Anthropic:把 AI Agent 的评估做对比把 Agent 做出来更重要
发布于 • 作者: Ethan
原文Demystifying evals for AI agents。
很多团队在把 AI Agent 推向真实用户之前,最容易低估的一件事,不是模型能力,不是提示词,也不是工具接入,而是评估。没有评估,Agent 的开发很快就会陷入一种熟悉但低效的循环:线上出了问题,人工复现,修一个 bug,又引出新的问题,最后谁也说不清系统到底是在变好,还是只是碰巧这次没出错。
真正有效的评估,不只是“测一下模型行不行”,而是把一个复杂、会调用工具、会跨多轮决策、会改写环境状态的系统,拆成可以持续观察、比较、回归验证的对象。它的价值也不只是拦截回归,更在于让团队提前定义成功、稳定追踪质量、快速迁移新模型,并把“感觉变差了”变成可以定位、可以讨论、可以优化的问题。
这篇文章想说明的核心其实很简单:评估不是 Agent 开发后期补上的测试层,而是决定 Agent 能不能持续迭代、能不能安全放大规模的基础设施。只要系统开始跨多轮工作、调用工具、改写环境,评估就必须从“看最终回答”升级为“同时检查过程、结果和稳定性”。
评估 Agent 难,不是因为“更智能”,而是因为它的行为链条更长、状态更多、路径更开放。
单轮模型的评估通常比较直观:给一个输入,看输出是否符合预期,再用一段评分逻辑判断好坏就行。可到了 Agent,这套做法很快就不够用了。Agent 不只是生成一段文本,它会跨多轮思考,会调用工具,会读取和修改外部状态,还会根据中间结果不断调整下一步动作。这样一来,一个早期小错误就可能沿着执行链一路放大,最后影响最终结果。
更麻烦的是,强模型有时会找到评估设计者没预料到的解法。也就是说,评估不但要能抓住失败,还不能因为设计得太死,把合理甚至更优的路径判成失败。
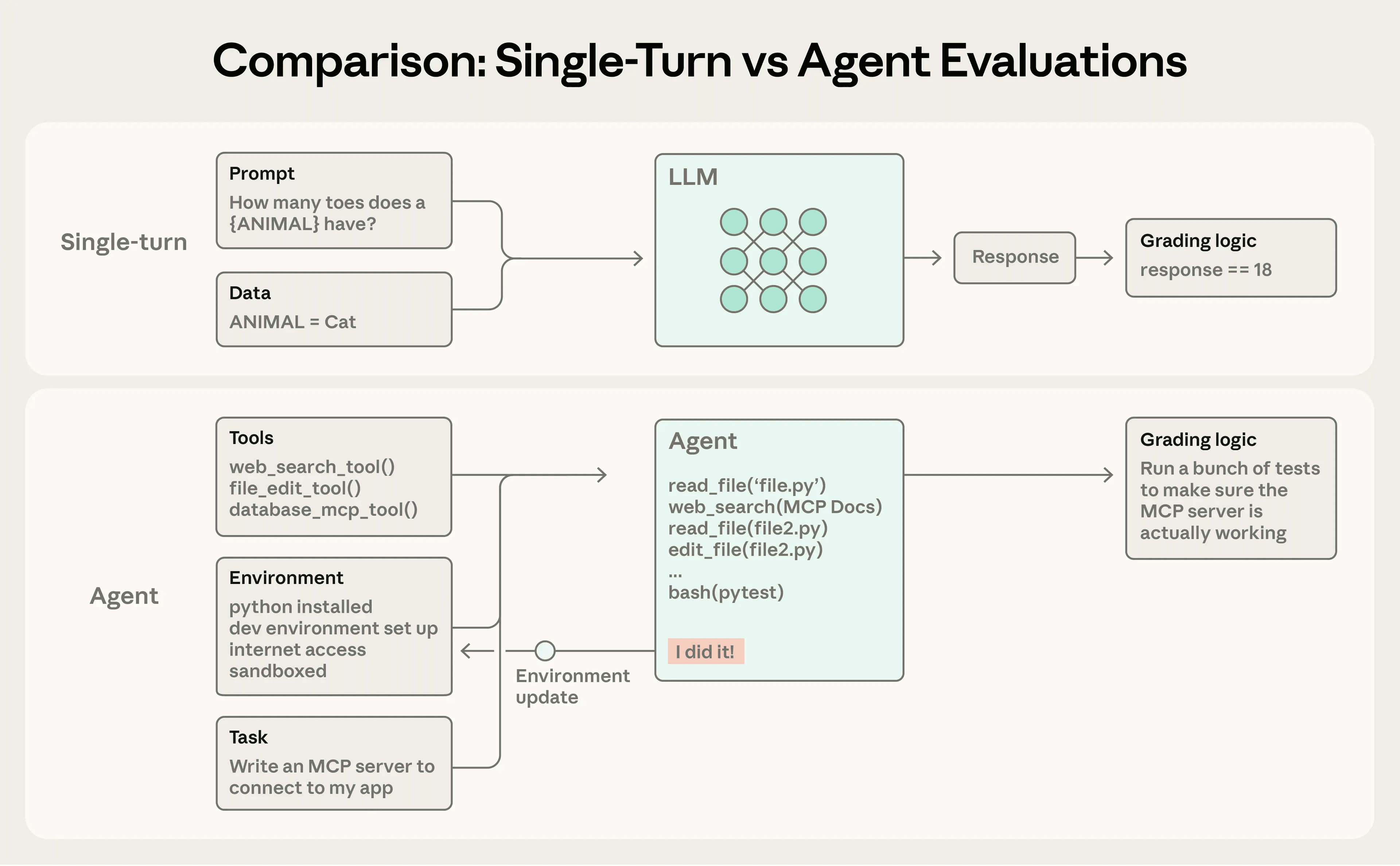
所以,评估 Agent 时,真正要观察的对象不只是“最后回复了什么”,而是一个更完整的系统:
