编译器Lexing(一):前端&正则表达式
发布于 • 作者: Ethan
把一段程序交给编译器时,最先面对它的并不是优化器,也不是代码生成器,而是前端。前端的任务很直接:先确认这段程序是不是合法的,再把原始字符整理成后续阶段真正能处理的结构化表示。理解这一点之后,再看词法分析就会清楚很多——词法分析并不是“把字符串拆一拆”这么简单,而是编译器第一次从无结构的文本里找出结构。
这篇文章要讲清楚三件事:编译器前端到底负责什么,词法分析为什么麻烦,以及为什么现代编译器通常会用正则表达式和 lexer generator 来描述和实现词法分析。主线也很明确:前端的第一步是把字符流变成有意义的 token,而这一步之所以能做得既准确又高效,关键在于把“哪些字符串算一个 token”写成形式化语言,再用正则表达式来描述它。
编译器前端处理的输入,本质上只是一串字符。它的输出则不是“差不多能看懂”的文本,而是一棵已经验证过、适合后续编译流程使用的抽象语法树,也就是 AST。
前端通常可以分成三个部分:词法分析、语法分析和语义分析。它们的分工并不相同。词法分析先把字符流切成 token;语法分析再根据这些 token 识别程序结构,构造 AST;语义分析最后检查这些结构在语言规则下是否真的成立,比如变量和函数是否被正确使用。
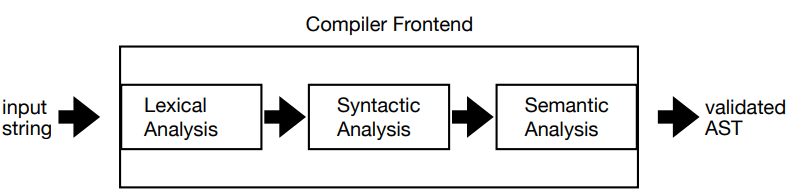
之所以要把前端拆成这几步,是因为编译器后续阶段更适合处理结构化数据,而不是直接面对原始文本。一个优化器处理 AST 或中间表示会很自然,但如果让它直接读字符流,几乎寸步难行。前端做的工作,就是把“程序长什么样”这件事先整理清楚。
这件事和后端或中间优化阶段很不一样。后面的很多 pass 输入已经是树状结构了,而前端最困难的地方恰恰在于:它要从完全没有显式层级的字符串中,恢复出程序真正的结构。
词法分析的目标,是把一整串字符切成一个个不可再分的文本单元,也就是 token。后面的语法分析并不想直接面对字符,而是想面对“这是 if”“这是标识符”“这是整数”“这是左括号”这样的离散符号。
例如,程序片段 if (b == 0) { a = 0; } 在词法分析之后,会被看成一串 token:IF、LPAREN、Ident("b")、EQEQ、Int(0)、RPAREN、LBRACE、Ident("a")、EQ、Int(0)、SEMI、RBRACE。从这一刻开始,编译器不再只是“看见字符”,而是开始“理解片段的角色”。
token 的种类通常包括这些:
a、y11、_100if、else、while2、200、-5002.0、.02、1e5+、*、{、}、(、)、++"x"、"He said, \"Are you?\""// ... 或 /* ... */很多语言里,空白字符会帮助分隔 token,比如空格和制表符。但这并不意味着词法分析只靠“按空格切开”。像 == 和 =、if 和 ifx、字符串里的转义符、注释边界,都会让问题变得远比想象中复杂。有些语言里空白本身还有语义,比如 Python 或 Haskell,这又会进一步提高词法分析的要求。
词法分析的基本目标不难理解,但真正手写一个 lexer 往往非常痛苦。困难不在于写不出能跑的代码,而在于一旦规则变多,它就会迅速变得脆弱、混乱,而且很难确认自己没有漏掉边界情况。
最先遇到的问题,是必须精确定义 token。什么算标识符,什么算整数,什么算字符串,边界到底在哪里,这些都不能模糊。编译器不是人,不能“看起来差不多就当它对了”。
接下来是并行匹配的问题。字符流中的一段文本,经常同时满足多种 token 的前缀条件。lexer 必须在多个候选之间做决定,而不是一条规则一条规则随便试。
另一个常见难点是 lookahead,也就是“多看几个字符再决定”。例如读到 = 时,不能立刻确定它是赋值号,可能后面还有一个 =,组成 ==。如果过早下结论,就会把输入读坏。
此外,错误处理也不简单。lexer 既要尽量指出非法输入的位置,又不能在错误状态下把后续内容全部切乱。再加上不同 token 规则往往彼此交织,手写代码很容易出现难读、难改、难组合的问题。规则一多,维护成本就会迅速失控。
所以,词法分析真正难的地方不是“把字符串拆开”,而是把一整套边界清晰、冲突可判定、实现可维护的文本识别规则系统化地表达出来。
