高级计算机架构(四):看懂MIPSR10K处理器乱序执行核心机制
发布于 • 作者: Ethan
如果想真正理解今天高性能处理器的基本套路,MIPS R10K 是一个非常好的切入口。它诞生于 1990 年代中期,但很多今天仍在使用的核心思想,在它身上都已经相当成熟:寄存器重命名、乱序执行、按序提交、推测执行、精确异常,以及用一套很“克制”的数据结构把这些机制串成一个整体。
R10K 的厉害之处,不只是“会乱序执行”,而是它把前端取指、后端执行、寄存器状态管理和错误恢复分得很清楚。理解了这台机器,也就理解了现代处理器为什么要有物理寄存器文件、为什么 ROB 里不一定存值、为什么提交必须按序、以及为什么分支预测错了还能把状态收得回来。
R10K 是一台很激进的乱序超标量处理器。它不再一味靠更深的流水线去追时钟,而是把重点放在“让能做的指令尽快做起来”。前端每个周期最多抓取 4 条指令,借助分支预测持续喂给后端;后端则把整数、浮点和访存分别放进独立的动态队列中,让已经准备好的指令可以绕过还在等操作数的旧指令先执行。
它的整体结构已经非常接近今天常见的高性能 OoO 核心:前端有指令缓存、分支历史表和恢复取指用的缓冲结构;中间有重命名逻辑、映射表和活动指令跟踪结构;后端有整数单元、访存流水线和浮点流水线;而真正保存数据值的,是一大块物理寄存器文件。整数和浮点各自都有独立的物理寄存器集合,活动列表可以持续跟踪在途指令,多个 16 项队列把前端和执行单元有效解耦。
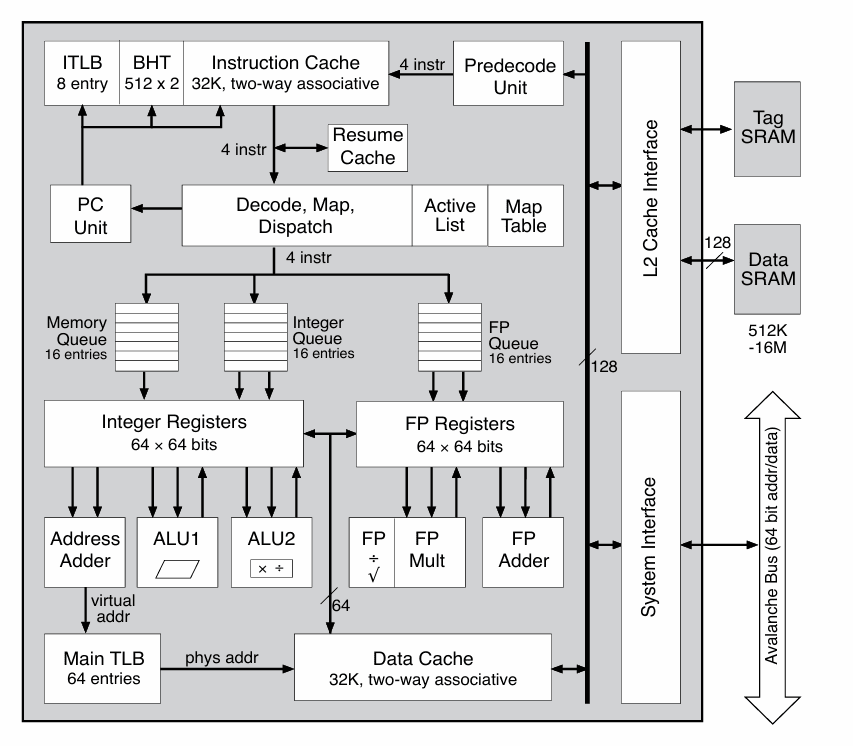
