OpenHands:面向 AI 软件开发者的通用代理开放平台
发布于 • 作者: Xingyao Wang et al.
本文是OpenHands: An Open Platform for AI Software Developers as Generalist Agents的原文&译文。
Software is one of the most powerful tools that we humans have at our disposal; it allows a skilled programmer to interact with the world in complex and profound ways. At the same time, thanks to improvements in large language models (LLMs), there has also been a rapid development in AI agents that interact with and affect change in their surrounding environments. In this paper, we introduce OpenHands (f.k.a. OpenDevin), a platform for the development of powerful and flexible AI agents that interact with the world in similar ways to those of a human developer: by writing code, interacting with a command line, and browsing the web. We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks. Based on our currently incorporated benchmarks, we perform an evaluation of agents over 15 challenging tasks, including software engineering (e.g., Swe-bench) and web browsing (e.g., WebArena), among others. Released under the permissive MIT license, OpenHands is a community project spanning academia and industry with more than 2.1K contributions from over 188 contributors.
软件是人类最强大的工具之一;它使熟练的程序员能够以复杂而深刻的方式与世界互动。同时,由于大型语言模型(LLMs)的改进,与周围环境互动并产生影响变化的 AI 代理也迅速发展。在本文中,我们介绍了 OpenHands(又名 OpenDevin),一个用于开发强大且灵活的 AI 代理的平台,这些代理与世界互动的方式类似于人类开发者:通过编写代码、与命令行交互以及浏览网页。我们描述了该平台如何实现新代理、在代码执行沙盒环境中进行安全交互、多个代理之间的协调以及评估基准的整合。基于我们目前整合的基准,我们对 15 项具有挑战性的任务中的代理进行了评估,包括软件工程(例如 Swe-bench)和网页浏览(例如 WebArena)等。在宽松的 MIT 许可证下发布的 OpenHands 是一个跨越学术界和工业界的社区项目,拥有超过 2.1K 贡献来自 188 位以上贡献者。
Powered by large language models (LLMs; OpenAI 2024b; Team et al. 2023; Jiang et al. 2024; Chang et al. 2024), user-facing AI systems (such as ChatGPT) have become increasingly capable of performing complex tasks such as accurately responding to user queries, solving math problems, and generating code. In particular, AI agents, systems that can perceive and act upon the external environment, have recently received ever-increasing research focus. They are moving towards performing complex tasks such as developing software (Jimenez et al., 2024), navigating real-world websites (Zhou et al., 2023a), doing household chores (Ahn et al., 2022), or even performing scientific research (Boiko et al., 2023; Tang et al., 2024a).
由大型语言模型(LLMs;OpenAI 2024b;团队等 2023;姜等 2024;张等 2024)驱动,面向用户的人工智能系统(如 ChatGPT)在准确响应用户查询、解决数学问题和生成代码等复杂任务方面变得越来越强大。特别是,能够感知和对外部环境采取行动的人工智能代理,最近受到了越来越多的研究关注。它们正朝着开发软件(Jimenez 等,2024)、导航现实世界网站(Zhou 等,2023a)、做家务(Ahn 等,2022)甚至进行科学研究(Boiko 等,2023;Tang 等,2024a)等复杂任务的方向发展。
As AI agents become capable of tackling complex problems, their development and evaluation have also become challenging. There are numerous recent efforts in creating open-source frameworks that facilitate the development of agents (Hong et al., 2023; Chen et al., 2024; Wu et al., 2023). These agent frameworks generally include: 1) interfaces through which agents interact with the world (such as JSON-based function calls or code execution), 2) environments in which agents operate, and 3) interaction mechanisms for human-agent or agent-agent communication. These frameworks streamline and ease the development process in various ways (Tab. 1, §C).
随着 AI 代理能够处理复杂问题,其开发和评估也变得具有挑战性。近年来,出现了许多创建开源框架的努力,这些框架促进了代理的开发(Hong 等人,2023 年;Chen 等人,2024 年;Wu 等人,2023 年)。这些代理框架通常包括:1)代理与世界交互的接口(如基于 JSON 的函数调用或代码执行)、2)代理运行的环境,以及 3)人-代理或代理-代理通信的交互机制。这些框架以多种方式简化并减轻了开发过程(表 1,§C)。
When designing AI agents, we can also consider how human interacts with the world. The most powerful way in which humans currently interact with the world is through software – software powers every aspect of our life, supporting everything from the logistics for basic needs to the advancement of science, technology, and AI itself. Given the power of software, as well as the existing tooling around its efficient development, use, and deployment, it provides the ideal interface for AI agents to interact with the world in complex ways. However, building agents that can effectively develop software comes with its own unique challenges. How can we enable agents to effectively create and modify code in complex software systems? How can we provide them with tools to gather information on-the-fly to debug problems or gather task-requisite information? How can we ensure that development is safe and avoids negative side effects on the users’ systems?
在设计 AI 代理时,我们也可以考虑人类如何与世界互动。目前人类与世界互动最强大的方式是通过软件——软件驱动着我们生活的方方面面,从满足基本需求的物流到科学、技术和 AI 本身的进步。鉴于软件的强大功能,以及围绕其高效开发、使用和部署的现有工具,它为 AI 代理以复杂方式与世界互动提供了理想的接口。然而,构建能够有效开发软件的代理也带来了其独特的挑战。我们如何使代理能够有效创建和修改复杂软件系统中的代码?我们如何为他们提供工具,以便实时收集信息以调试问题或收集任务所需信息?我们如何确保开发过程安全,避免对用户系统产生负面影响?
In this paper, we introduce OpenHands (f.k.a. OpenDevin), a community-driven platform designed for the development of generalist and specialist AI agents that interact with the world through software.
在本文中,我们介绍了 OpenHands(曾用名 OpenDevin),这是一个由社区驱动的平台,旨在开发通用型和专业型 AI 代理,这些代理通过软件与世界互动。
It features:
它具有以下特点:
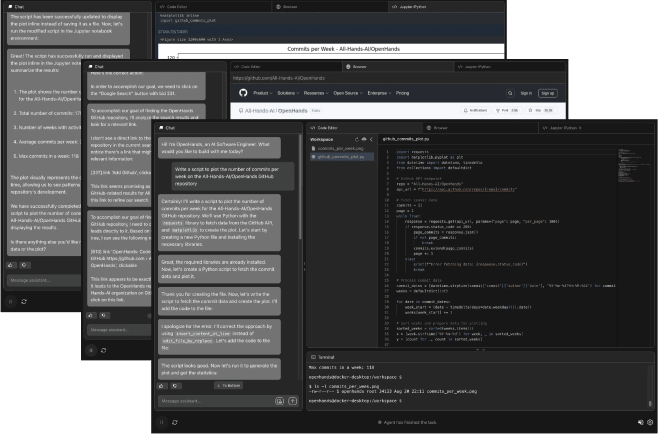
Figure 1: OpenHands User Interface (UI, §D) allows users to view files, check executed bash commands/Python code, observe the agent’s browser activity, and directly interact with the agent.
图 1:OpenHands 用户界面(UI,§D)允许用户查看文件、检查已执行的 bash 命令/Python 代码、观察代理的浏览器活动,并能直接与代理交互。
Importantly, OpenHands is not just a conceptual framework, but it also includes a comprehensive and immediately usable implementation of agents, environments, and evaluations. As of this writing, OpenHands includes an agent hub with over 10 implemented agents (§3), including a strong generalist agent implemented based on the CodeAct architecture (Wang et al., 2024a), with additions for web browsing (ServiceNow,) and code editing specialists (Yang et al., 2024). Interaction with users is implemented through a chat-based user interface that visualizes the agent’s current actions and allows for real-time feedback (Fig. 1, §D). Furthermore, the evaluation framework currently supports 15 benchmarks, which we use to evaluate our agents (§4).
