引言
本文是How Uber Serves Over 40 Million Reads Per Second from Online Storage Using an Integrated CacheBlog的阅读记录。
问题
微服务使用磁盘存储数据库来持久化数据。当吞吐量很高时在保证低延时读取&高扩展面临挑战。
Docstore使用NVMe SSD支持,提供低延迟高吞吐,但成本高昂。
Docstore架构
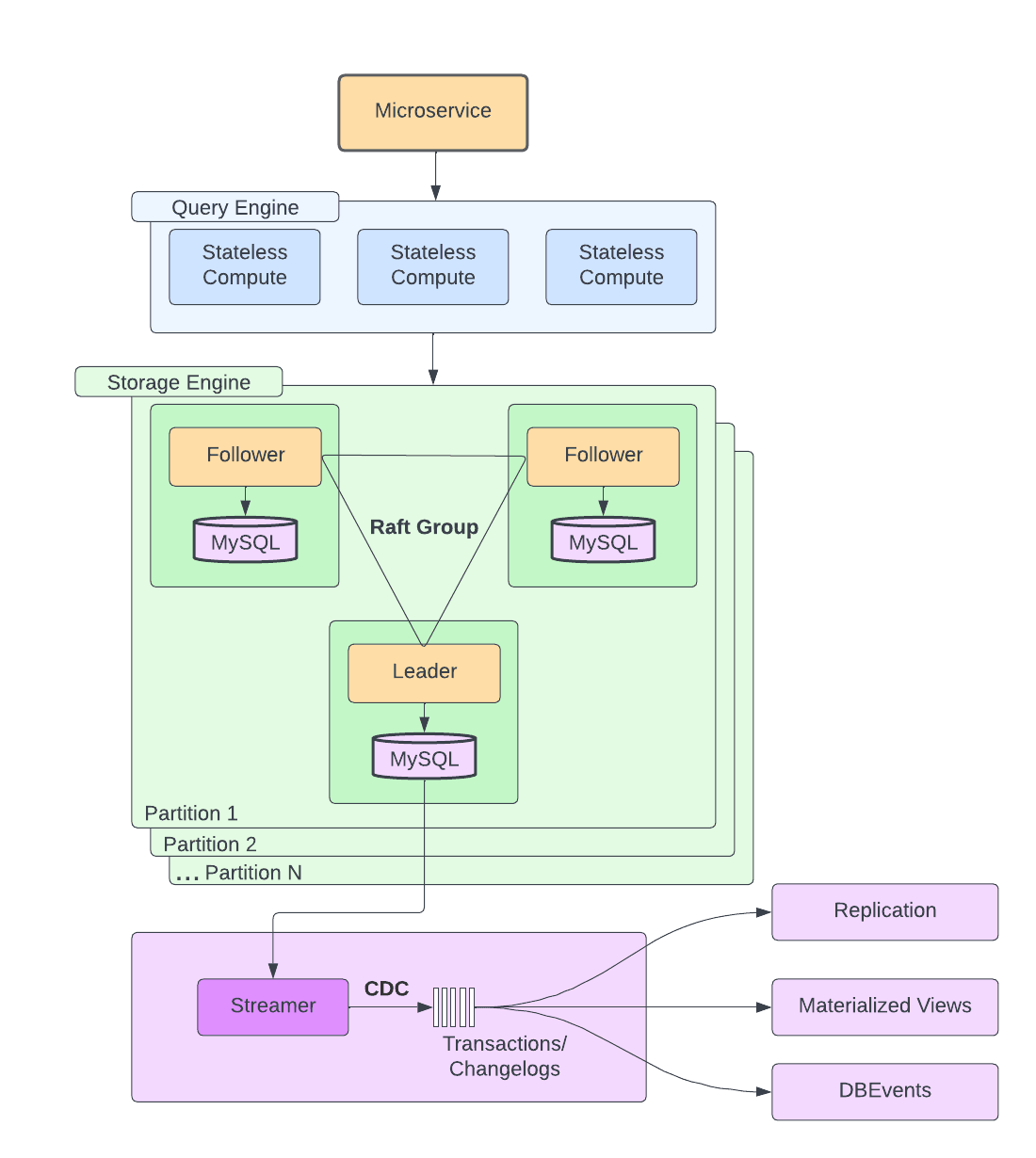
主要分为三层
- 无状态查询引擎:查询规划,路由,分片,模式管理,健康监控,请求解析,身份验证/授权
- 有状态存储引擎:基于Raft实现一致性,复制,事务,并发控制,负载管理。一个分片由支持NVMe SSD的MySQL节点组成,处理高读高写负载。每个分片包含一个主节点两个从节点。
- 控制平面
NVMe SSD:基于Non-Volatile Memory Expressx协议的固态硬盘。传统SSD采用SATA接口,最初为HDD设计,带宽上限低。NVMe SSD通过总线直接与CPU通信,去除SATA层显示,带宽大幅增加。
问题探究
挑战
高规模下低延迟读取面临挑战:
- 从磁盘读取速度有一个阈值,查询优化程度是有限的。
- 垂直扩展有局限性,尤其是当数据库引擎本身成为瓶颈。
- 水平扩展复杂且耗时,必须保证持久性和弹性,且不能有停机时间,也无法解决热点key/分区/分片的问题。
- 请求不平衡,读比写高出几个数量级。
- 成本昂贵。
缓存
解决上述问题,我们需要缓存,但缓存本身有以下挑战:
- 每个团队都要配置和维护自己的Redis缓存。
- 缓存失效在每个微服务中的实现是去中心化的(即不是集中实现的)。
- 在区域故障转移的情况下,服务要么维护缓存以保持热状态,要么缓存在其他区域预热时承受高延迟
对于第三点我详细说明一下:
- Uber这样的系统通常在多个地区(Region)部署。
- 如果一个区域宕机(failover),流量会切换到另一个区域。
- 问题缓存是区域本地的,切换新区域时:
- 方案A:跨区域缓存复制,让其他区域的缓存也提前保持热状态(增加复杂度&带宽成本)。
- 方案B:不复制,新的区域缓存是冷的,需要重新加载(延迟升高)。
解决方案
为解决问题,Uber构建集成式缓存解决方案CacheFront。
目标如下:
- Minimize the need for vertical and/or horizontal scaling to support low-latency read requests
最小化垂直和/或水平扩展的需求,以支持低延迟读取请求
- Reduce resource allocation to the database engine layer; caching can be built from relatively cheap hosts, so overall cost efficiency is improved