这种“深队列 + 动态发射”的设计有一个非常关键的效果:前端偶尔因为分支或缓存问题产生的小停顿,不会立刻把后端拖死。只要队列里还有已经就绪的指令,执行单元就还能继续干活。R10K 连分支预测失败后的恢复也做了专门优化,比如顺序路径指令不会立刻丢掉,而是暂存在一个小型恢复缓存里,用来减少误预测的代价。
R10K 最值得反复咀嚼的一点,是它几乎把“数据值”和“控制信息”彻底分开了。
在这台机器里,没有单独的架构寄存器文件来保存最终结果,也不会把执行结果再复制一份到 ROB 里。所有真正的数据值,都待在物理寄存器文件里。ROB、保留站和公共结果广播路径上,主要流动的是标签、映射关系、完成状态和控制信息,而不是一份又一份的数据副本。
这样做有几个直接好处。第一,数据通路更短,因为功能单元可以直接围着物理寄存器文件取数、写回。第二,ROB 和保留站可以做得更“轻”,不必承担大规模数据存储。第三,恢复状态时不必到处搬值,很多时候只要改回映射关系就够了。
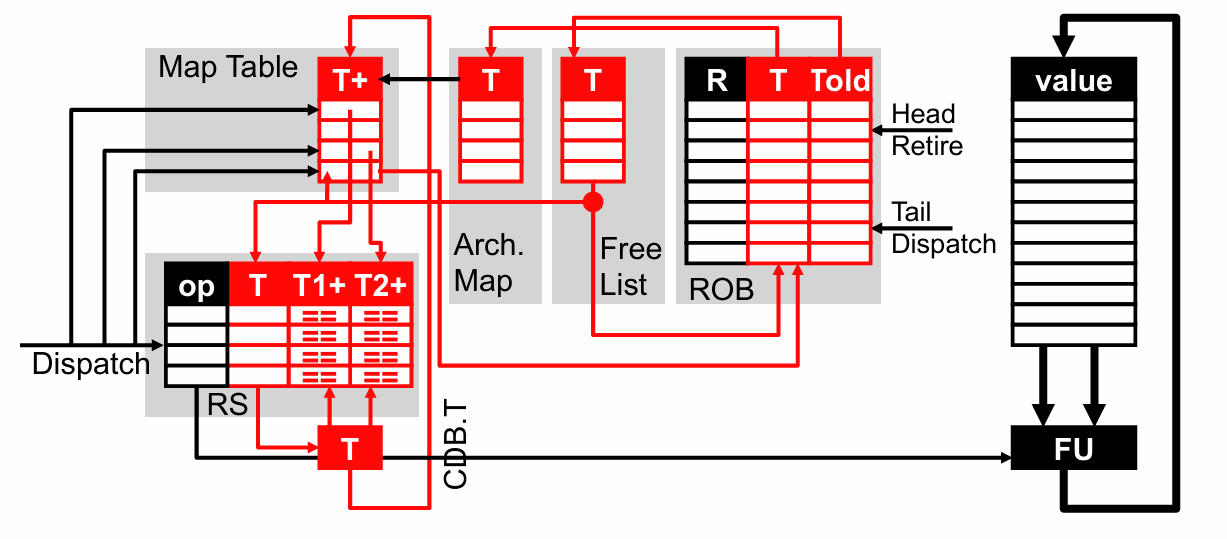
围绕这个思路,R10K 组织出了几类非常经典的数据结构:
Map Table 负责记录“每个架构寄存器当前映射到哪个物理寄存器”,并带一个就绪位,表示那个物理寄存器里的值是否已经可用。Architectural Map 记录已经提交的那一版映射,也就是对外可见的精确状态。Free List 维护当前还没被分配出去的物理寄存器。ROB 记录程序顺序、头尾指针,以及每条指令的新目标物理寄存器 T 和被它覆盖掉的旧物理寄存器 Told。保留站则只关心操作类型和标签,比如目标标签 T、源标签 T1、T2,以及这些源操作数是不是已经 ready。