重要的是,OpenHands 不仅是一个概念框架,还包括一个全面且立即可用的智能体、环境和评估实现。截至本文撰写时,OpenHands 包含一个拥有超过 10 个已实现智能体的智能体中心(§3),其中包括一个基于 CodeAct 架构实现的强大通用智能体(Wang 等人,2024a),并增加了网络浏览(ServiceNow)和代码编辑专家功能(Yang 等人,2024)。用户交互通过基于聊天的用户界面实现,该界面可视化智能体当前的操作并允许实时反馈(图 1,§D)。此外,评估框架目前支持 15 个基准,我们使用这些基准来评估我们的智能体(§4)。
Released under a permissive MIT license allowing commercial use, OpenHands is poised to support a diverse array of research and real-world applications across academia and industry. OpenHands has gained significant traction, with 32K GitHub stars and more than 2.1K contributions from over 188 contributors. We envision OpenHands as a catalyst for future research innovations and diverse applications driven by a broad community of practitioners.
在允许商业使用的宽松 MIT 许可证下发布,OpenHands 准备支持学术界和工业界多样化的研究和实际应用。OpenHands 获得了显著的关注,拥有 32K 个 GitHub 星标和来自超过 188 名贡献者的 2100 多次贡献。我们设想 OpenHands 将成为未来研究创新和由广泛从业者社区驱动的多样化应用的催化剂。

Figure 2: OpenHands consists of 3 main components: 1) Agent abstraction where community can contribute different implementation of agents (§2.1) into agenthub (§3); 2) Event stream for tracking history of actions and observations; 3) Runtime to execute all actions into observations (§2.2).
图 2:OpenHands 由 3 个主要组件构成:1)代理抽象,社区可以贡献不同实现的代理(§2.1)到代理中心(§3);2)事件流,用于跟踪行动和观察的历史;3)运行时,用于执行所有行动到观察(§2.2)。
An agent can perceive the state of the environment (e.g., prior actions and observations) and produce an action for execution while solving a user-specified task.
一个智能体可以感知环境的状态(例如,先前的动作和观察结果),并在解决用户指定的任务时生成一个动作来执行。
The State and Event Stream. In OpenHands, the state is a data structure that encapsulates all relevant information for the agent’s execution. A key component of this state is the event stream, which is a chronological collection of past actions and observations, including the agent’s own actions and user interactions (e.g., instructions, feedback). In addition to the event stream, the state incorporates auxiliary information for agent’s operation, such as the accumulative cost of LLM calls, metadata to track multi-agent delegation (§2.4), and other execution-related parameters.
状态与事件流。在 OpenHands 中,状态是一个封装了代理执行所需所有相关信息的结构。该状态的一个关键组成部分是事件流,它是一个按时间顺序收集的过去行动和观察记录的集合,包括代理自身的行动和用户交互(例如,指令、反馈)。除了事件流,状态还包含了辅助信息以支持代理的运行,例如 LLM 调用的累积成本、用于追踪多代理委托的元数据(§2.4)以及其他与执行相关的参数。
Actions. Inspired by CodeAct (Wang et al., 2024a), OpenHands connects an agent with the environment through a core set of general actions. Actions IPythonRunCellAction and CmdRunAction enable the agent to execute arbitrary Python code and bash commands inside the sandbox environment (e.g., a securely isolated Linux operating system). BrowserInteractiveAction enables interaction with a web browser with a domain-specific language for browsing introduced by BrowserGym (Drouin et al., 2024). These actions were chosen to provide a comprehensive yet flexible set of primitives covering most tasks performed by human software engineers and analysts. The action space based on programming languages (PL) is powerful and flexible enough to perform any task with tools in different forms (e.g., Python function, REST API, etc.) while being reliable and easy to maintain (Wang et al., 2024a) .
动作。受 CodeAct(Wang 等人,2024a)启发,OpenHands 通过一套核心通用动作将智能体与环境连接起来。Actions IPythonRunCellAction 和 CmdRunAction 使智能体能够在沙盒环境中执行任意 Python 代码和 bash 命令(例如,一个安全隔离的 Linux 操作系统)。BrowserInteractiveAction 通过 BrowserGym(Drouin 等人,2024)引入的用于浏览的特定领域语言,实现与浏览器的交互。这些动作的选择是为了提供一套全面且灵活的基础原语,涵盖人类软件工程师和分析员执行的大多数任务。基于编程语言(PL)的动作空间强大且灵活,足以使用不同形式的工具(例如,Python 函数、REST API 等)执行任何任务,同时保持可靠性和易于维护(Wang 等人,2024a)。
class MinimalAgent:
def reset(self) -> None:
self.system_message = "You are a helpful assistant ..."
def step(self, state: State):
messages: list[dict[str, str]] = [
{'role': 'system', 'content': self.system_message}
]
for prev_action, obs in state.history:
action_message = get_action_message(prev_action)
messages.append(action_message)
obs_message = get_observation_message(obs)
messages.append(obs_message)
# use llm to generate response (e.g., thought, action)
response = self.llm.do_completion(messages)
# parse and execute action in the runtime
action = self.parse_response(response)
if self.is_finish_command(action):
return AgentFinishAction()
elif self.is_bash_command(action):
return CmdRunAction(command=action.command)
elif self.is_python_code(action):
return IPythonRunCellAction(code=action.code)
elif self.is_browser_action(action):
return BrowseInteractiveAction(code=action.code)
else:
return MessageAction(content=action.message)
Figure 3:Minimal example of implementing an agent in OpenHands.
图 3:在 OpenHands 中实现一个代理的最小示例。
This design is also compatible with existing tool-calling agents that require a list of pre-defined tools (Chase, 2022). That is, users can easily define tools using PL supported in primitive actions (e.g., write a Python function for calculator) and make those tools available to the agent through JSON-style function-calling experiences (Qin et al., 2023). Moreover, the framework’s powerful PL-based primitives further make it possible for the agents to create tools by themselves (e.g., by generating Python functions, Yuan et al. 2023) when API to complete the task is unavailable. Refer to §2.3 for how these core PL-based actions can be composed into a diverse set of tools.
该设计也与需要预定义工具列表的现有工具调用代理兼容(Chase,2022)。也就是说,用户可以轻松地使用原始动作支持的 PL 定义工具(例如,为计算器编写一个 Python 函数),并通过 JSON 风格的函数调用体验将这些工具提供给代理(Qin 等人,2023)。此外,该框架强大的基于 PL 的原始操作进一步使代理能够在任务 API 不可用时自行创建工具(例如,通过生成 Python 函数,Yuan 等人,2023)。有关这些核心基于 PL 的操作如何组合成多样化的工具集,请参阅§2.3。
Observations. Observations describe the environmental changes (e.g., execution result of prior actions, text messages from the human user etc.) that the agent observes.
观察。观察描述了智能体所观察到的环境变化(例如,先前行动的执行结果、人类用户的文本消息等)。
Implement a New Agent. The agent abstraction is designed to be simple yet powerful, allowing users to create and customize agents for various tasks easily. The core of the agent abstraction lies in the step function, which takes the current state as input and generates an appropriate action based on the agent’s logic. Simplified example code for the agent abstraction is illustrated in Fig. 3. By providing this abstraction, OpenHands allows the users to focus on defining desired agent behavior and logic without worrying about the low-level details of how actions are executed (§2.2).