既然大多数 lexer 做的事情本质上很像,只是 token 规则不同,一个自然的思路就是:不要每次都从头手写 tokenizer,而是设计一种更高层的描述方式,让人只写规则,底层通用实现交给工具生成。
这就是 lexer generator 的思路。它把“怎么识别 token”变成一种专门的小语言。开发者描述 token 的形式,工具再把这些规则编译成高效的词法分析器。
这样做有几个直接好处。
首先,可读性和可维护性会明显提升。与其在一大堆分支和状态变量里找逻辑,不如直接阅读“整数是什么”“标识符是什么”“关键字有哪些”这样的规则定义。
其次,效率优化只需要实现一次。大多数 lexer 的核心算法高度相似,真正变化的是规则本身。把这些共性放进工具里,能避免重复造轮子。
还有一个更深层的原因:当这个描述语言的表达能力受控时,很多分析和优化就变得可行。也就是说,不需要面对任意复杂的程序行为,而是面对一个结构非常清楚、能力有限的规则系统。这样既方便推导语义,也方便自动生成实现。
常见的 lexer 工具有 lex、flex、ANTLR;在 Rust 生态里,也常见 logos 和 lalrpop。它们背后的共同思想都是:先把词法规则写成一个形式化规范,再自动生成 lexer。
从这个角度看,lexer generator 本身也像一个编译器。输入是一份高层规则描述,输出是一段真正能运行的词法分析器代码。
于是它也会经历很熟悉的流程:先设计语言,再定义语义,然后把规则转换成中间表示,再做优化,最后生成代码。
这件事之所以重要,是因为它把词法分析从“写一堆字符判断逻辑”提升成了“设计一门用于描述字符串集合的语言”。而 lexer 最核心的问题,正是要回答:哪些字符串属于某种 token,哪些不属于。
所以,接下来的关键不再是编程技巧,而是形式化地描述“字符串的集合”。
为了精确表达 token,需要先固定一个字母表,也就是字符集合,通常记作 $\Sigma$。它可以很小,比如二进制串的字母表 ${0,1}$;也可以是 ASCII;也可以是更大的 Unicode 字符集。
在这个前提下,字符串就是由这些字符构成的有限序列。所谓形式语言,就是这些字符串的一个子集。
这个定义看起来抽象,但对词法分析非常贴切。因为每一种 token,本质上都对应“某一类字符串的集合”。
例如,关键字 def 对应的就是只包含 "def" 这个字符串的集合;布尔字面量可以对应 ${"true","false"}$;所有合法整数构成一个集合;所有合法变量名也构成另一个集合。lexer 的工作,就是判断当前读到的文本属于哪个集合。

这样一来,问题就被压缩成了一个清楚的形式化任务:要有一种语法,用来描述这些字符串集合;还要为这种语法赋予明确语义,说明每种写法到底代表哪一类字符串。
这正是正则表达式擅长的地方。
正则表达式不是“用来查找文本的花哨语法”,它更本质的身份,是一种定义形式语言的表达式系统。每个正则表达式都对应一个字符串集合,也就是它的语义。
最基本的构造包括以下几类。
空串 $\varepsilon$ 表示只包含空字符串的语言,也就是 ${""}$。空集 $\varnothing$ 表示不包含任何字符串的语言。
单个字符,例如 'a',表示只包含 "a" 的语言。
如果有两个正则表达式 $R_1$ 和 $R_2$,那么:
它们的含义可以写得更形式化一些:
$$ \mathrm{Sem}(R_1 \mid R_2) = \mathrm{Sem}(R_1) \cup \mathrm{Sem}(R_2) $$
这个式子表示,选择结构的语义就是两个语言的并集。
$$ \mathrm{Sem}(R_1R_2) = {, w_1w_2 \mid w_1 \in \mathrm{Sem}(R_1),; w_2 \in \mathrm{Sem}(R_2) ,} $$
这个式子表示,串接的语义就是把左边语言里的任意字符串和右边语言里的任意字符串拼起来。
而 $R^*$ 表示由 $R$ 中若干个字符串顺次拼接形成的所有结果,并且包括重复零次的情况,因此空串总是在其中。
这套定义非常适合 lexer,因为 token 天然就是“某类字符串模式”。只要把 token 的定义写成正则表达式,lexer generator 就可以把它们转成可执行的识别过程。
理论上的最小正则系统已经够用了,但实际写 lexer 时,通常会加上一些语法糖,让规则更短、更直观。