这里有两个很有代表性的细节。第一,Map Table 永远不空,因为每个架构寄存器在任何时刻都必须指向某个物理寄存器。第二,ROB、保留站和广播网络里没有必要到处存值,因为真正的值一直在物理寄存器文件中。
寄存器重命名解决的,不是“真正的数据依赖”,而是名字带来的束缚。
假设有三条指令:
R1 <= R2 + R3
R2 <= R1 + R3
R1 <= R4 + R5
从程序文本看,第一条和第三条都写 R1,第二条又读 R1。可问题在于,第三条其实并不需要等前两条都做完才开始。阻碍它提早执行的,并不是数据真的没准备好,而是架构寄存器名太少,两个本来不同版本的结果都叫 R1。
重命名的做法很直接:每条有目的寄存器的指令,都拿一个全新的物理寄存器当输出位置。于是它们会变成不同版本的值,例如 R1a、R2b、R1c,互相不再因为“同名”而冲突。这样一来,写后写和写后读这类假相关就被拆掉了,处理器只需要遵守真正的读后写依赖。
在 R10K 里,这件事由 Map Table 和 Free List 配合完成。解码到一条写寄存器的指令时,先从 Free List 里拿一个新的物理寄存器作为 T,再把原来那个架构寄存器对应的旧物理寄存器记成 Told,最后更新 Map Table,让后续指令都看到新的映射。
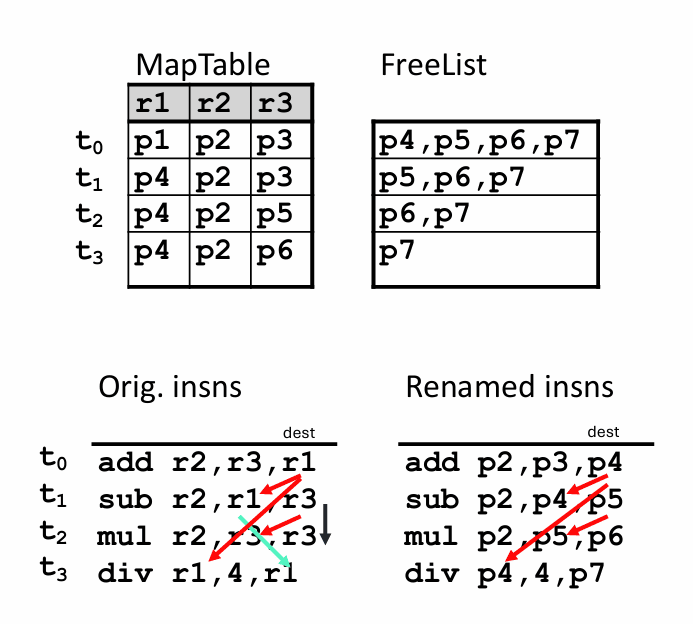
这样做带来的收益非常大。原本因为寄存器名冲突而不能变动顺序的指令,现在可能突然多出几种合法执行次序。长延迟指令也能更早开跑,不必被一些其实无关的名字冲突压在后面。与此同时,旧版本的值并不会立刻消失,因为更老的指令、错误恢复或者精确提交仍然可能需要它。