实现新智能体。智能体抽象设计得既简单又强大,使用户能够轻松创建和定制用于各种任务的智能体。智能体抽象的核心在于步骤函数,该函数以当前状态为输入,并根据智能体的逻辑生成适当的行动。智能体抽象的简化示例代码如图 3 所示。通过提供这种抽象,OpenHands 允许用户专注于定义所需的智能体行为和逻辑,而无需担心行动执行的底层细节(§2.2)。
Agent Runtime provides a general environment that equips the agent with an action space comparable to that of human software developers, enabling OpenHands agents to tackle a wide range of software development and web-based tasks, including complex software development workflows, data analysis projects, web browsing tasks, and more. It allows the agent to access a bash terminal to run code and command line tools, utilize a Jupyter notebook for writing and executing code on-the-fly, and interact with a web browser for web-based tasks (e.g., information seeking).
Agent Runtime 提供了一个通用环境,使代理具备与人类软件开发者相当的操作空间,使 OpenHands 代理能够处理广泛的软件开发和基于网络的任务,包括复杂的软件开发工作流、数据分析项目、网络浏览任务等。它允许代理访问 bash 终端来运行代码和命令行工具,利用 Jupyter 笔记本实时编写和执行代码,并与网络浏览器交互以处理基于网络的任务(例如,信息检索)。
Docker Sandbox. For each task session, OpenHands spins up a securely isolated docker container sandbox, where all the actions from the event stream are executed. OpenHands connects to the sandbox through a REST API server running inside it (i.e., the OpenHands action execution API), executes arbitrary actions (e.g., bash command, python code) from the event stream, and returns the execution results as observations. A configurable workspace directory containing files the user wants the agent to work on is mounted into that secure sandbox for OpenHands agents to access.
Docker 沙盒。对于每个任务会话,OpenHands 会启动一个安全隔离的 docker 容器沙盒,所有来自事件流的操作都在其中执行。OpenHands 通过运行在其内部的 REST API 服务器(即 OpenHands 动作执行 API)连接到沙盒,从事件流执行任意操作(例如,bash 命令、Python 代码),并将执行结果作为观察结果返回。一个可配置的工作空间目录,其中包含用户希望代理处理的文件,会被挂载到该安全沙盒中,供 OpenHands 代理访问。
OpenHands Action Execution API. OpenHands maintains an API server that runs inside the docker sandbox to listen for action execution requests from the event stream. The API server maintains:
OpenHands 动作执行 API。OpenHands 维护一个 API 服务器,该服务器在 docker 沙盒内运行,用于监听来自事件流中的动作执行请求。API 服务器维护:
Arbitrary Docker Image Support. OpenHands allows agents to run on arbitrary operating systems with different software environments by supporting runtime based on arbitrary docker images. OpenHands implements a build mechanism that takes a user-provided arbitrary docker image and installs OpenHands action execution API into that image to allow for agent interactions. We include a detailed description of OpenHands agent runtime in §F.
任意 Docker 镜像支持。OpenHands 通过支持基于任意 docker 镜像的运行时,允许代理在不同软件环境下运行在不同的操作系统上。OpenHands 实现了一种构建机制,该机制将用户提供的任意 docker 镜像安装 OpenHands 动作执行 API,以允许代理交互。我们在§F 中详细描述了 OpenHands 代理运行时。
SWE-Agent (Yang et al., 2024) highlights the importance of a carefully crafted Agent-Computer Interface (ACI, i.e., specialized tools for particular tasks) in successfully solving complex tasks. However, creating, maintaining, and distributing a wide array of tools can be a daunting engineering challenge, especially when we want to make these tools available to different agent implementations (§3). To tackle these, we build an AgentSkills library, a toolbox designed to enhance the capabilities of agents, offering utilities not readily available through basic bash commands or python code.
SWE-Agent (Yang 等人,2024) 强调了精心设计的代理-计算机接口(ACI,即特定任务的专用工具)在成功解决复杂任务中的重要性。然而,创建、维护和分发各种工具可能是一项艰巨的工程挑战,特别是当我们希望将这些工具提供给不同的代理实现(§3)时。为了应对这些挑战,我们构建了一个 AgentSkills 库,这是一个设计用来增强代理能力的工具箱,提供了通过基本 bash 命令或 python 代码难以直接获得的实用工具。
Easy to create and extend tools. AgentSkills is designed as a Python package consisting of different utility functions (i.e., tools) that are automatically imported into the Jupyter IPython environment (§2.2). The ease of defining a Python function as a tool lowers the barrier for community members to contribute new tools to the library. The generality of Python packages also allows different agent implementations to easily leverage these tools through one of our core action IPythonRunCellAction (§2.1).
易于创建和扩展工具。AgentSkills 被设计为一个 Python 包,其中包含不同的实用函数(即工具),这些函数会自动导入到 Jupyter IPython 环境中(§2.2)。将 Python 函数定义为工具的便捷性降低了社区成员为库贡献新工具的门槛。Python 包的通用性也允许不同的代理实现通过我们核心动作 IPythonRunCellAction (§2.1) 之一轻松利用这些工具。
Inclusion criteria and philosophy. In the AgentSkills library, we do not aim to wrap every possible Python package and re-teach agents their usage (e.g., LLM already knows pandas library that can read CSV file, so we don’t need to re-create a tool that teaches the agent to read the same file format). We only add a new skill when: (1) it is not readily achievable for LLM to write code directly (e.g., edit code and replace certain lines), and/or (2) it involves calling an external model (e.g., calling a speech-to-text model, or model for code editing (Sanger,)).
纳入标准和理念。在 AgentSkills 库中,我们的目标不是封装每一种可能的 Python 包并重新教代理如何使用(例如,LLM 已经知道可以读取 CSV 文件的 pandas 库,因此我们不需要重新创建一个工具来教代理读取相同的文件格式)。我们只在以下情况添加新技能:(1) LLM 直接编写代码难以实现(例如,编辑代码并替换某些行),和/或(2) 涉及调用外部模型(例如,调用语音转文本模型,或代码编辑模型(Sanger))。
Currently supported skills. AgentSkills library includes file editing utilities adapted from SWE-Agent (Yang et al., 2024) and Aider (Gauthier,) like edit_file, which allows modifying an existing file from a specified line; scrolling functions scroll_up and scroll_down for viewing a different part of files. It also contains tools that support reading multi-modal documents, like parse_image and parse_pdf for extracting information from images using vision-language models (e.g., GPT-4V) and reading text from PDFs, respectively. A complete list of supported skills can be found in §I.
当前支持的功能。AgentSkills 库包含从 SWE-Agent(Yang 等人,2024 年)和 Aider(Gauthier)改编的文件编辑工具,如 edit_file,它允许从指定行修改现有文件;滚动功能 scroll_up 和 scroll_down 用于查看文件的不同部分。它还包含支持读取多模态文档的工具,如 parse_image 和 parse_pdf,分别用于使用视觉语言模型(例如 GPT-4V)从图像中提取信息以及从 PDF 中读取文本。支持的功能的完整列表可以在§I 中找到。
OpenHands allows interactions between multiple agents as well. To this end, we use a special action type AgentDelegateAction, which enables an agent to delegate a specific subtask to another agent. For example, the generalist CodeActAgent, with limited support for web-browsing, can use AgentDelegateAction to delegate web browsing tasks to the specialized BrowsingAgent to perform more complex browsing activity (e.g., navigate the web, click buttons, submit forms, etc.).