任务,是一次具体测试,包含明确输入和成功标准。 试次,是同一个任务的一次运行,因为模型有随机性,所以同一任务通常要跑多次。 评分器,是判断 Agent 某个方面表现的逻辑,一个任务往往会有多个评分器。 轨迹,也就是完整执行记录,包含对话、工具调用、中间推理和返回结果。 结果,不是 Agent 口头上说自己完成了什么,而是环境最终变成了什么状态。 评估框架,负责把任务跑起来、记录过程、执行评分并汇总结果。 Agent 框架,则是模型真正用来行动的那层执行系统,包括工具编排、循环控制和输出组织。
这几个概念看起来像术语清单,但它们实际上在提醒一件事:评估 Agent,评估的从来不是一句答案,而是一整套“模型加执行框架”的联合行为。
很多团队在最开始做 Agent 时,确实不需要太正式的评估。手工测试、内部试用、直觉判断,往往就足够把原型跑起来。问题在于,这种方式只适合早期,不适合持续迭代。
一旦 Agent 进入生产环境,用户量上来,功能不断扩展,单靠人工验证就会迅速失效。团队会开始听到类似的反馈:这个版本好像变笨了、之前能做的事情现在不稳定了、修了一个地方另一个地方又坏了。可没有评估时,团队没法区分这到底是真回归,还是随机波动;也没法在上线前批量测试数百种场景,更谈不上稳定比较新旧方案。
评估之所以重要,不只是因为它能发现问题,而是因为它把原本模糊的产品要求变成了清晰的质量边界。越早做评估,这件事越有价值。因为早期需求还比较容易翻译成测试任务;等系统已经上线很久,再回头补评估,往往变成从既有行为里反向猜测“成功到底应该长什么样”。
评估还有一个常被低估的价值:它决定了你采用新模型的速度。没有评估时,每次模型升级都要靠长时间手测;有评估时,团队可以很快知道新模型在哪些能力上更强、哪些地方退步了、哪些提示词需要调整,升级周期会短很多。
Agent 的输出复杂、任务类型多,所以评估通常不能只依赖一种方法。更稳妥的做法,是把评分器分成三类,再按任务组合使用。
