7927)。如果 exec 成功,子进程将开始执行 echo 程序的指令,而不再返回到 runcmd。在某个时刻,echo 会调用 exit,从而使父进程在 main(8001)中的 wait 返回。
你可能会疑惑,为什么 fork 和 exec 不合并为一个系统调用。后文将说明,shell 正是利用二者分离的特性来实现输入输出重定向。为了避免“先复制进程、再立即用 exec 替换”的低效行为,操作系统在实现 fork 时通常会使用诸如写时复制(copy-on-write,见第 5 章)之类的虚拟内存技术进行优化。
xv6 会隐式地为用户空间分配大多数内存:fork 为子进程分配其父进程内存的副本,而 exec 分配足以容纳可执行文件的内存。如果进程在运行期间需要更多内存(例如用于 malloc),可以调用 sbrk(n) 将其数据段增长 n 个字节;sbrk 返回新分配内存的起始地址。
文件描述符(file descriptor)是一个小整数,用于表示内核所管理的、进程可以进行读写操作的对象。进程可以通过打开文件、目录或设备,创建管道,或者复制已有的文件描述符来获得文件描述符。为简化表述,我们通常将文件描述符所指向的对象统称为“文件”;文件描述符接口屏蔽了文件、管道和设备之间的差异,使它们在使用上都表现为字节流。我们将输入与输出统称为 I/O。
在内部实现上,xv6 内核将文件描述符作为索引,指向每个进程私有的一张文件描述符表。因此,每个进程都有从 0 开始的一组独立的文件描述符。按照约定,进程从文件描述符 0 读取输入(标准输入),向文件描述符 1 写输出(标准输出),并向文件描述符 2 写错误信息(标准错误)。正如后文将看到的,shell 正是利用这一约定来实现 I/O 重定向和管道。shell 保证在启动时始终打开三个文件描述符(8007),默认指向控制台。
read 和 write 系统调用分别用于从文件描述符读取数据和向其写入数据。
read(fd, buf, n) 从文件描述符 fd 中最多读取 n 个字节,复制到 buf 中,并返回实际读取的字节数。每个指向文件的文件描述符都关联一个文件偏移量(offset)。read 从当前偏移量开始读取数据,然后将偏移量向前移动相应的字节数;下一次 read 将从新的位置继续读取。当没有更多数据可读时,read 返回 0,表示文件结束。
write(fd, buf, n) 向文件描述符 fd 写入 n 个字节,并返回成功写入的字节数。只有在发生错误时,写入的字节数才可能小于 n。与 read 类似,write 也从当前文件偏移量开始写入,并在写入后推进偏移量。
下面这段程序(即 cat 程序的核心部分)将标准输入中的数据复制到标准输出。如果发生错误,则向标准错误输出信息:
char buf[512];
int n;
for(;;){
n = read(0, buf, sizeof buf);
if(n == 0)
break;
if(n < 0){
fprintf(2, "read error\n");
exit(1);
}
if(write(1, buf, n) != n){
fprintf(2, "write error\n");
exit(1);
}
}
需要注意的是,这段代码并不知道它是从文件、终端还是管道中读取数据;同样,它也不知道输出是写到终端、文件还是其他地方。文件描述符的抽象以及“0 为输入、1 为输出”的约定,使得 cat 的实现极为简单。
close 系统调用用于释放一个文件描述符,使其可被后续的 open、pipe 或 dup 调用重新使用。新分配的文件描述符总是当前进程中编号最小的未使用描述符。
文件描述符与 fork 的配合使得 I/O 重定向的实现非常简单。fork 会复制父进程的文件描述符表,因此子进程最初拥有与父进程完全相同的打开文件。exec 会替换进程的内存映像,但会保留其文件描述符表。正因为如此,shell 才能通过如下步骤实现 I/O 重定向:先 fork,在子进程中关闭并重新打开某些文件描述符,然后调用 exec 运行新程序。下面是一个简化的例子,对应命令 cat < input.txt:
char *argv[2];
argv[0] = "cat";