OpenHands 还允许多个代理之间的交互。为此,我们使用一种特殊的行为类型 AgentDelegateAction,它使一个代理能够将特定的子任务委托给另一个代理。例如,支持网络浏览有限的全能 CodeActAgent 可以使用 AgentDelegateAction 将网络浏览任务委托给专门的 BrowsingAgent 以执行更复杂的浏览活动(例如,浏览网络、点击按钮、提交表单等)。
Table 1: Comparison of different AI agent frameworks (§C). Swe refers to ‘software engineering’. Standardized tool library: if framework contains reusable tools for different agent implementations (§2.3); Built-in sandbox & code execution: if it supports sandboxed execution of arbitrary agent-generated code; Built-in web browser: if it provides agents access to a fully functioning web browser; Human-AI collaboration: if it enables multi-turn human-AI collaboration (e.g., human can interrupt the agent during task execution and/or provide additional feedback and instructions); AgentHub: if it hosts implementations of various agents (§3); Evaluation Framework: if it offers systematic evaluation of implemented agents on challenging benchmarks (§4); Agent QC (Quality Control): if the framework integrates tests (§E) to ensure overall framework software quality.
表 1:不同 AI 代理框架的比较(§C)。Swe 指“软件工程”。标准化工具库:如果框架包含用于不同代理实现的可重用工具(§2.3);内置沙盒与代码执行:如果它支持沙盒执行任意代理生成的代码;内置网络浏览器:如果它为代理提供功能完整的网络浏览器;人机协作:如果它支持多轮人机协作(例如,人类可以在任务执行过程中中断代理并提供额外的反馈和指令);AgentHub:如果它托管各种代理的实现(§3);评估框架:如果它提供在具有挑战性的基准上对实现的代理的系统评估(§4);代理 QC(质量控制):如果框架集成了测试(§E)以确保整体框架软件质量。
| Framework | Domain | Graphic User Interface | Standardized Tool Library | Built-in Sandbox & Code Execution | Built-in Web Browser | Multi-agent Collaboration | Human-AI Collaboration | AgentHub | Evaluation Framework | Agent QC |
|---|---|---|---|---|---|---|---|---|---|---|
| AutoGPT Gravitas (2023) | General | ✔ | ✗ | ✗ | ✗ | ✗ | ✗ | ✔ | ✗ | ✔ |
| LangChain (Chase, 2022) | General | ✗ | ✔ | ✗* | ✗* | ✗ | ✗ | ✔ | ✗ | ✗ |
| MetaGPT (Hong et al., 2023) | General | ✗ | ✔ | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | ✔ |
| AutoGen (Wu et al., 2023) | General | ✗ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✗ |
| AutoAgents (Chen et al., 2024) | General | ✗ | ✗ | ✗ | ✗ | ✔ | ✗ | ✗ | ✗ | ✗ |
| Agents (Zhou et al., 2023b) | General | ✗ | ✗ | ✗ | ✗ | ✔ | ✔ | ✗ | ✗ | ✗ |
| Xagents (Team, 2023) | General | ✔ | ✔ | ✗ | ✔ | ✔ | ✗ | ✔ | ✗ | ✗ |
| OpenAgents (Xie et al., 2023) | General | ✔ | ✗ | ✔ | ✔ | ✗ | ✗ | ✔ | ✗ | ✗ |
| GPTSwarm (Zhuge et al., 2024) | General | ✗ | ✔ | ✗ | ✗ | ✔ | ✔ | ✗ | ✗ | ✗ |
| AutoCodeRover (Zhang et al., 2024b) | SWE | ✗ | ✗ | ✔ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| SWE-Agent (Yang et al., 2024) | SWE | ✗ | ✗ | ✔ | ✗ | ✗ | ✗ | ✗ | ✗ | ✗ |
| OpenHands | General | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ | ✔ |
* No native support. Third-party commercial options are available.
Based on our agent abstraction (§2.1), OpenHands supports a wide range of community-contributed agent implementations for end users to choose from and act as baselines for different agent tasks.
基于我们的代理抽象(§2.1),OpenHands 支持多种社区贡献的代理实现,供终端用户选择,并作为不同代理任务的基准。
CodeAct Agent. CodeActAgent is the default generalist agent based on the CodeAct framework (Wang et al., 2024a). At each step, the agent can (1) converse to communicate with humans in natural language to ask for clarification, confirmation, etc., or (2) to perform the task by executing code (a.k.a., CodeAct), including executing bash commands, Python code, or browser-specific programming language (§2.2). This general action space allows the agent (v1.5 and above) to perform various tasks, including editing files, browsing the web, running programs, etc.
CodeAct Agent。CodeActAgent 是基于 CodeAct 框架(Wang 等人,2024a)的默认通用代理。在每一步中,代理可以(1)通过自然语言对话与人类交流,以寻求澄清、确认等,或(2)通过执行代码(即 CodeAct)完成任务,包括执行 bash 命令、Python 代码或特定浏览器的编程语言(§2.2)。这种通用动作空间允许代理(v1.5 及以上版本)执行各种任务,包括编辑文件、浏览网页、运行程序等。
Browsing Agent. We implemented a generalist web agent called Browsing Agent, to serve as a simple yet effective baseline for web agent tasks. The agent is similar to that in WebArena (Zhou et al., 2023a), but with improved observations and actions, with only zero-shot prompting. Full prompts are in §K.
浏览代理。我们实现了一个通才式网络代理,名为 Browsing Agent,作为网络代理任务的简单而有效的基线。该代理与 WebArena(Zhou 等人,2023a)中的代理相似,但具有改进的观察和行动,仅需零样本提示。完整提示在§K 中。
GPTSwarm Agent. GPTSwarm (Zhuge et al., 2024) pioneers the use of optimizable graphs to construct agent systems, unifying language agent frameworks through modularity. Each node represents a distinct operation, while edges define collaboration and communication pathways. This design allows automatic optimization of nodes and edges, driving advancements in creating multi-agent systems.
GPTSwarm 代理。GPTSwarm(Zhuge 等人,2024)开创了使用可优化图来构建代理系统的应用,通过模块化统一语言代理框架。每个节点代表一个独立操作,而边定义协作和通信路径。这种设计允许节点和边的自动优化,推动多代理系统创建的进步。
Micro Agent(s). In addition, OpenHands enables the creation of micro agent, an agent specialized towards a particular task. A micro agent re-uses most implementations from an existing generalist agent (e.g., CodeAct Agent). It is designed to lower the barrier to agent development, where community members can share specialized prompts that work well for their particular use cases.
微型代理。此外,OpenHands 还支持创建微型代理,这是一种专门针对特定任务的代理。微型代理重用了现有通用代理的大部分实现(例如 CodeAct Agent)。它的设计旨在降低代理开发的门槛,让社区成员可以分享对他们特定用例效果良好的专业提示。
Table 2:Evaluation benchmarks in OpenHands.