第一类是代码式评分器。它的优势是快、便宜、客观、可复现。常见做法包括字符串匹配、正则或模糊匹配、单元测试、静态分析、环境状态检查、工具调用校验,以及对轨迹本身做统计,比如回合数、token 用量、延迟等。它的问题也很明显:太脆,容易把“与预期不同但同样正确”的答案误判成失败,而且对主观质量的判断能力有限。
第二类是模型式评分器,也就是让另一个模型按照评分标准来判断输出质量。它的优点是灵活,能处理更开放、更自由的任务,也更容易捕捉语气、完整性、连贯性这类细腻维度。代价是它不完全稳定,成本更高,而且必须反复校准,否则很容易和人类真实判断偏离。
第三类是人工评分。它最接近真正用户或领域专家的判断,可以作为高质量参考,也特别适合校准模型评分器。但它慢、贵、规模化困难,通常不适合作为日常高频评估主力。
真正实用的方案,通常不是三选一,而是按任务需求组合。能用确定性规则判断的地方,尽量先用代码式评分器;必须处理开放性输出的地方,再上模型式评分器;至于人工评分,更适合做抽样复核、质量校准和高风险场景的最终把关。
很多团队做评估不顺,问题不在于不会写测试,而是在于一开始就把两种目标混在一起了。
一类评估是在问:这个 Agent 现在到底能不能做好某类事。这是能力评估。它的任务集应该故意偏难,最好从较低通过率开始,因为它的目的不是证明系统已经很好,而是明确当前能力边界,给团队一个可以持续爬升的坡。
另一类评估是在问:它以前会做的事,现在是不是还会做。这是回归评估。它的目标应该接近满分,因为只要分数下降,就意味着某些旧能力出了问题。
这两类评估服务的是完全不同的决策。能力评估告诉你应该往哪里优化,回归评估告诉你哪里不能退。随着系统成熟,一些原本偏难、通过率较低的能力任务,可能会逐渐稳定下来,然后从能力评估“毕业”,进入持续运行的回归套件。
很多团队之所以会在优化中越改越乱,就是因为只盯着能力提升,没有同步做回归保护。Agent 变得更会做一件事,并不等于它不会在别处退步。
虽然很多方法可以复用,但不同类型的 Agent,真正该重点测的东西并不一样。按读者最容易理解的顺序,可以把它们分成四类。