减少分配给数据库引擎层的资源;缓存可以由相对廉价的宿主机构建,从而提高整体成本效率
- Improve P50 and P99 latencies, and stabilize read latency spikes during microbursts
改善 P50 和 P99 延迟,并在微爆发期间稳定读取延迟峰值
- Replace most of the custom-built caching solutions that were (or will be) built by the individual teams to answer their needs, especially in the cases where the caching is not the core business or competency of the team
替换掉大多数由各个团队(或将要)为满足自身需求而构建的自定义缓存解决方案,特别是在缓存并非团队核心业务或专长的情况下
- Make it transparent by reusing existing Docstore client without any additional boilerplate to allow benefiting from caching
通过重用现有的 Docstore 客户端,无需任何额外的模板代码,使其透明化,从而能够受益于缓存
- Increase developer productivity and allow us to release new features or replace the underlying caching technology transparently to customers
提升开发者生产力,使我们能够透明地向客户发布新功能或替换底层缓存技术
- Detach caching solution from Docstore’s underlying sharding scheme to avoid problems that arise from hot keys, shards, or partitions
将缓存解决方案与 Docstore 的底层分片方案分离,以避免因热键、分片或分区产生的问题
- Allow us to horizontally scale out caching layer, independently of the storage engine
允许我们独立于存储引擎横向扩展缓存层
- Move ownership for maintaining and on calling Redis from feature teams to the Docstore team
将维护和调用 Redis 的职责从功能团队转移到 Docstore 团队