表 2:OpenHands 中的评估基准。
| Category | Benchmark | Required Capability |
|---|---|---|
| Software | SWE-Bench (Jimenez et al., 2024) | Fixing GitHub issues |
| Software | HumanEvalFix (Muennighoff et al., 2024) | Fixing bugs |
| Software | BIRD (Li et al., 2023b) | Text-to-SQL |
| Software | BioCoder (Tang et al., 2024c) | Bioinformatics coding |
| Software | ML-Bench (Tang et al., 2024b) | Machine learning coding |
| Software | Gorilla APIBench (Patil et al., 2023) | Software API calling |
| Software | ToolQA (Zhuang et al., 2024) | Tool use |
| Web | WebArena (Zhou et al., 2023a) | Goal planning & realistic browsing |
| Web | MiniWoB++ (Liu et al., 2018) | Short trajectory on synthetic web |
| Misc. Assistance | GAIA (Mialon et al., 2023) | Tool-use, browsing, multi-modality |
| Misc. Assistance | GPQA (Rein et al., 2023) | Graduate-level Google-proof Q&A |
| Misc. Assistance | AgentBench (Liu et al., 2023) | Operating system interaction (bash) |
| Misc. Assistance | MINT (Wang et al., 2024b) | Multi-turn math and code problems |
| Misc. Assistance | Entity Deduction Arena (Zhang et al., 2024a) | State tracking & strategic planning |
| Misc. Assistance | ProofWriter (Tafjord et al., 2021) | Deductive logic reasoning |
To systematically track progress in building generalist digital agents, as listed in Tab. 2, we integrate 15 established benchmarks into OpenHands. These benchmarks cover software engineering, web browsing, and miscellaneous assistance. In this section, we compare OpenHands to open-source reproducible baselines that do not perform manual prompt engineering specifically based on the benchmark content. Please note that we use ‘OH’ as shorthand for OpenHands for the rest of this section for brevity reasons.
为了系统地追踪构建通用型数字代理的进展(如表 2 所示),我们将 15 个成熟的基准测试集整合到 OpenHands 平台中。这些基准测试涵盖了软件工程、网络浏览和杂项辅助等领域。在本节中,我们将 OpenHands 与那些未进行基于基准测试内容的特定手动提示工程的开源可复现基线进行比较。请注意,在本节余下部分,我们使用“OH”作为 OpenHands 的简称,以简洁起见。
In OpenHands, our goal is to develop general digital agents capable of interacting with the world through software interfaces (as exemplified by the code actions described in §2.1). We recognize that a software agent should excel not only in code editing but also in web browsing and various auxiliary tasks, such as answering questions about code repositories or conducting online research.
在 OpenHands 中,我们的目标是开发能够通过软件界面与世界交互的通用数字代理(如§2.1 中描述的代码操作所示)。我们认识到,一个软件代理不仅应在代码编辑方面表现出色,还应在网络浏览和各种辅助任务方面具备能力,例如回答关于代码仓库的问题或进行在线研究。
Tab. 3 showcases a curated set of evaluation results. While OpenHands agents may not achieve top performance in every category, they are designed with generality in mind. Notably, the same CodeAct agent, without any modifications to its system prompt, demonstrates competitive performance across three major task categories: software development, web interaction, and miscellaneous tasks. This is particularly significant when compared to the baseline agents, which are typically designed and optimized for specific task categories.
表 3 展示了一组经过筛选的评估结果。虽然 OpenHands 代理可能并非在所有类别中都达到最佳性能,但它们的设计着眼于通用性。值得注意的是,同一 CodeAct 代理,在不修改其系统提示的情况下,在三个主要任务类别——软件开发、网络交互和杂项任务——中均表现出具有竞争力的性能。与通常为特定任务类别设计和优化的基线代理相比,这一点尤为重要。
Table 3:Selected evaluation results for OpenHands agents (§4). See Tab. 4 (software), Tab. 5 (web), Tab. 6 (miscellaneous assistance) for full results across benchmarks.
表 3:OpenHands 代理的选定评估结果(§4)。有关基准测试的完整结果,请参见表 4(软件)、表 5(网络)、表 6(杂项协助)。
| Agent | Model | SWE-Bench Lite (§4.2) | WebArena (§4.3) | GPQA (§4.4) | GAIA (§4.4) |
|---|---|---|---|---|---|
| Software Engineering Agents | |||||
| SWE-Agent (Yang et al., 2024) | gpt-4-1106-preview | 18.0 | − | − | − |
| AutoCodeRover (Zhang et al., 2024b) | gpt-4-0125-preview | 19.0 | − | − | − |
| Aider (Gauthier) | gpt-4o & claude-3-opus | 26.3 | − | − | − |
| Moatless Tools (Örwall) | claude-3.5-sonnet | 26.7 | − | − | − |
| Agentless (Xia et al., 2024) | gpt-4o | 27.3 | − | − | − |
| Web Browsing Agents | |||||
| Lemur (Xu et al., 2023) | Lemur-chat-70b | − | 5.3 | − | − |
| Patel et al. (2024) | Trained 72B w/ synthetic data | − | 9.4 | − | − |
| AutoWebGLM (Lai et al., 2024) | Trained 7B w/ human/agent annotation | − | 18.2 | − | − |
| Auto Eval & Refine (Pan et al., 2024) | GPT-4 + Reflexion w/ GPT-4V | − | 20.2 | − | − |
| WebArena Agent (Zhou et al., 2023a) | gpt-4-turbo | − | 14.4 | − | − |
| Misc. Assistance Agents | |||||
| AutoGPT (Gravitas, 2023) | gpt-4-turbo | − | − | − | 13.2 |
| Few-shot Prompting + CoT (Rein et al., 2023) | Llama-2-70b-chat | − | − | 28.1 | − |
| gpt-3.5-turbo-16k | − | − | 29.6 | − | |
| gpt-4 | − | − | 38.8 | − | |
| OpenHands Agents | |||||
| CodeActAgent v1.8 | gpt-4o-mini-2024-07-18 | 6.3 | 8.3 | − | − |
| gpt-4o-2024-05-13 | 22.0 | 14.5 | 53.1 | * | |
| claude-3.5-sonnet | 26.0 | 15.3 | 52.0 | − | |
| GPTSwarm v1.0 | gpt-4o-2024-05-13 | − | − | − | 32.1 |
* Numbers are reported from CodeActAgent v1.5.
Next, we report results specifically for software engineering benchmarks in Tab. 4.
接下来,我们在表 4 中报告了专门针对软件工程基准测试的结果。
SWE-Bench (Jimenez et al., 2024) is designed to assess agents’ abilities in solving real-world GitHub issues, such as bug reports or feature requests. The agent interacts with the repository and attempts to fix the issue provided through file editing and code execution. The agent-modified code repository is tested against a test suite incorporating new tests added from human developers’ fixes for the same issue. Each test instance accompanies a piece of “hint text” that consists of natural language suggestions for how to solve the problem. Throughout this paper, we report all results without using hint text. A canonical subset, SWE-bench Lite, is created to facilitate accessible and efficient testing. We default to use this subset for testing for cost-saving consideration.
SWE-Bench(Jimenez 等人,2024)旨在评估代理解决现实世界 GitHub 问题的能力,例如 bug 报告或功能请求。代理与仓库交互,并通过文件编辑和代码执行尝试修复提供的问题。代理修改的代码仓库将使用包含人类开发者针对相同问题修复时添加的新测试的测试套件进行测试。每个测试实例都附带一段“提示文本”,其中包含用于解决该问题的自然语言建议。在本文中,我们报告的所有结果均未使用提示文本。创建了一个规范子集 SWE-bench Lite,以促进可访问和高效的测试。出于节省成本的考虑,我们默认使用此子集进行测试。
Running the complete set of 2294 instances costs 6.9k dollars, using a conservative estimate of 3 dollars per instance.
运行全部 2294 个实例的成本为 6.9k 美元,采用每实例 3 美元的保守估计。
Result. As shown in Tab. 4, our most recent version of CodeActAgent v1.8, using claude-3.5-sonnet, achieves a competitive resolve rate of 26% compared to other open-source SWE specialists.
结果。如表 4 所示,我们最新版本的 CodeActAgent v1.8,使用 claude-3.5-sonnet,与其他开源 SWE 专家相比,实现了具有竞争力的解决率 26%。
Table 4:OpenHands Software Engineering evaluation results (§4.2).