这也解释了一个常见问题:旧物理寄存器到底什么时候才能重用?答案不是“新映射一出现就能重用”,而是要等对应指令真正提交之后。因为在提交之前,体系结构上仍然可能需要回到旧状态,那时 Told 还必须是可恢复的。
R10K 可以概括成六个阶段:F、D、S、X、C、R,也就是取指、分派、发射、执行、完成、提交。
在 F 阶段,前端负责持续取指,并尽量用分支预测减少断流。
真正决定一条指令“进入机器内部后长什么样”的,是 D,也就是 dispatch。这个阶段首先检查结构资源够不够:保留站、ROB、访存队列和空闲物理寄存器只要有一个不够,就要停。资源够的话,就读取源寄存器当前对应的物理标签,把它们写进保留站;如果这条指令有目的寄存器,还要把旧映射保存为 Told,从 Free List 分配新的 T,并同时更新保留站、ROB 和 Map Table。
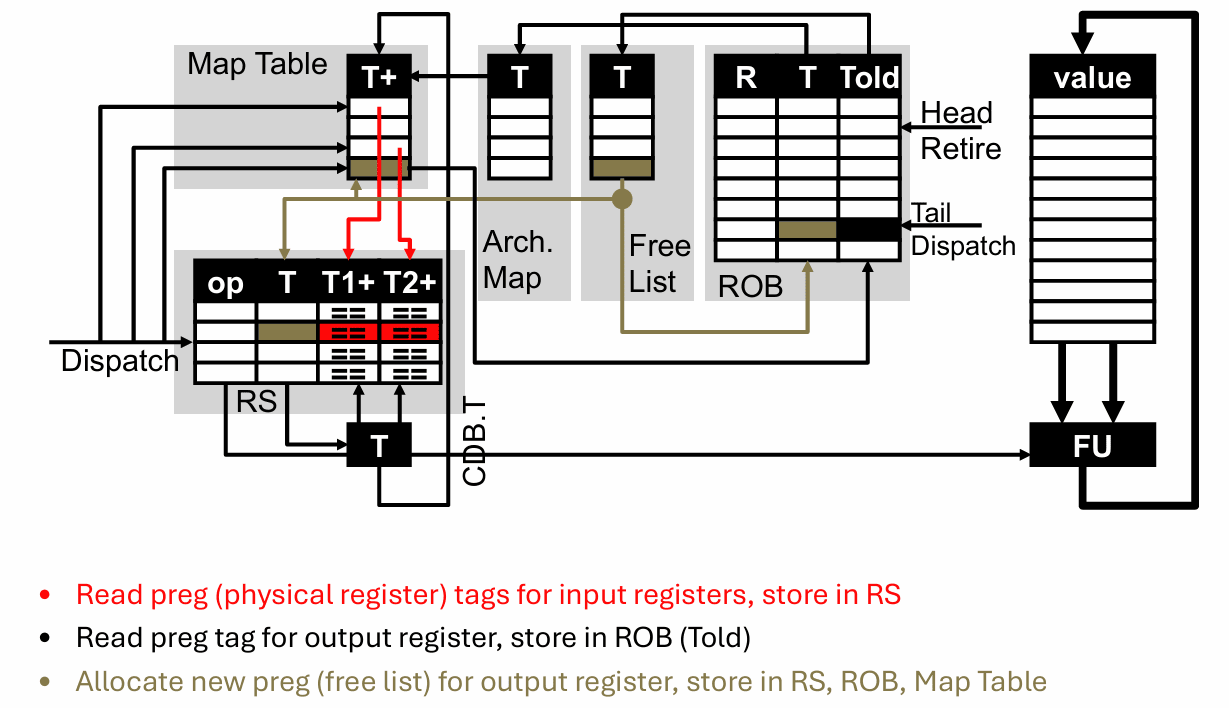
S 阶段是 issue。这里最重要的一点是:这些“队列”并不是严格 FIFO。指令并不会老老实实排队按顺序走到头,而是谁的操作数先准备好,谁就可以先被挑出来发给对应功能单元。也正因为这样,R10K 才能真正做到乱序执行。它的选择逻辑刻意没有做得过于复杂,只保留少量优先级规则,以免关键路径过长拖慢时钟。
X 阶段是 execute,各个功能单元按自己的节奏前进。整数 ALU 延迟短,访存要先算地址再访问缓存,浮点操作则可能跨多个执行阶段。不同长度的流水线同时存在,但前端和发射逻辑不需要为此停下来等“全局整齐”。