一句话总结:
Docstore 团队负责维护,从而提升整体效率与开发生产力。
设计
查询模式
支持通过主键/分区键查询,可选择性过滤数据。
| Key-type / Filter |
No Filter |
Filter by WHERE clause |
| Rows |
ReadRows |
– |
| Partitions |
ReadPartition |
QueryRows |
研究发现大于50%的查询都是ReadRows,于是作为起点。
高层架构
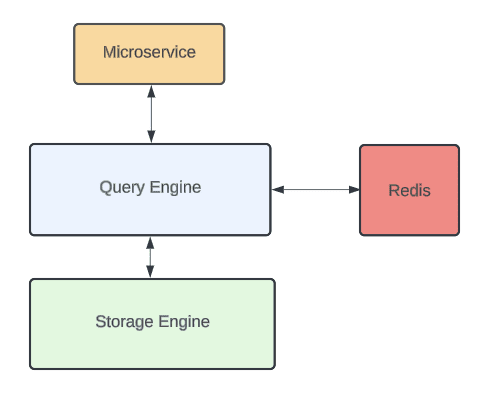
- Docstore的查询引擎为对外的入口,负责处理R/W。
- 缓存(CacheFront)集成在查询引擎中。
- 查修引擎同时提供使缓存条目失效的机制。
- Docstore是强一致性数据库,集成缓存时有些一致性方面语义可能每个服务来说不可接受(e.g. 缓存失效可能失败/落后数据库写入),所以集成缓存为可选的功能。
- 服务可以在库/表/请求级别配置缓存使用。
- 强一致性流程可绕过缓存。
- 其他写吞吐低的流程则可以从缓存获益。
缓存读取
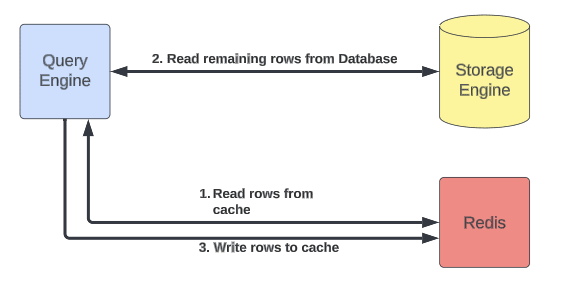
使用了旁路缓存策略(Cache Aside):
- Query engine layer gets read request for one more rows
查询引擎层获取更多行的读取请求
- If caching is enabled, try getting rows from Redis; stream response to users
如果启用缓存,尝试从 Redis 获取行;将响应流式传输给用户
- Retrieve remaining rows (if any) from the storage engine
从存储引擎检索剩余行(如有)
- Asynchronously populate Redis with the remaining rows
异步填充 Redis 中的剩余行
- Stream remaining rows to users
将剩余行流式传输给用户
常见缓存策略
这里插一嘴有哪些缓存策略:
-
Cache-Aside:
- 读:先查缓存,如果没有,再查DB,并把结果写入缓存。
- 写:通常直接更新DB,然后删除缓存旧数据。
-
Write-Through:
-
Write-Back:
- 写:先写缓存,再异步批量写DB。
- 读:直接查缓存。
-
Read-Through:
- 应用只查缓存,如果没命中,缓存组件自己去查DB,并将结果填充。
缓存失效
“There are only two hard things in Computer Science: cache invalidation and naming things.”