表 4:OpenHands 软件工程评估结果(§4.2)。
| Agent | Model | Success Rate (%) | Avg. Cost ($) |
|---|---|---|---|
| SWE-Bench Lite (Jimenez et al., 2024), 300 instances, w/o Hint | |||
| SWE-Agent (Yang et al., 2024) | gpt-4-1106-preview | 18.0 | 1.67 |
| AutoCodeRover (Zhang et al., 2024b) | gpt-4-0125-preview | 19.0 | − |
| Aider (Gauthier) | gpt-4o & claude-3-opus | 26.3 | − |
| OH CodeActAgent v1.8 | gpt-4o-mini-2024-07-18 | 7.0 | 0.01 |
| gpt-4o-2024-05-13 | 22.0 | 1.72 | |
| claude-3-5-sonnet@20240620 | 26.0 | 1.10 | |
| HumanEvalFix (Muennighoff et al., 2024), 164 instances | |||
| Prompting, 0-shot | BLOOMZ-176B | 16.6 | − |
| OctoCoder-15B | 30.4 | − | |
| DeepSeekCoder-33B-Instruct | 47.5 | − | |
| StarCoder2-15B | 48.6 | − | |
| SWE-Agent, 1-shot (Yang et al., 2024) | gpt-4-turbo | 87.7 | − |
| OH CodeActAgent v1.5, Generalist, 0-shot | gpt-3.5-turbo-16k-0613 | 20.1 | 0.11 |
| gpt-4o-2024-05-13 | 79.3 | 0.14 | |
| BIRD (Li et al., 2023b), 300 instances | |||
| Prompting, 0-shot | CodeLlama-7B-Instruct | 18.3 | - |
| CodeQwen-7B-Chat | 31.3 | - | |
| OH CodeActAgent v1.5 | gpt-4-1106-preview | 42.7 | 0.19 |
| gpt-4o-2024-05-13 | 47.3 | 0.11 | |
| ML-Bench (Tang et al., 2024b), 68 instances | |||
| Prompting + BM25, 0-shot | gpt-3.5-turbo | 11.0 | - |
| gpt-4-1106-preview | 22.1 | - | |
| gpt-4o-2024-05-13 | 26.2 | - | |
| SWE-Agent (Yang et al., 2024) | gpt-4-1106-preview | 42.6 | 1.91 |
| Aider (Gauthier) | gpt-4o | 64.4 | - |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 76.5 | 0.25 |
| gpt-4-1106-preview | 58.8 | 1.22 | |
| gpt-3.5-turbo-16k-0613 | 13.2 | 0.12 | |
| BioCoder (Python) (Tang et al., 2024b), 157 instances | |||
| Prompting, 0-shot | gpt-3.5-turbo | 11.0 | - |
| gpt-4-1106-preview | 12.7 | - | |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 27.5 | 0.13 |
| Gorilla APIBench (Patil et al., 2023), 1775 instances | |||
| Prompting, 0-shot | claude-v1 | 8.7 | - |
| gpt-4-0314 | 21.2 | - | |
| gpt-3.5-turbo-0301 | 29.7 | - | |
| Gorilla (finetuned, 0-shot) | llama-7b | 75.0 | - |
| OH CodeActAgent v1.5 | gpt-3.5-turbo-0125 | 21.6 | 0.002 |
| gpt-4o-2024-05-13 | 36.4 | 0.04 | |
| ToolQA (Zhuang et al., 2024), 800 instances | |||
| Prompting, 0-shot | ChatGPT + CoT | 5.1 | - |
| ChatGPT | 5.6 | - | |
| Chameleon | 10.6 | - | |
| ReAct, 0-shot | gpt-3.5-turbo | 36.8 | - |
| gpt-3 | 43.1 | - | |
| OH CodeActAgent v1.5 | gpt-3.5-turbo-0125 | 2.3 | 0.03 |
| gpt-4o-2024-05-13 | 47.2 | 0.91 |
HumanEvalFix (Muennighoff et al., 2024) tasks agents to fix a bug in a provided function with the help of provided test cases. The bugs are created to ensure one or more test cases fail. We focus on the Python subset of the benchmark and allow models to solve the bugs by self-debug over multiple turns, incorporating feedback from test execution. We follow the setup from Muennighoff et al. (2024) using pass@k (Chen et al., 2021). Results. In Tab. 4, OpenHands CodeActAgent successfully fixes 79.3% of bugs in the Python split. This is significantly better than all non-agentic approaches, almost doubling the performance of StarCoder2-15B (Lozhkov et al., 2024; Li et al., 2023c). While SWE-Agent achieves 87.7%, Yang et al. (2024) provides the model a full demonstration of a successful sample trajectory fixing one of the bugs in the test dataset (“1-shot”), whereas our evaluation of OpenHands is 0-shot. As HumanEvalFix has been created by humans and all bugs carefully validated, achieving 100% on this benchmark is entirely feasible, which we seek to do in future iterations of OpenHands.
HumanEvalFix (Muennighoff 等人,2024) 任务代理在提供的测试用例的帮助下修复提供的函数中的错误。这些错误被设计为确保一个或多个测试用例失败。我们专注于基准测试的 Python 子集,并允许模型通过多轮自我调试来修复错误,并结合测试执行的反馈。我们遵循 Muennighoff 等人 (2024) 的设置,使用 pass@k (Chen 等人,2021)。结果。在表 4 中,OpenHands CodeActAgent 成功修复了 Python 分割中的 79.3% 个错误。这比所有非代理方法都要好得多,几乎将 StarCoder2-15B (Lozhkov 等人,2024;Li 等人,2023c) 的性能提高了一倍。虽然 SWE-Agent 实现 87.7%,Yang 等人 (2024) 为模型提供了一个完整的成功样本轨迹,用于修复测试数据集中一个错误(“1-shot”),而我们的 OpenHands 评估是 0-shot。由于 HumanEvalFix 是由人类创建的,并且所有错误都经过仔细验证,因此在这个基准测试上实现 100% 完全可行,我们将在 OpenHands 的未来迭代中努力实现这一点。
ML-Bench (Tang et al., 2024b) evaluates agents’ ability to solve machine learning tasks across 18 GitHub repositories. The benchmark comprises 9,641 tasks spanning 169 diverse ML problems, requiring agents to generate bash scripts or Python code in response to user instructions. In the sandbox environment, agents can iteratively execute commands and receive feedback, allowing them to understand the repository context and fulfill user requirements progressively. Following the setup from the original paper, we perform agent evaluation on the quarter subset of ML-Bench.
ML-Bench (Tang 等人,2024b) 评估了代理解决跨 18 个 GitHub 仓库的机器学习任务的能力。该基准包含 9641 个任务,涵盖 169 个不同的机器学习问题,要求代理根据用户指令生成 bash 脚本或 Python 代码。在沙盒环境中,代理可以迭代执行命令并接收反馈,使其能够理解仓库上下文并逐步满足用户需求。遵循原始论文的设置,我们在 ML-Bench 的四分之一子集上进行了代理评估。
Gorilla APIBench (Patil et al., 2023) evaluates agents’ abilities to use APIs. it incorporates tasks on TorchHub, TensorHub, and HuggingFace. During the evaluation, models are given a question related to API usage, such as "identify an API capable of converting spoken language in a recording to text." Correctness is evaluated based on whether the model’s API call is in the correct domain.