C 阶段是 complete。执行结果写入目标物理寄存器,同时把 Map Table 里对应条目的 ready 位置上。之后,凡是保留站里等这个标签的指令,都能立刻变成“已就绪”,准备进入后续发射。这一步非常能体现 R10K 的设计风格:广播的是标签命中,真正的数据已经在物理寄存器文件里了,不需要在 ROB 或保留站里再存一份。
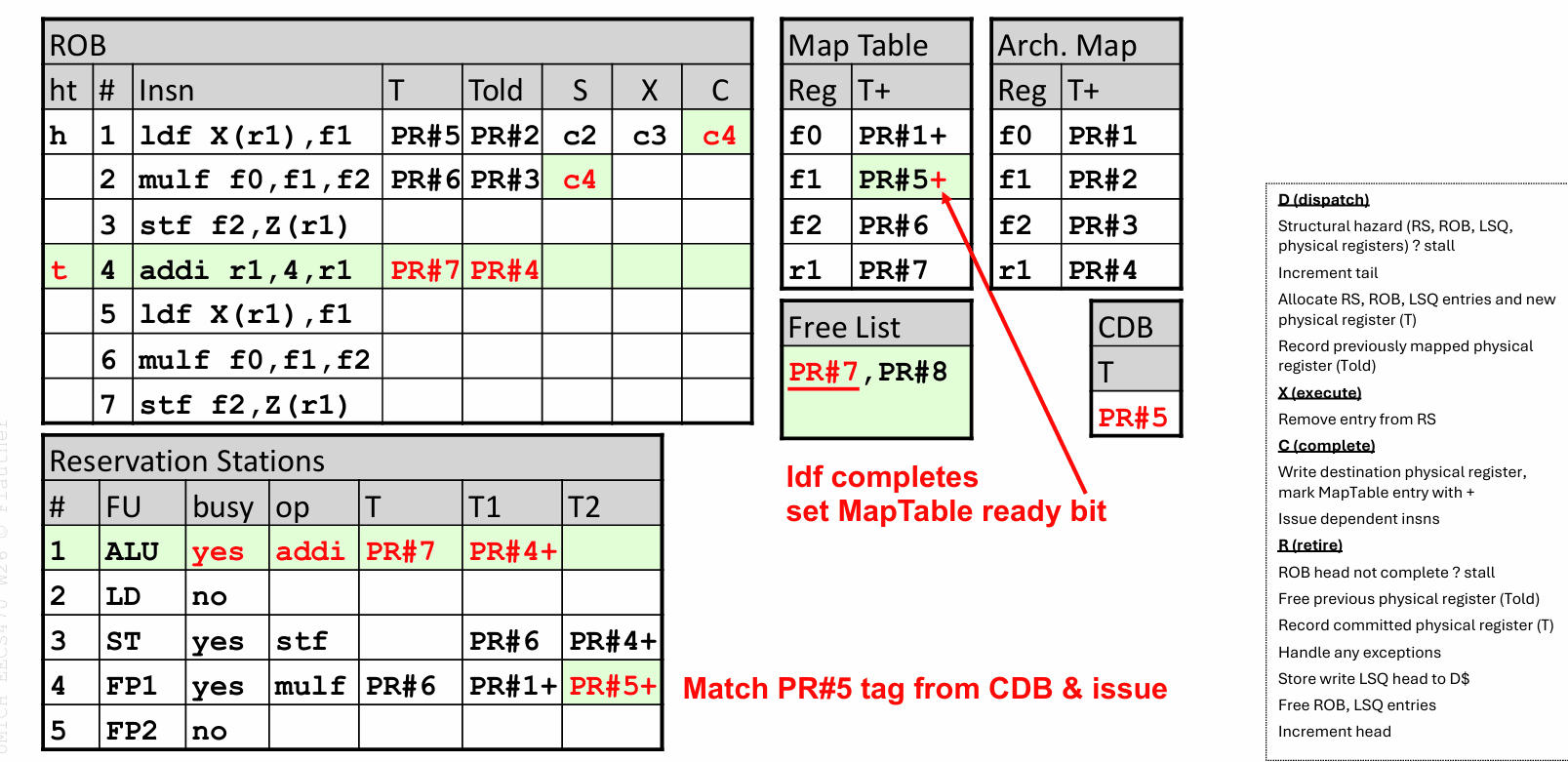
最后是 R,也就是 retire。提交必须严格按程序顺序进行:只有 ROB 头部那条指令已经完成,才能退休。退休时,要把新映射 T 写入 Architectural Map,把 Told 放回 Free List,把 ROB 和相关队列项释放掉;如果有异常,也是在这里保证处理器对外呈现出精确状态。至于 store,也是在接近提交的位置才真正把数据写入缓存,这一点对错误恢复尤其关键。
把这些规则放进一个具体流程里,会更容易看明白。
假设一开始 f0、f1、f2、r1 分别映射到 PR#1、PR#2、PR#3、PR#4,而 PR#5 到 PR#8 在空闲列表里。现在依次进入几条指令:先 load 到 f1,再做一次乘法写 f2,再 store,然后更新 r1,接着又来一条新的 load。
第一条 load 分派时,会为 f1 分配一个新的物理寄存器 PR#5,同时把原来 f1 的旧映射 PR#2 记进 ROB 的 Told 字段。此时 Map Table 里 f1 已经改指向 PR#5,但还没有 ready,因为值还没回来。
下一条浮点乘法要写 f2,于是又拿到一个新的目标寄存器 PR#6。它读取到的 f1 源操作数标签已经不是 PR#2,而是刚刚分给 load 的 PR#5。这说明重命名已经把“最新版本的 f1”传递给了后续依赖者,但乘法必须等 PR#5 真正 ready 之后才能发射。