-- Phil Karlton
如果没有显式的机制,缓存TTL为5分钟,但大多数用户期望TTL更快;如果降低默认TTL也会降低缓存命中率且不会显著改善一致性保证。
条件更新
虽然Docstore支持条件更新(即根据过滤条件更新一/多行),但是缓存无法在引擎实际更新前确定哪些会被更新,且查询引擎无状态,所以无法在写入时准确失效&回填。
变更数据捕获
为解决上述问题,使用了Docstore变更数据捕获和流服务Flux。Flux跟踪每个集群的MySQL binlog事件,并将事件发布到一组消费者。
Flux为Docstore CDC(Change Data Capture),复制,物化视图,数据胡摄取,集群节点中验证数据一致性提供支持。
这里对提到的功能进行解释
- CDC:捕获DB中的插/更/删事件,并转换为流式消息,用于微服务订阅变更或者下游系统实时分析。
- 复制:MySQL复制就是基于binlog:主写,binlog记录,备重放事件。
- 物化视图(Materialized View):提前将复杂查询结果计算好,存为结果表,提高查询性能。
- 数据湖摄取(Data Lake Ingestion):将数据流式同步到数据湖用于离线分析/ML。
- 一致性验证:检查不同副本/分片间数据是否一致。每个节点都应用同样的binlog数据流,理论上状态应该一致。