Gorilla APIBench(Patil 等人,2023)评估代理使用 API 的能力。它包含 TorchHub、TensorHub 和 HuggingFace 上的任务。在评估过程中,模型会得到一个与 API 使用相关的问题,例如“识别一个能够将录音中的语音转换为文本的 API。”正确性评估基于模型 API 调用是否在正确的领域内。
ToolQA (Zhuang et al., 2024) evaluates agents’ abilities to use external tools. This benchmark includes tasks on various topics like flight status, coffee price, Yelp data, and Airbnb data, requiring the use of various tools such as text tools, database tools, math tools, graph tools, code tools, and system tools. It features two levels: easy and hard. Easy questions focus more on single-tool usage, while hard questions emphasize reasoning. We adopt the easy subset for evaluation.
ToolQA(Zhuang 等人,2024)评估代理使用外部工具的能力。这个基准包含关于飞行状态、咖啡价格、Yelp 数据和 Airbnb 数据等不同主题的任务,需要使用各种工具,如文本工具、数据库工具、数学工具、图工具、代码工具和系统工具。它分为两个级别:简单和困难。简单问题更侧重于单工具使用,而困难问题强调推理。我们采用简单子集进行评估。
BioCoder (Tang et al., 2024c) is a repository-level code generation benchmark that evaluates agents’ performance on bioinformatics-related tasks, specifically the ability to retrieve and accurately utilize context. The original prompts contain the relevant context of the code; however, in this study, we have removed them to demonstrate the capability of OpenHands to perform context retrieval, self-debugging, and reasoning in multi-turn interactions. BioCoder consists of 157 Python and 50 Java functions, each targeting a specific area in bioinformatics, such as proteomics, genomics, and other specialized domains. The benchmark targets real-world code by generating code in existing repositories where the relevant code has been masked out.
BioCoder(Tang 等人,2024c)是一个代码生成基准,用于评估代理在生物信息学相关任务上的表现,特别是检索和准确利用上下文的能力。原始提示中包含了与代码相关的上下文;然而,在本研究中,我们已将其移除,以展示 OpenHands 在多轮交互中执行上下文检索、自我调试和推理的能力。BioCoder 包含 157 个 Python 和 50 个 Java 函数,每个函数针对生物信息学中的特定领域,如蛋白质组学、基因组学和其他专业领域。该基准通过在现有代码库中生成代码来模拟真实世界的代码,其中相关的代码已被遮盖。
BIRD (Li et al., 2023b) is a benchmark for text-to-SQL tasks (i.e., translate natural language into executable SQL) aimed at realistic and large-scale database environments. We select 300 samples from the dev set to integrate into OpenHands and evaluate on execution accuracy. Additionally, we extend the setting by allowing the agent to engage in multi-turn interactions to arrive at the final SQL query, enabling it to correct historical results by observing the results of SQL execution.
BIRD (Li 等人,2023b) 是一个用于文本到 SQL 任务的基准(即将自然语言翻译成可执行的 SQL),旨在针对真实和大规模的数据库环境。我们从开发集中选择 300 个样本集成到 OpenHands 中,并在执行准确性上进行评估。此外,我们通过允许代理进行多轮交互来最终生成 SQL 查询,使其能够通过观察 SQL 执行结果来修正历史结果。
We report evaluation results for web browsing benchmarks in Tab. 5.
我们在表 5 中报告了网页浏览基准的评估结果。
WebArena (Zhou et al., 2023a) is a self-hostable, execution-based web agent benchmark that allows agents to freely choose which path to take in completing their given tasks. WebArena comprises 812 human-curated task instructions across various domains, including shopping, forums, developer platforms, and content management systems. Results. From Tab. 5, we can see that our BrowsingAgent achieves competitive performance among agents that use LLMs with domain-general prompting techniques.
WebArena (Zhou 等人,2023a) 是一个可自托管、基于执行的网页代理基准,允许代理自由选择完成给定任务的路径。WebArena 包含 812 个跨不同领域的人工编写的任务指令,包括购物、论坛、开发者平台和内容管理系统。结果。从表 5 中,我们可以看到我们的 BrowsingAgent 在使用 LLMs 和领域通用提示技术的代理中取得了具有竞争力的性能。
MiniWoB++ (Liu et al., 2018) is an interactive web benchmark, with built-in reward functions. The tasks are synthetically initialized on 125 different minimalist web interfaces. Unlike WebArena, tasks are easier without page changes, require fewer steps, and provide low-level step-by-step task directions. Note that it contains a portion of environments that require vision capability to tackle successfully, and many existing work choose to focus only on a subset of the tasks (Kim et al., 2024; Li et al., 2023d; Shaw et al., 2023). Still, we report the performance on the full set and only include baselines that are evaluated on the full set.
MiniWoB++(刘等人,2018)是一个交互式网络基准,内置奖励函数。任务在 125 个不同的极简网络界面上综合初始化。与 WebArena 不同,任务无需页面切换,步骤较少,并提供低级别的逐步任务指导。请注意,其中包含一部分需要视觉能力才能成功处理的环境,许多现有工作选择仅专注于任务的一个子集(金等人,2024;李等人,2023d;肖等人,2023)。尽管如此,我们报告了在完整集上的性能,并且仅包含在完整集上评估的基线。
Table 5:OpenHands Web Browsing Evaluation Results (§4.3).
表 5:OpenHands 网页浏览评估结果(§4.3)。
| Agent | Model | Success Rate (%) | Avg. Cost ($) |
|---|---|---|---|
| WebArena (Zhou et al., 2023a), 812 instances | |||
| Lemur (Xu et al., 2023) | Lemur-chat-70b | 5.3 | − |
| Patel et al. (2024) | Trained 72B with self-improvement synthetic data | 9.4 | − |
| AutoWebGLM (Lai et al., 2024) | Trained 7B with human/agent hybrid annotation | 18.2 | − |
| Auto Eval & Refine (Pan et al., 2024) | GPT-4 + Reflexion w/ GPT-4V reward model | 20.2 | − |
| WebArena Agent (Zhou et al., 2023a) | gpt-3.5-turbo | 6.2 | − |
| gpt-4-turbo | 14.4 | − | |
| OH BrowsingAgent v1.0 | gpt-4o-mini-2024-07-18 | 8.5 | 0.01 |
| gpt-4o-2024-05-13 | 14.8 | 0.15 | |
| claude-3-5-sonnet-20240620 | 15.5 | 0.10 | |
| OH CodeActAgent v1.8 (via BrowsingAgent v1.0) | gpt-4o-mini-2024-07-18 | 8.3 | − |
| gpt-4o-2024-05-13 | 14.5 | − | |
| claude-3-5-sonnet-20240620 | 15.3 | − | |
| MiniWoB++ (Liu et al., 2018), 125 environments | |||
| Workflow Guided Exploration (Liu et al., 2018) | Trained specialist model with environment exploration | 34.6 | − |
| CC-NET (Humphreys et al., 2022) | Trained specialist model with RL and human annotated BC | 91.1 | − |
| OH BrowsingAgent v1.0 | gpt-3.5-turbo-0125 | 27.2 | 0.01 |
| gpt-4o-2024-05-13 | 40.8 | 0.05 | |
| OH CodeActAgent v1.8 (via BrowsingAgent v1.0) | gpt-4o-2024-05-13 | 39.8 | − |
Results for miscellaneous assistance benchmarks are reported in Tab. 6.
杂项协助基准测试的结果报告在表 6 中。
GAIA (Mialon et al., 2023) evaluates agents’ general task-solving skills, covering different real-world scenarios. It requires various agent capabilities, including reasoning, multi-modal understanding, web browsing, and coding. GAIA consists of 466 curated tasks across three levels. Setting up GAIA is traditionally challenging due to the complexity of integrating various tools with the agent, but OpenHands’s infrastructure (e.g., runtime §2.2, tools §2.3) simplifies the integration significantly.