编码 Agent 的好处是,很多任务的成败本身就适合被确定性判断。代码能不能运行,测试能不能通过,旧功能有没有被破坏,这些都是天然的评估信号。
因此,编码 Agent 的评估通常最适合从稳定环境加严格测试开始。只要有一组覆盖关键目标的通过或失败条件,就已经能形成很强的主评估框架。然后再根据需要补充对轨迹的检查,比如代码风格、工具使用方式、是否和用户进行了恰当互动等。
但这里也有一个重要原则:不要过度执着于检查 Agent 是否按你预设的步骤完成任务。很多团队直觉上会想验证“是不是先用了某个工具,再执行某条命令,再修改某个文件”。问题是,这种检查太脆了。Agent 经常能找到你没预料到但同样正确的路径。评估如果过度约束过程,就会把创造力当成错误。
对话 Agent 的难点在于,评估的不只是结果,还包括交流过程本身。比如客服 Agent,不只是看工单最后有没有关闭,还要看有没有在合理轮数内完成、语气是否合适、解释是否清楚、回复是否基于工具返回的真实信息。
这意味着,对话 Agent 的评估往往天然是多维的: 一部分要测环境状态是否真的变化了; 一部分要测轨迹是否满足约束,比如轮数、是否调用了必要工具; 还有一部分要测互动质量,比如共情、清晰度、礼貌程度和是否真正回应用户诉求。
这类评估经常还需要引入“模拟用户”,也就是用另一个模型来扮演用户角色,和 Agent 展开多轮互动。因为没有持续对话,对话 Agent 的很多能力根本暴露不出来。
研究 Agent 比编码 Agent 更难评估,因为它没有天然的单元测试。你很难用一个简单的二元规则判断一份研究报告是否“足够全面”“足够可信”“足够准确”。
真正的问题在于,研究质量是任务相对的。做市场扫描、做尽调、做科学综述,需要的标准完全不一样。更复杂的是,参考资料本身也会变化,专家之间对“是不是覆盖充分”常常也会有分歧。
因此,研究 Agent 的评估通常需要把“好答案”拆成多个可判断维度: 是否有依据,关键结论能不能从检索到的材料中找到支持; 是否覆盖关键事实,重要信息有没有漏掉; 是否使用了高质量来源,而不是只抓到了最容易搜到的网页; 在开放性总结上,整体是否连贯、完整、可读。