store 是另一个很容易看出设计风格的例子。它会占用 ROB 和相关队列项,但不会分配新的物理寄存器,因为 store 并不产生一个新的寄存器结果。
当 load 完成时,PR#5 的 ready 位被置上,等待这个标签的乘法就会被唤醒。再往后,当这条最老的 load 退休时,Architectural Map 才正式把 f1 的已提交映射改成 PR#5,而旧的 PR#2 则回收到 Free List 中。这正是“完成可以乱序,提交必须按序”的具体体现。
乱序执行真正麻烦的,不是让快的指令先做,而是做完之后出了问题怎么收拾。
R10K 的答案非常漂亮:既然真正的数据值都在物理寄存器文件里,那么恢复精确状态时,很多时候不需要“把值搬回去”,只需要把映射关系恢复到正确版本即可。也就是说,关键不是改寄存器内容,而是改 Map Table、Architectural Map、Free List,以及 ROB 里记录的 T 和 Told。
这套机制让 R10K 在物理寄存器已经被乱序写入的情况下,依然能重建一个对外看起来完全按序的体系结构状态。
它支持两种恢复思路。一种是串行回滚:沿着 ROB 从年轻指令往回撤,一条条释放资源、归还 T、恢复 Told 对应的映射。这样做实现简单,但慢。另一种是检查点恢复:在关键位置提前保存一份映射状态,出错时一拍切回去,速度快,但代价是硬件很贵。
更有意思的是,这种取舍直到今天都还在。常见做法不是二选一,而是折中:高频发生的分支错误,尽量用检查点快速恢复;低频的中断、页错误之类,再走相对慢但面积更省的串行恢复路径。