argv[1] = 0;
if(fork() == 0) {
close(0);
open("input.txt", O_RDONLY);
exec("cat", argv);
}
当子进程关闭文件描述符 0 后,open 一定会使用编号最小的可用描述符,也就是 0。因此,此时标准输入被重定向为 input.txt。父进程的文件描述符不会受到影响,因为这些修改只发生在子进程中。
xv6 shell 中用于实现 I/O 重定向的代码正是基于这一机制(见 7931)。此时 shell 已经 fork 出子进程,而 runcmd 将调用 exec 来加载新程序。
open 的第二个参数是一组标志位,用于控制打开方式,这些标志在头文件 fcntl(4000–4004)中定义,包括 O_RDONLY、O_WRONLY、O_RDWR、O_CREATE 和 O_TRUNC,分别表示只读、只写、读写、若不存在则创建文件、以及将文件截断为零长度。
现在可以清楚地看出,fork 与 exec 分离是非常有价值的:在二者之间,shell 可以在不影响自身 I/O 设置的情况下,对子进程的 I/O 进行重定向。如果将二者合并为一个假想的 forkexec 系统调用,那么实现 I/O 重定向将会变得非常笨拙:要么 shell 先修改自己的 I/O 再恢复,要么 forkexec 接收复杂的重定向参数,要么每个程序(如 cat)都要自己实现 I/O 重定向逻辑。
尽管 fork 会复制文件描述符表,但父子进程共享同一个底层文件偏移量。考虑以下示例:
if(fork() == 0) {
write(1, "hello ", 6);
exit(0);
} else {
wait(0);
write(1, "world\n", 6);
}
执行完后,文件描述符 1 所指向的文件中将包含:
hello world
父进程的 write(由于 wait 的存在,在子进程结束后执行)会从子进程写入结束的位置继续写。这种行为使得诸如 (echo hello; echo world) > output.txt 这样的顺序输出成为可能。
dup 系统调用用于复制一个已有的文件描述符,返回一个指向同一底层 I/O 对象的新描述符。两个描述符共享同一个文件偏移量,正如通过 fork 复制得到的一样。下面是另一种写入 “hello world” 的方式:
fd = dup(1);
write(1, "hello ", 6);
write(fd, "world\n", 6);
如果两个文件描述符是通过一系列 fork 和 dup 操作从同一个原始描述符派生出来的,那么它们共享同一个偏移量;否则,即使它们是通过对同一个文件调用 open 得到的,也不会共享偏移量。
dup 使得 shell 能够实现如下命令:
ls existing-file non-existing-file > tmp1 2>&1
其中 2>&1 表示让文件描述符 2(标准错误)成为文件描述符 1(标准输出)的一个副本。这样,正确输出和错误信息都会被写入 tmp1。xv6 的 shell 并未实现错误输出的重定向,但你现在已经知道如何实现它了。
文件描述符是一种强大的抽象机制,因为它隐藏了底层连接对象的细节:一个进程向文件描述符 1 写数据时,它可能是在向文件、终端设备,或者管道写入数据。
管道是一种由内核维护的小型缓冲区,它以一对文件描述符的形式暴露给进程:一个用于读取,一个用于写入。向管道的一端写入数据,就可以从另一端读出这些数据。管道为进程之间的通信提供了一种机制。
下面的示例代码运行程序 wc,并将其标准输入连接到一个管道的读端:
int p[2];
char *argv[2];
argv[0] = "wc";
argv[1] = 0;
pipe(p);
if(fork() == 0) {
close(0);
dup(p[0]);
close(p[0]);
close(p[1]);
exec("/bin/wc", argv);
} else {
close(p[0]);
write(p[1], "hello world\n", 12);
close(p[1]);
}