研究任务越主观,模型评分器就越需要和人工专家反复校准。否则看似很细致的评分,最后只是把另一个模型的偏好当成真标准。
电脑操作类 Agent 不是调用 API,也不是写代码,而是像人一样看界面、点按钮、输文字、滚动页面。它评估起来最核心的一点,是必须把 Agent 放进真实或沙盒化的软件环境里,再检查它是否真的完成了任务。
这类任务不能只看“页面上像是成功了”,而要检查后端状态是否真的变化。比如下单任务,不能只看是否跳到了成功页,还要确认订单是否真的写进了系统。不同环境里,评估脚本可能要查看文件系统、数据库、应用配置,甚至 UI 元素本身的属性。
浏览器操作还有一个很实际的评估点:工具选择是否合理。因为 DOM 读取和截图操作各有代价。前者速度快但可能消耗很多 token,后者更省 token 但更慢。一个真正可用的浏览器 Agent,不只是“做对任务”,还要在不同场景下选对交互方式。
Agent 的行为天然有波动。同一个任务,这次过了,下次不一定过;某些任务也许成功率是 90%,另一些可能只有 50%。如果只跑一次就下结论,分数往往会非常不稳定。
评估这件事,必须正视“多次运行”的意义。这里有两个非常关键的指标。
第一个是 $pass@k$,表示在 $k$ 次尝试里,至少成功一次的概率。它回答的是:“多给几次机会,Agent 能不能把这题做出来?” 第二个是 $pass^{k}$,表示连续 $k$ 次尝试全部成功的概率。它回答的是:“这个 Agent 到底稳不稳定,每次都能不能做对?”
两者在 $k=1$ 时相同,但随着试次增加,会朝完全相反的方向走。$pass@k$ 会越来越高,因为尝试次数越多,总有一次做对的机会更大;而 $pass^{k}$ 会越来越低,因为要求每次都成功,本来就是更苛刻的标准。
如果单次成功率是 $0.75$,连续 3 次都成功的概率就是:
$$ (0.75)^3 \approx 0.42 $$