Uber编写一个新消费者,订阅事件,并在Redis中使新行失效/插入新行,因此能在变更后几秒内保持缓存一致,并且通过binlog也避免了未提交事务污染缓存的风险。
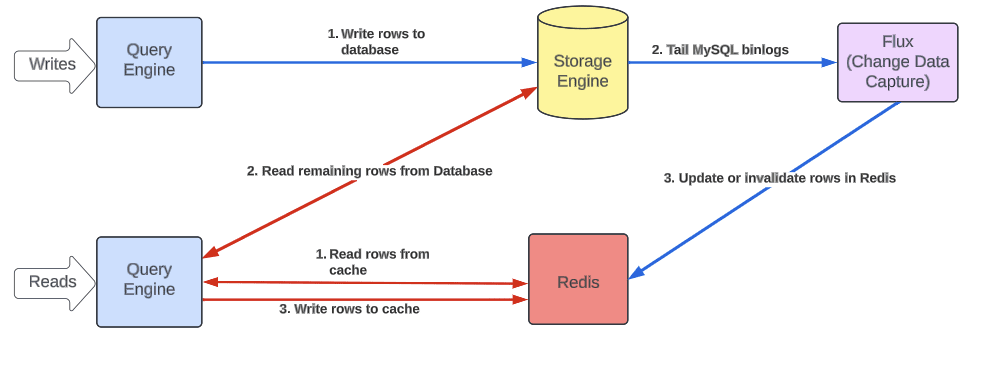
写入重复
上述策略中,读路径和写路径在缓存中同时发生写入,可能会将过时数据写入缓存。
通过MySQL设置的行时间戳进行操作去重,时间戳充当了版本号。
时间戳是从Redis编码的行值中解析出来的(见下文)。
Redis支持使用EVAL原子方式执行Lua脚本,其中包含去重逻辑。
更强一致性
Flux还是最终一致性。如果需要更强的一致性(e.g.读取自己写入的内容),查询引擎中提供API,允许用户写入完成后显式失效缓存(仅限点写,对于条件更新仍需要Flux)。
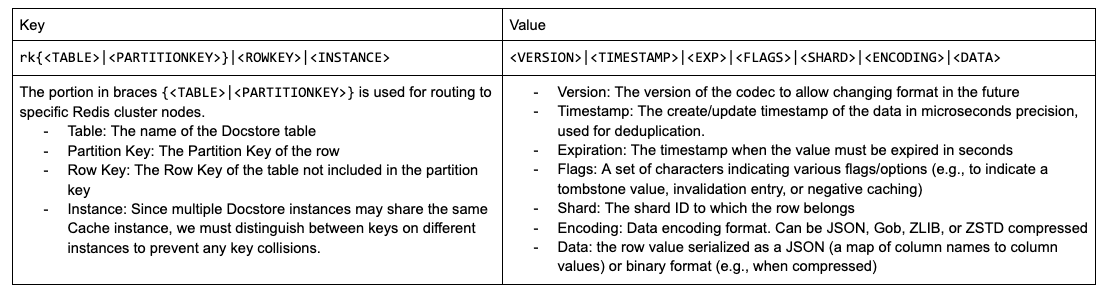
表结构
Docstore具有主键和分区键。
- 主键唯一标识一行,每张表必须有一个。
- 分区键是整个主键的前缀,决定了行放在哪个分片。
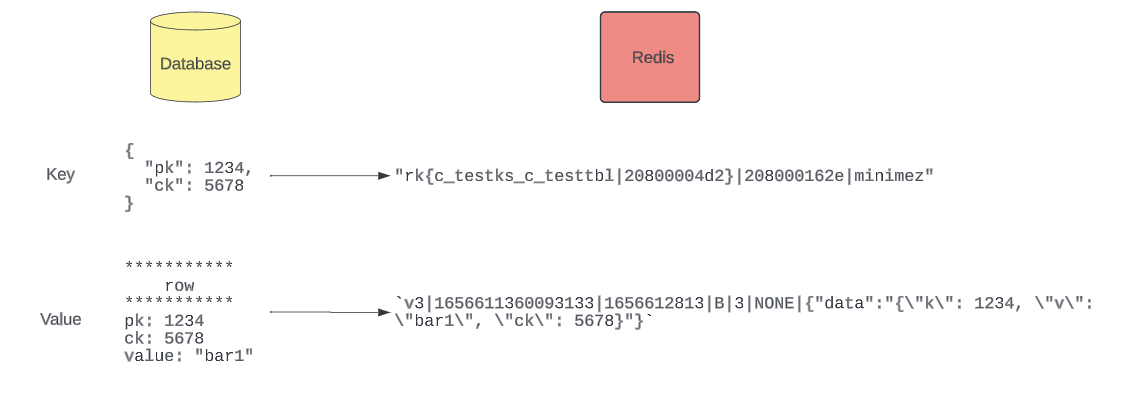
Redis Codec(编码器)
如图所示:
特性
高层设计后考虑扩展&容错性:
- 如何验证DB缓存一致性
- 如何容忍zone/region故障
- 如何容忍Redis故障