例如,字符串 "foo" 可以看成 'f''o''o' 的简写。
$R+$ 表示一个或多个 $R$,等价于 $RR^*$。
$R?$ 表示零个或一个 $R$,等价于 $\varepsilon \mid R$。
字符范围如 ['a'-'z'] 表示其中任意一个字符。
补集形式如 [^'0'-'9'] 表示除了数字以外的任意字符。
这些扩展不改变表达能力,但会极大改善可读性。真正写语言规则时,几乎离不开它们。
关键字 if 的规则非常直接,就是:
"if"
一个数字可以写成:
['0'-'9']
整数字面量如果允许前面带可选的负号,可以写成:
'-'?['0'-'9']+
标识符则更典型。假设要求它必须以字母开头,后面可以接字母、数字或下划线,那么可以写成:
(['a'-'z']|['A'-'Z'])(['0'-'9']|'_'|['a'-'z']|['A'-'Z'])*

当规则逐渐变多时,把局部模式命名出来会更清晰。例如可以先定义:
lowercase = ['a'-'z']uppercase = ['A'-'Z']character = uppercase | lowercase这样后续表达式就不必反复展开一长串字符集合。对于真实语言的 lexer,这种“给正则片段命名”的能力非常重要,因为它能把规则从“能跑”提升到“能维护”。
字符串字面量是一个特别能暴露问题复杂度的例子。因为它不仅有起止引号,还可能包含转义字符。lexer 不能只看见一个 " 就草率地认为字符串开始或结束了,它必须区分“真正的结束引号”和“被转义的引号”。
假设字母表只包含 a、b、" 和 \。那么下面这些是合法字符串:
"abababab""\"""\\""\a"而这些是非法的:
"abaabaa""\"一个可行的正则表达式可以写成:
" (a | b | \(a | b | \ | "))* "
它表达的意思是:字符串以引号开始、以引号结束,中间可以重复出现普通字符 a 或 b,也可以出现反斜杠加上一个被转义的字符。
这里的关键不在于记住这个具体写法,而在于看到一件事:很多 token 的定义都牵涉边界条件,而正则表达式能把这些条件压缩成清楚、可组合的规则。 这正是形式化描述的价值所在。
即便单条正则表达式都写对了,lexer 仍然会遇到一个核心问题:多个规则可能同时匹配同一段输入的前缀。
例如输入是 ifx = 0。从开头开始看时,if 可以先匹配成关键字;但更长的 ifx 也可以匹配成标识符。这两个候选并不互斥,它们共享前缀。
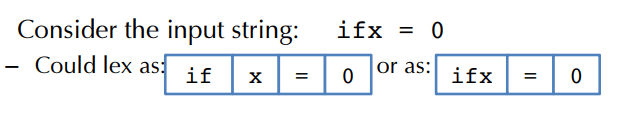
这说明仅靠“写出每个 token 的正则表达式”还不够,还必须定义冲突如何解决。大多数语言采用的策略是 longest match,也就是最长匹配:优先选择能吃掉更多字符的规则。对于 ifx,这意味着它会被识别成一个标识符,而不是关键字 if 再接一个 x。
但最长匹配也不是全部。如果两个规则匹配长度相同,还需要优先级。例如关键字和标识符往往都会匹配 if,这时通常让关键字优先。很多 lexer 工具会用规则出现的顺序来决定这种优先级:前面的规则权重更高。
因此,真正完整的词法分析规范通常不仅包含“每个 token 的正则表达式”,还包含两类附加约定:
第一,尽可能采用最长匹配。 第二,在同长度冲突时,用明确的优先级打破平局。
没有这两条,lexer 的行为就会变得不稳定,甚至无法和后续 parser 正确配合。
初看之下,词法分析像是编译器里最机械的一步。但真正做下去会发现,它并不简单,也绝不只是预处理。
它是编译器第一次从原始文本中恢复结构。要做好这一步,必须先清楚地定义 token 是什么,再处理规则之间的重叠、输入读取的前瞻需求、异常情况的定位,以及规则的长期可维护性。手写 lexer 可以工作,但成本高、风险大,规则一复杂就容易失控。
更稳妥的路线,是把词法规则变成一种形式语言描述问题:先把 token 看成字符串集合,再用正则表达式定义这些集合,最后交给 lexer generator 统一生成实现。这样做的价值不只是“省事”,而是把一个容易写乱的工程问题,变成一个语义明确、规则清晰、可自动化处理的形式化问题。
从这里再往后走,自然就会进入下一步:当字符流已经被切成 token,编译器如何继续把这些 token 组织成真正的语法树。这也是前端下一阶段,也就是语法分析要解决的问题。