这说明一件很重要的事:看起来单次成功率不低的 Agent,放到真实用户环境里,仍然可能显得不够可靠。
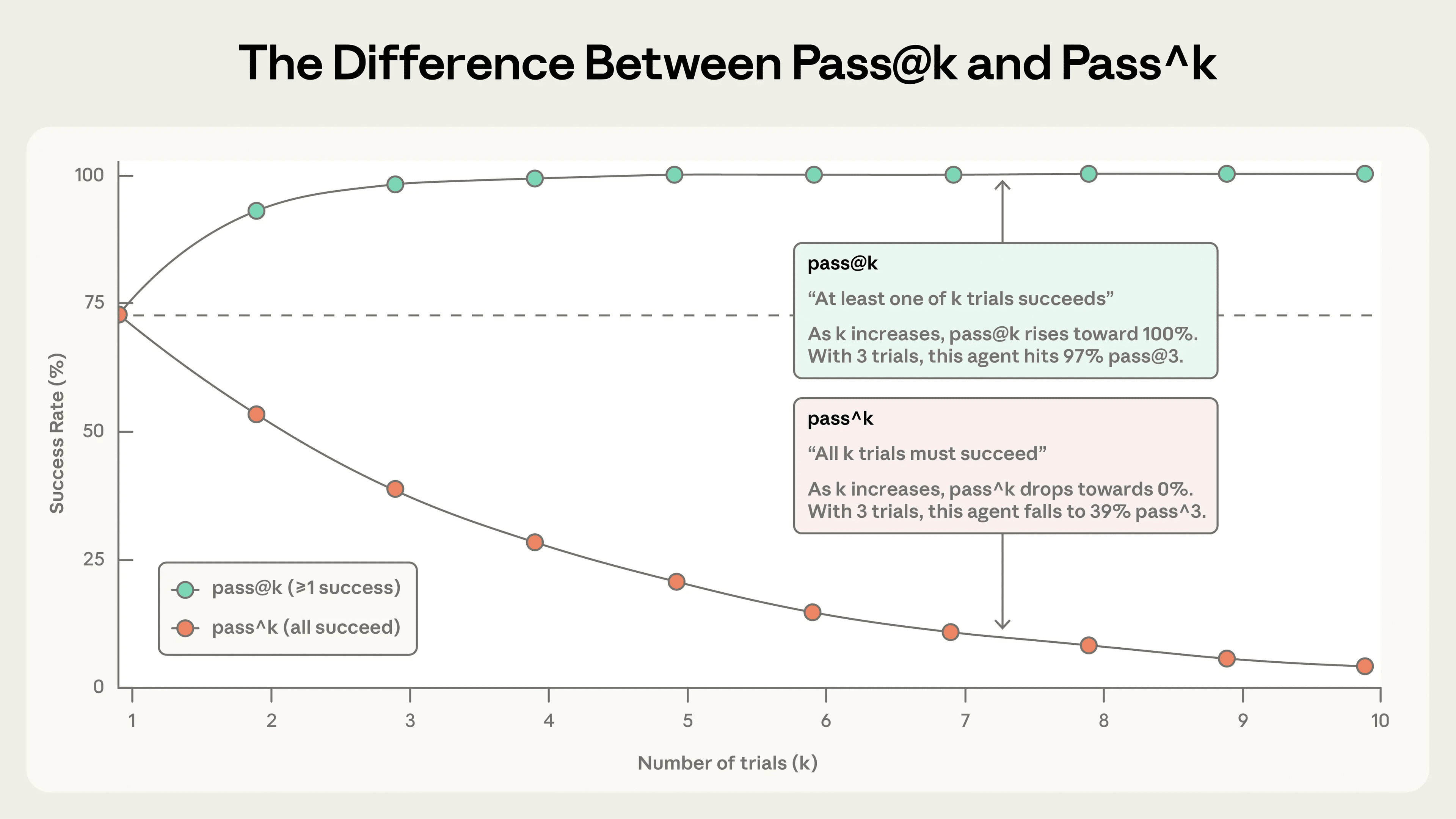
所以,到底该看哪个指标,不是统计习惯问题,而是产品需求问题。只要多试几次、成功一次就有价值的场景,更关心 $pass@k$;而面向用户、要求每次都稳定的场景,更应该看 $pass^{k}$。
评估最容易卡住的地方,是团队总觉得要先攒够几百个任务、设计出完整体系,才值得开始。其实完全相反。早期最有效的做法,往往是用很小的一套任务先建立基本框架,再不断加深。
早期 Agent 的改动通常效果很明显,所以并不需要特别大的样本量。二三十个到五十个来自真实失败案例的任务,往往已经足够开始。越晚启动评估,后面补起来越痛苦,因为你会发现自己不是在写测试,而是在从一个已经复杂化的系统里反推成功标准。
很多评估任务并不需要凭空设计。发布前你本来就在人工验证哪些行为,用户最常尝试哪些任务,支持团队最常收到哪些报错,这些都是天然的任务来源。特别是已经上线的产品,bug 跟踪系统和支持工单里,往往就躺着最有价值的第一批测试集。
一个好任务的标准很实际:两个领域专家独立来看,应该能得出一致的通过或失败判断。如果连人都说不清楚这题该怎么算过,模型评分器更不可能稳定。
任务描述里的每一个被评分器检查的点,都应该能从任务本身明确推出。不能出现“Agent 做错只是因为你没把要求写清楚”的情况。很多看似模型做不到的 0 分任务,最后发现问题并不在模型,而在任务本身不可解、描述含糊,或者评分器配置有 bug。
参考解的重要性就在这里。只要每个任务都有一个确定能通过所有评分器的参考输出,你就能先证明这道题本身是可做的,评分逻辑也是通的。
如果你只测“该做某行为时有没有做”,模型很可能会被优化成“几乎总是做这个行为”。评估如果只覆盖一侧,就会把系统推向另一侧失衡。
比如测试搜索触发策略时,不能只放那些“应该去搜”的问题,还必须放入那些“应该直接回答、不该搜”的问题。否则模型也许看起来搜索命中率很高,实则是过度触发,把本来能直接回答的问题也一律送去检索。