该程序首先调用 pipe,创建一个新的管道,并将读端和写端的文件描述符分别存放在数组 p 中。fork 之后,父子进程都持有指向该管道的文件描述符。
子进程通过 close 和 dup 将文件描述符 0(标准输入)指向管道的读端,然后关闭数组 p 中的两个描述符,并调用 exec 执行 wc。此后,wc 从标准输入读取数据时,实际上是从管道中读取。
父进程关闭管道的读端,向写端写入数据,然后关闭写端。
当管道中没有数据可读时,read 会阻塞,直到有数据写入,或者直到所有指向该管道写端的文件描述符都被关闭;在后一种情况下,read 会返回 0,就像到达文件结尾一样。正因为如此,在上述示例中,子进程在执行 wc 之前必须关闭写端:如果 wc 的某个文件描述符仍然指向管道的写端,那么 wc 将永远无法看到文件结束标志。
xv6 的 shell 以类似方式实现了诸如 grep fork sh.c | wc -l 这样的管道(见 7950)。子进程创建一个管道,用于连接管道左侧和右侧的命令。然后它分别对左右两端调用 fork 和 runcmd,并等待两者完成。管道右端的命令本身也可能包含管道(例如 a | b | c),此时它会再次派生出两个子进程(一个用于 b,一个用于 c)。因此,shell 最终会构建出一棵进程树:叶节点是实际执行命令的进程,而内部节点则是等待其左右子进程结束的进程。
乍看之下,管道似乎并不比临时文件更强大。例如,命令:
echo hello world | wc
也可以通过下面的方式实现:
echo hello world > /tmp/xyz; wc < /tmp/xyz
然而,在这种场景下,管道至少有三个显著优势:
/tmp/xyz。因此,管道是 Unix 系统中实现进程间通信和高效组合程序的重要机制。
xv6 的文件系统提供两类对象:数据文件(包含未解释的字节数组)以及目录(包含指向数据文件或其他目录的命名引用)。目录组织成一棵树,根节点是一个称为根目录(root)的特殊目录。路径名如 /a/b/c 表示位于根目录 / 下的目录 a 中的目录 b 里的文件或目录 c。
不以 / 开头的路径是相对路径,其解析基于调用进程的当前工作目录。当前工作目录可以通过 chdir 系统调用进行修改。下面两个代码片段打开的是同一个文件(假设相关目录都已存在):
chdir("/a");
chdir("b");
open("c", O_RDONLY);
open("/a/b/c", O_RDONLY);
第一个片段将进程的当前目录改为 /a/b;第二个片段既不依赖也不改变当前工作目录。
系统调用提供了创建新文件和目录的能力:mkdir 创建新目录,带有 O_CREATE 标志的 open 创建新数据文件,而 mknod 创建一个新的设备文件。下面的示例展示了这三种操作:
mkdir("/dir");
fd = open("/dir/file", O_CREATE|O_WRONLY);
close(fd);
mknod("/console", 1, 1);
mknod 创建一个指向设备的特殊文件。设备文件关联着主设备号和次设备号(即传给 mknod 的两个整数参数),它们唯一标识一个内核设备。当进程之后打开该设备文件时,内核会将 read 和 write 系统调用转发给相应的设备实现,而不是普通文件系统。
文件名与文件本身是相互独立的概念;同一个底层文件(称为 inode)可以拥有多个名字(称为链接,link)。每个链接都是目录中的一个条目,包含一个文件名和一个指向 inode 的引用。inode 中保存了文件的元数据,包括文件类型(普通文件、目录或设备)、文件长度、文件内容在磁盘中的位置,以及指向该文件的链接数量。
fstat 系统调用用于获取文件描述符所指向 inode 的信息。它会将信息填充到一个 stat 结构体中,该结构体在 stat.h(4050)中定义如下:
#define T_DIR 1 // 目录
#define T_FILE 2 // 文件
#define T_DEVICE 3 // 设备
struct stat {
int dev; // 文件系统所在的磁盘设备
uint ino; // inode 号
short type; // 文件类型