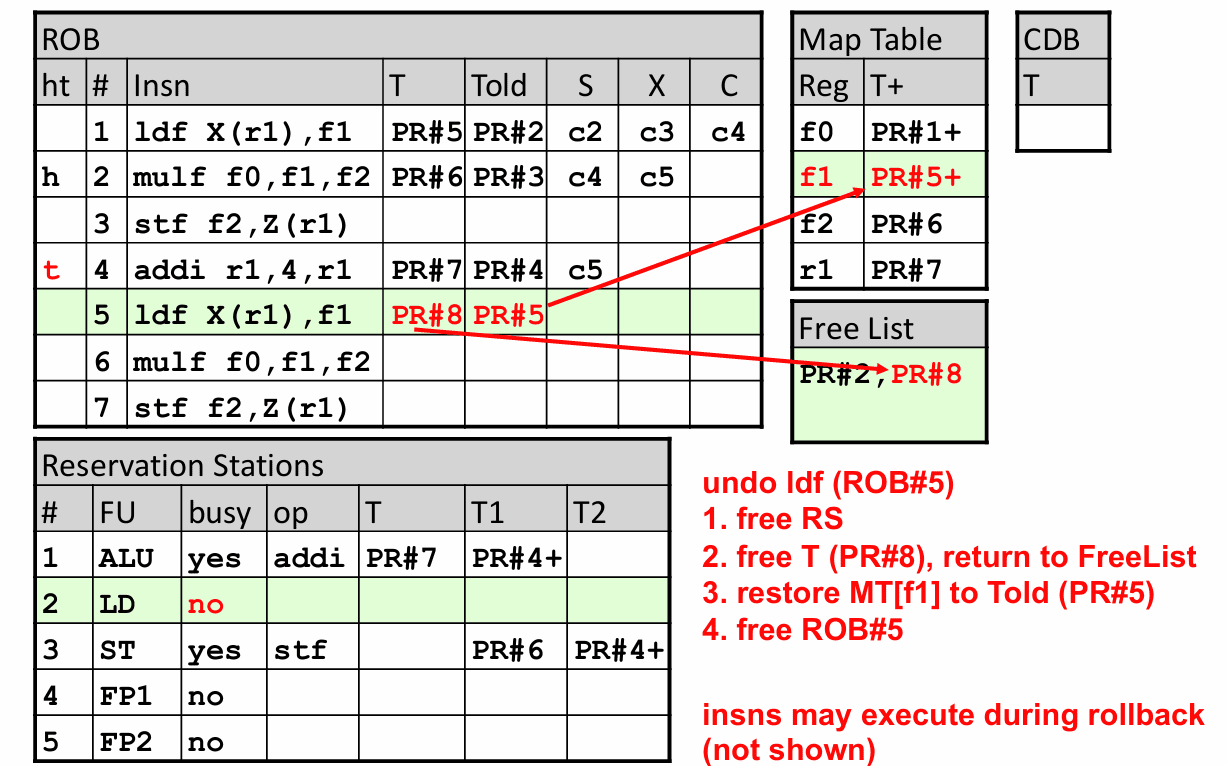
顺着前面的例子看,假如现在需要撤销几条年轻指令,处理器会先把最年轻那条未提交的 load 对应的保留站项释放掉,把它分到的 PR#8 放回 Free List,再把 Map Table 中 f1 的映射从 PR#8 改回 Told 里的 PR#5,最后释放对应的 ROB 表项。接着撤销 addi 时,也是同样的模式:归还它新占的寄存器、恢复旧映射、释放控制结构。
store 更能说明为什么“写内存要靠后”。如果一条 store 还没有退休,那么它还没有真正把数据写进数据缓存,这时撤销它只需要清掉队列和 ROB 项,不需要去“反写回”内存。精确状态因此变得可控很多。
今天再看 R10K,会有一种很强的既视感。很多后来被反复采用的基本结构,在这里都已经齐了:大物理寄存器文件、映射表、空闲表、保留站、ROB、按序提交、推测执行、分支恢复,以及“把数据和控制分开”的整体思路。
它当然也带着时代痕迹,比如一些队列规模、返回地址预测结构和恢复策略都还比较朴素,工艺上也曾被推到很紧的边缘,甚至出现过高频型号供应紧张和芯片问题带来的召回。但从微结构思想看,R10K 并不老。相反,它非常像一份后来许多高性能核心都反复参考过的蓝图。
理解这台机器之后,再去看今天的 OoO 处理器,很多看似复杂的机制都会突然变得顺理成章:为什么一定要重命名,为什么完成和提交要分开,为什么 ROB 里未必放值,为什么分支错误恢复本质上是在恢复“映射”,以及为什么一台机器能在内部大幅乱序,却依然对软件呈现出严格、精确、按序的结果。