GAIA(Mialon 等人,2023)评估智能体的通用任务解决能力,涵盖不同的现实场景。它需要多种智能体能力,包括推理、多模态理解、网络浏览和编码。GAIA 包含三个级别的 466 个精选任务。由于整合各种工具与智能体的复杂性,传统上设置 GAIA 具有挑战性,但 OpenHands 的基础设施(例如,运行时§2.2,工具§2.3)显著简化了整合过程。
GPQA (Rein et al., 2023) evaluates agents’ ability for coordinated tool use when solving challenging graduate-level problems. Tool use (e.g., python) and web search are often useful to assist agents in answering these questions since they provide accurate calculations that LLMs are often incapable of and access to information outside of the LLM’s parametric knowledge base.
GPQA(Rein 等人,2023)评估了智能体在解决具有挑战性的研究生水平问题时进行协调工具使用的能力。工具使用(例如,python)和网页搜索通常有助于智能体回答这些问题,因为它们提供了 LLMs 通常无法实现的准确计算,以及访问 LLM 参数知识库之外的信息。
Table 6:OpenHands miscellaneous assistance evaluation results (§4.4).
表 6:OpenHands 杂项辅助评估结果(§4.4)
| Agent | Model | Success Rate (%) | Avg. Cost ($) |
|---|---|---|---|
| GAIA (Mialon et al., 2023), L1 validation set, 53 instances | |||
| AutoGPT (Gravitas, 2023) | gpt-4-turbo | 13.2 | − |
| OH GPTSwarm v1.0 | gpt-4-0125-preview | 30.2 | 0.110 |
| gpt-4o-2024-05-13 | 32.1 | 0.050 | |
| GPQA (Rein et al., 2023), diamond set, 198 instances | |||
| Human (Rein et al., 2023) | Expert human | 81.3 | − |
| Non-expert human | 21.9 | − | |
| Few-shot Prompting + Chain-of-Thought (Rein et al., 2023) | gpt-3.5-turbo-16k | 29.6 | − |
| gpt-4 | 38.8 | − | |
| OH CodeActAgent v1.8 | claude-3-5-sonnet-20240620 | 52.0 | 0.065 |
| AgentBench (Liu et al., 2023), OS (bash) subset, 144 instances | |||
| AgentBench Baseline Agent (Liu et al., 2023) | gpt-4 | 42.4 | − |
| gpt-3.5-turbo | 32.6 | − | |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 57.6 | 0.085 |
| gpt-3.5-turbo-0125 | 11.8 | 0.006 | |
| MINT (Wang et al., 2024b), math subset, 225 instances | |||
| MINT Baseline Agent | gpt-4-0613 | 65.8 | − |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 77.3 | 0.070 |
| gpt-3.5-turbo-16k-0613 | 33.8 | 0.048 | |
| MINT (Wang et al., 2024b), code subset, 136 instances | |||
| MINT Baseline Agent | gpt-4-0613 | 59.6 | − |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 50.0 | 0.087 |
| gpt-3.5-turbo-16k-0613 | 5.2 | 0.030 | |
| ProofWriter (Tafjord et al., 2021), 600 instances | |||
| Few-shot Prompting + Chain-of-Thought (Pan et al., 2023) | gpt4 | 68.1 | − |
| Logic-LM (Pan et al., 2023) | gpt4 + symbolic solver | 79.6 | − |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 78.8 | − |
| Entity Deduction Arena (Zhang et al., 2024a), 200 instances | |||
| Zero-shot Prompting (Zhang et al., 2024a) | gpt-4-0314 | 40.0 | − |
| gpt-3.5-turbo-0613 | 27.0 | − | |
| OH CodeActAgent v1.5 | gpt-4o-2024-05-13 | 38.0 | − |
| gpt-3.5-turbo-16k-0613 | 24.0 | − |
AgentBench (Liu et al., 2023) evaluates agents’ reasoning and decision-making abilities in a multi-turn, open-ended generation setting. We selected the code-grounded operating system (OS) subset with 144 tasks. Agents from OpenHands interact directly with the task-specific OS using bash commands in a multi-turn manner, combining interaction and reasoning to automate task completion.
AgentBench(刘等人,2023)在一个多轮、开放式生成环境中评估智能体的推理和决策能力。我们选择了包含 144 个任务的代码基础操作系统(OS)子集。OpenHands 中的智能体通过 bash 命令以多轮方式直接与特定任务的 OS 交互,结合交互和推理来自动完成任务。
MINT (Wang et al., 2024b) is a benchmark designed to evaluate agents’ ability to solve challenging tasks through multi-turn interactions using tools and natural language feedback simulated by GPT-4. We use coding and math subsets used in Yuan et al. (2024). We follow the original paper and allow the agent to interact with up to five iterations with two chances to propose solutions.
MINT(王等人,2024b)是一个基准测试,旨在评估智能体通过多轮交互使用工具和由 GPT-4 模拟的自然语言反馈解决复杂任务的能力。我们使用了 Yuan 等人(2024)中使用的编码和数学子集。我们遵循原始论文,允许智能体最多与五轮交互,并有两次机会提出解决方案。
ProofWriter (Tafjord et al., 2021) is a synthetic dataset created to assess deductive reasoning abilities of LLMs. Same as Logic-LM (Pan et al., 2023), we focus on the most challenging subset, which contains 600 instances requiring 5-hop reasoning. To minimize the impact of potential errors in semantic parsing, we use the logical forms provided by Logic-LM.
ProofWriter(Tafjord 等人,2021)是一个合成数据集,用于评估 LLMs 的演绎推理能力。与 Logic-LM(Pan 等人,2023)一样,我们专注于最具挑战性的子集,其中包含 600 个需要 5 跳推理的实例。为了最小化语义解析中潜在错误的影响,我们使用了 Logic-LM 提供的逻辑形式。
Entity Deduction Arena (EDA) (Zhang et al., 2024a) evaluates agents’ ability to deduce unknown entities through strategic questioning, akin to the 20 Questions game. This benchmark tests the agent’s state tracking, strategic planning, and inductive reasoning capabilities over multi-turn conversations. We evaluate two datasets “Things” and “Celebrities”, each comprising 100 instances, and report the average success rate over these two datasets.
实体推断竞技场(EDA)(张等人,2024a)评估智能体通过策略性提问推断未知实体的能力,类似于“20 个问题”游戏。这个基准测试在多轮对话中测试智能体的状态跟踪、策略规划和归纳推理能力。我们评估了两个数据集“事物”和“名人”,每个数据集包含 100 个实例,并报告了在这两个数据集上的平均成功率。
We introduce OpenHands, a community-driven platform that enables the development of agents that interact with the world through software interfaces. By providing a powerful interaction mechanism, a safe sandboxed environment, essential agent skills, multi-agent collaboration capabilities, and a comprehensive evaluation framework, OpenHands accelerates research innovations and real-world applications of agentic AI systems. Despite challenges in developing safe and reliable agents (§A), we are excited about our vibrant community and look forward to OpenHands’s continued evolution.
我们介绍了 OpenHands,一个由社区驱动的平台,它能够开发通过软件接口与世界交互的智能体。通过提供强大的交互机制、安全的沙盒环境、基本的智能体技能、多智能体协作能力和全面的评估框架,OpenHands 加速了智能体 AI 系统的科研创新和实际应用。尽管在开发安全可靠的智能体方面存在挑战(§A),我们对充满活力的社区感到兴奋,并期待 OpenHands 的持续发展。