评估环境必须尽量接近真实 Agent 的运行方式,而且每次试次都要从干净状态开始。遗留文件、缓存数据、资源耗尽、上一次试次留下的副作用,都会让结果带上基础设施噪声。
更严重的是,脏环境有时会制造“虚假高分”。比如之前运行留下的痕迹,可能意外给后续试次提供额外线索,让 Agent 看上去比实际更强。这种分数没有任何参考价值。
真正好的评估,通常更关注 Agent 产出了什么,而不是死盯它走了哪条路线。只要结果正确、行为合理,就不该因为它没按设计者预设的步骤执行而被扣死。
同时,复杂任务最好允许部分得分。因为很多现实任务不是“全对或全错”。一个支持 Agent 正确识别问题、完成身份校验,但最后退款失败,显然比一开始就完全跑偏要好。如果评估不能表达这种差异,分数就会过度粗糙,难以指导优化。
模型当裁判很方便,但不能直接信。评分标准必须写得足够清楚,最好把不同维度拆开单独评分,而不是让一个模型一次性判断所有东西。对于证据不足的情况,还应该允许它返回“未知”,避免硬判。
更重要的是,要定期用人工结果来校准模型评分器,确认它和人类专家的判断没有明显偏差。否则自动化越强,偏差可能越大。
总分是结果,轨迹才是解释。真正能帮你分辨“模型不会”和“评估设计错了”的,几乎总是轨迹。
团队如果不读轨迹,很容易把评分器 bug 当成模型退步,也容易把合理解法误判成失败。一个任务失败时,最关键的问题不是“分数为什么低”,而是“这次失败到底公不公平”。如果失败看起来不公平,这个评估本身就该被修。
一套评估如果已经接近满分,它对改进的指导价值就会快速下降。因为这时它只能抓回归,几乎不能再区分更强和更弱的版本。更难的是,当评估接近饱和后,真正的能力提升在分数上常常只体现为很小的变化,容易让团队误判进展不大。
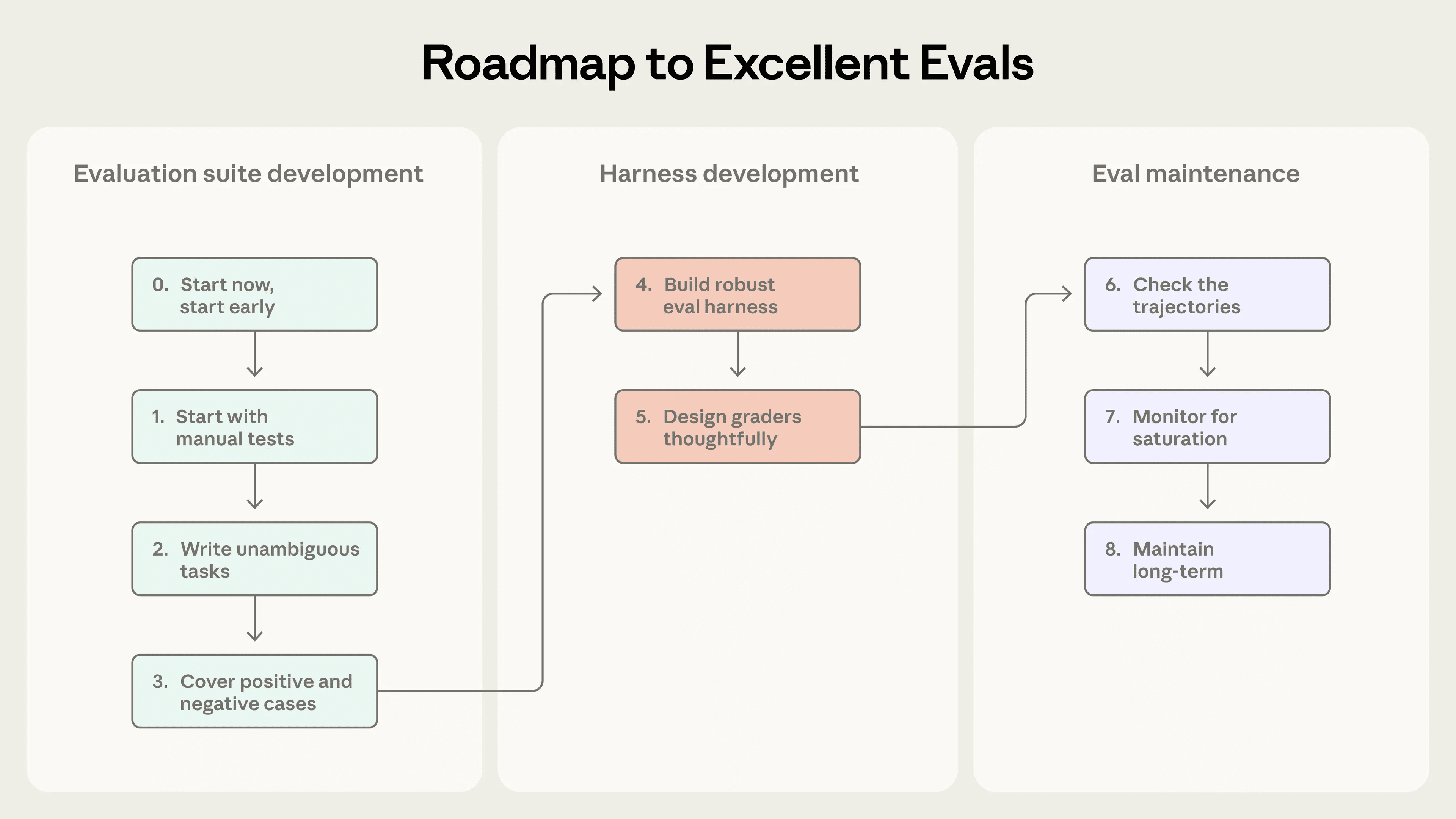