short nlink; // 指向该文件的链接数量
uint64 size; // 文件大小(字节)
};
link 系统调用创建一个新的文件名,使其指向与现有文件相同的 inode。下面的代码创建了两个名字 a 和 b,它们指向同一个文件:
open("a", O_CREATE|O_WRONLY);
link("a", "b");
对 a 或 b 的读写效果完全相同。每个 inode 都有一个唯一的 inode 号。在上述代码执行后,可以通过 fstat 发现,a 和 b 返回相同的 inode 编号(ino),并且其链接计数 nlink 为 2。
unlink 系统调用从文件系统中删除一个名字。当文件的链接计数降为 0 且没有任何文件描述符仍指向该文件时,文件的 inode 及其占用的磁盘空间才会被释放。因此,在前面的示例中加入:
unlink("a");
将只移除名字 a,文件本身仍然可以通过 b 访问。此外:
fd = open("/tmp/xyz", O_CREATE|O_RDWR);
unlink("/tmp/xyz");
是一种常见用法,用于创建一个没有名字的临时文件;当进程关闭 fd 或退出时,该文件会被自动清理。
Unix 将文件操作工具(如 mkdir、ln、rm)作为用户态程序提供,而不是内置在内核中。这种设计使得任何人都可以通过添加用户程序来扩展命令行接口。事后看来这是一个非常优雅的设计选择,但在 Unix 诞生的年代,许多系统将这些功能直接内建在 shell 或内核中。
一个重要的例外是 cd 命令,它必须由 shell 自身实现(见 8021)。原因在于 cd 需要改变 shell 进程自身的当前工作目录。如果 cd 是一个普通程序,那么 shell 会先 fork 一个子进程,再由子进程执行 cd;这样改变的只会是子进程的工作目录,而不会影响父进程(即 shell 本身)。
Unix 将“标准”文件描述符、管道以及对其进行操作的简洁 shell 语法结合在一起,这在编写通用、可复用程序方面是一项重大进步。这一思想催生了“软件工具(software tools)”文化,也正是这种文化推动了 Unix 的强大与流行;而 shell 则成为最早的“脚本语言”。Unix 的系统调用接口至今仍在使用,例如在 BSD、Linux 和 macOS 等系统中。
Unix 的系统调用接口后来通过 POSIX(可移植操作系统接口,Portable Operating System Interface)标准得到了规范化。xv6 并不符合 POSIX 标准:它缺少许多系统调用(甚至包括一些基础的调用,如 lseek),并且其所提供的部分系统调用在语义上也与标准有所不同。xv6 的主要目标是简洁与清晰,同时提供一个具有 Unix 风格的系统调用接口。有人在 xv6 的基础上扩展了一些系统调用,并添加了一个简单的 C 库,使其能够运行基本的 Unix 程序。然而,现代操作系统提供的系统调用和内核服务要丰富得多,例如网络支持、窗口系统、用户级线程、多种设备驱动等。现代内核持续快速演进,其功能早已超越 POSIX 所定义的范围。
Unix 用统一的文件名和文件描述符接口来访问多种资源(文件、目录、设备),这一设计极具影响力。该思想还可以扩展到更多类型的资源;一个典型例子是 Plan 9,它将“万物皆文件”的理念扩展到了网络、图形等领域。然而,大多数 Unix 衍生系统并未完全沿着这一路线发展。
文件系统和文件描述符是一种非常强大的抽象方式。尽管如此,操作系统接口仍然存在其他设计模型。Unix 的前身 Multics 采用了另一种抽象方式:它将文件存储抽象得类似于内存,从而形成了截然不同的接口风格。Multics 设计的复杂性直接影响了 Unix 的设计者,使他们有意构建一个更加简洁的系统。
xv6 并未提供用户或用户隔离的概念;用 Unix 的术语来说,xv6 中的所有进程都以 root 身份运行。
本书通过 xv6 来讲解类 Unix 接口的实现方式,但这些思想并不仅适用于 Unix。任何操作系统都必须在底层硬件之上实现进程复用、进程隔离,以及受控的进程间通信机制。在学习完 xv6 之后,你应当能够在其他更复杂的操作系统中识别出这些相同的核心思想。