比较缓存
增加特殊模式,在重新读取时比较缓存和DB数据并验证是否相同,验证缓存一致性达到99.99%。
缓存预热
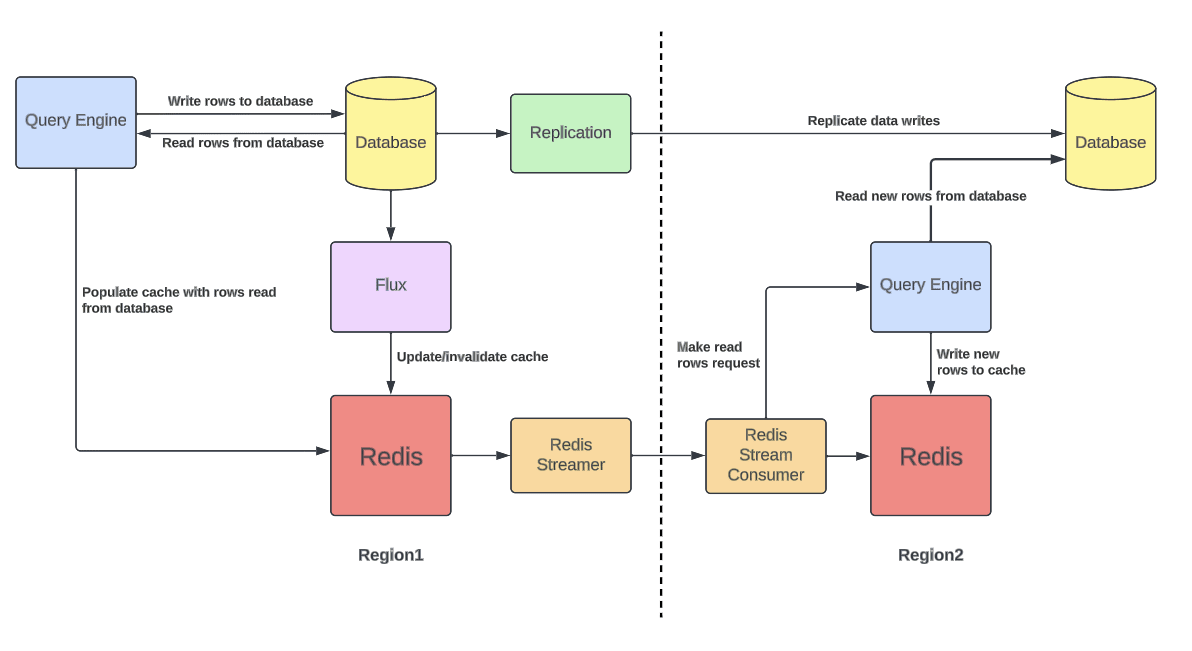
一个Docstore实例会生成两个不同的地理区域保证高可用&容错。部署是主动-主动模式,代表任何请求可以在任何区域发出&响应。所有写入操作都会跨区域复制。故障切换时另一个区域必须能服务所有请求。
这也导致缓存必须在所有区域保持活跃状态,否则故障转移时负载会大幅增高。此问题可以通过跨区域Redis复制解决,但是因为Docstore已有自己的复制机制,这样就会有两个独立的复制机制,导致缓存不一致。
解决方式是增加一种新的缓存预热模式。监控Redis写入流并复制key到远程区域。远程区域不会直接更新缓存,而是向查询引擎发起读取请求,如果未命中,会从DB拉取并写入缓存。
通过复制key而非value,始终确保缓存中的数据与其所在区域的DB保持一致,并降低了跨区域带宽使用。
负缓存
集成负缓存功能,跟踪查询过但未从数据库读取的行,将这些不存在的行带有特殊标记写入缓存。在未来读取中如果发现该标记,会忽略数据库查询中的该行,且不会向用户返回数据。
分片
虽然Redis受热分区问题影响不大,但是一些大客户会产生大量请求,在单个集群中难以缓存(节点数量上有限制),所以单个DEocstore实例会映射到多个Redis集群。