所以,评估不是写完就结束,而是一个长期维护对象。核心基础设施可以由专门团队维护,但任务本身最适合由最靠近产品需求和用户问题的人持续贡献。产品经理、客户成功、销售、支持团队,往往最知道什么叫“真的做好了”。他们不只是评估的使用者,也应该是评估定义的一部分。
自动化评估非常重要,但它从来不是完整答案。
它最大的价值,是可以在不上线、不影响用户的前提下,大规模、可重复地测试 Agent,特别适合在开发阶段和 CI/CD 流程里做第一道防线。可一旦系统真正进入生产环境,你还必须结合生产监控、A/B 测试、用户反馈、人工读轨迹,以及更系统化的人类评审。
这些方法不是互相替代,而是互相补洞。自动化评估快、稳定、可规模化,但可能脱离真实使用分布;生产监控有真实世界信号,但总是偏事后;A/B 测试能测真实用户结果,但慢,而且只能比较已经上线的改动;用户反馈能暴露意外问题,但稀疏且偏向严重故障;人工读轨迹能发现细微问题,但不规模化;系统化人工研究最接近金标准,但代价高,难以高频执行。
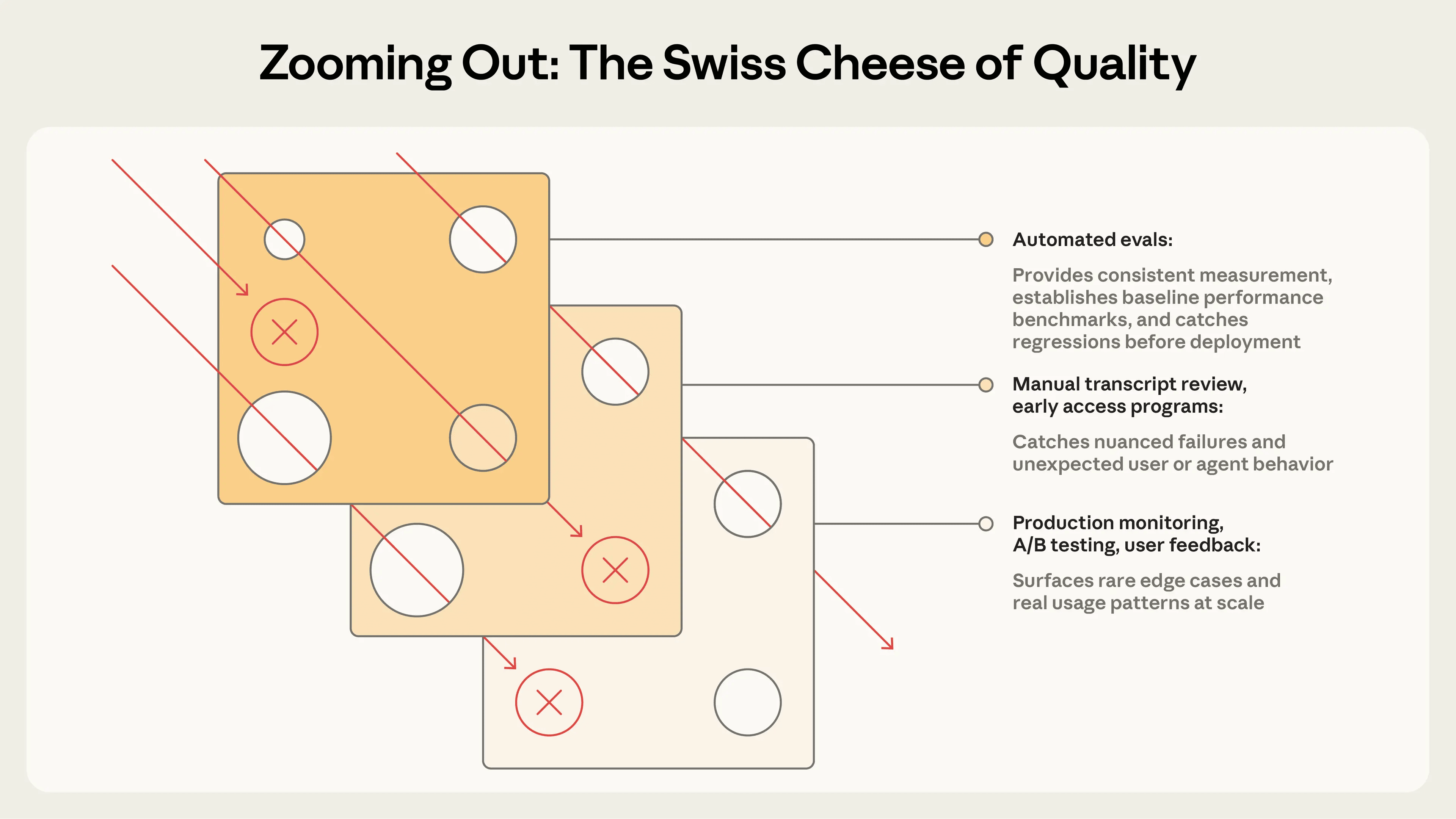
真正成熟的做法,更像是多层防线。自动化评估负责高频、稳定、开发期验证;生产监控负责发现真实环境中的漂移和漏网之鱼;人工审查负责校准标准、理解失败模式。没有哪一层能单独兜住所有问题,但叠在一起,才能形成足够可靠的质量体系。
当 Agent 还只是一个能演示的原型时,评估看起来像额外成本;但当它开始承载真实任务、真实用户和持续迭代时,评估就会从“锦上添花”变成“没有不行”。
一个没有评估的团队,最终会把大量时间花在猜测上:猜用户为什么不满,猜这次修改有没有进步,猜新模型值不值得换。一个有评估的团队,则能把失败沉淀成任务,把任务沉淀成基线,把基线沉淀成迭代速度。
做 Agent,真正该尽早建立的不是一套完美的分数,而是一套可信的判断机制。尽早开始,用真实失败构造任务,把任务写清楚,把环境做稳定,把评分器设计得足够宽容但不易作弊,持续读轨迹、修评估、扩数据集。只要这条路走通,Agent 的开发就不再只是不断试错,而会变成一条可观测、可比较、可累积进步的工程路径。