即使数据分散在多个集群,单个集群宕机也可能在数据库创建热点分片问题,所以决定按分区键对集群进行分片。当单个Redis集群宕机时,可避免单个数据库分片过载。来自宕机Redis分片的所有请求将被分配到所有数据库分片中。
Redis的分片和数据库不一样,所以单个Redis分片宕机请求不会集中到同一个shard。
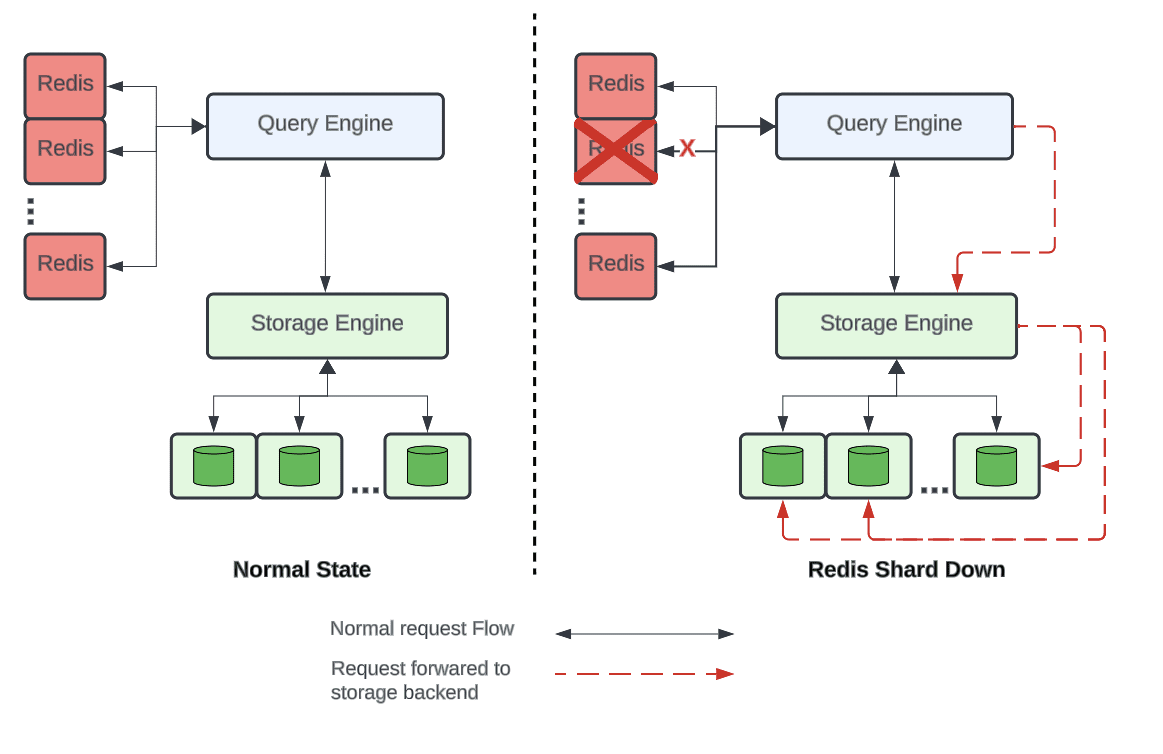
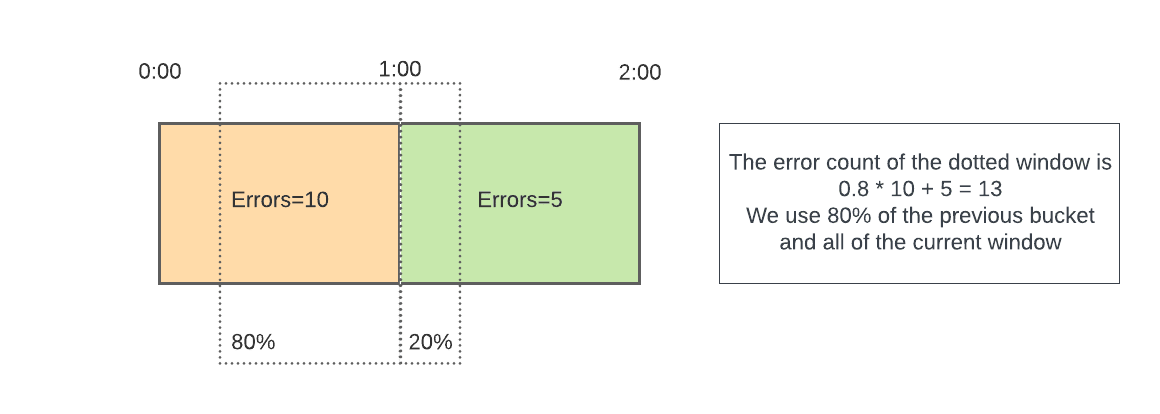
断路器
如果Redis节点宕机,希望能够绕过该节点请求以降低延迟,所以使用滑动窗口断路器,按时间桶统计每个节点的错误数量,并计算滑动窗口内错误数量。一旦达到最大允许错误计数,就会跳闸,直到滑动窗口通过之前,不再向该节点发送更多请求。
自适应超时
很难为Redis操作设置超时时间,过短会导致过早失败浪费资源增加负载,而过长会影响P99.9,P99.99的延迟。
设计自动动态调整请求超时时间,以确保Redis请求的P99值在分配超时时间内成功,同时减少长尾延迟。设置一个等于缓存请求P99.99延迟的超时时间,从而让99.99%的请求可以快速响应获取,而剩下的可以更快的取消从DB获取服务。
之后不再需要手动调整超时,只需设置可接受的最大超时限制。