高级计算机架构(三):指令级并行如何在现实处理器中一步步被限制
发布于 • 作者: Ethan
很多人第一次接触指令级并行时,直觉都是一样的:只要处理器一次能发更多指令,程序就会更快。真正的情况没有这么简单。指令之间的依赖、分支是否能提前预测、前端每周期能取多少条、后端每周期能发多少条、功能单元够不够,以及不同功能单元的执行延迟,都会一起决定最终能榨出多少并行度。
理解这件事最好的方式,不是背定义,而是盯着一个具体循环,看它在不同约束下怎么“长”出来。你会发现,ILP 不是一个固定数字,而是一层一层被瓶颈切掉之后剩下的结果。
这组图的阅读方法很统一。
同一种颜色表示第一次循环迭代中,在同一个周期发射的指令。带撇号的指令,比如 I0′、I1′,表示下一次迭代里的同名指令;颜色更深的区域则表示更后面的迭代。黑色箭头表示同一次迭代内部的数据依赖,红色箭头表示跨迭代依赖。整组图是逐步增加约束来观察效果:每多加一种现实限制,执行图就会多出新的停顿、新的拥塞点。
为了把重点放在并行性本身,前几张图做了刻意简化:只看执行阶段,先把大多数指令都当作单周期;在引入功能单元延迟之前,不考虑更复杂的多级流水;同时假设不会发生分支预测错误,而且循环后面一定还有下一次迭代。这样一来,图里出现的每一个空洞,基本都能明确归因到某个新增约束上。
这个例子是一段 16 条指令的循环体,里面同时用了 ALU、Load/Store、乘法和分支。大体可以分成几类:
前半段先做几次加载,再把数据送进加法、乘法和减法链路;中间有两条 store 把结果写回;后半段的 I11 到 I14 主要是在更新指针和循环计数,I15 则负责判断要不要跳回循环开头。带撇号的 I0′,就是下一次迭代的第一条加载指令。
这段循环最值得观察的地方在于:并不是所有指令都在同一条关键路径上。比如依赖加载结果的乘法和后续 store 很容易成为关键路径的一部分,但那些更新地址、更新计数的“准备动作”往往可以提前做。也正因为如此,不同迭代之间才有机会重叠执行。
不过有一个底线始终不能破:依赖关系的拓扑不能变。谁必须等谁,谁的结果被谁消费,这个形状是固定的。处理器可以改变指令出现的时间位置,但不能打破这张依赖网本身。
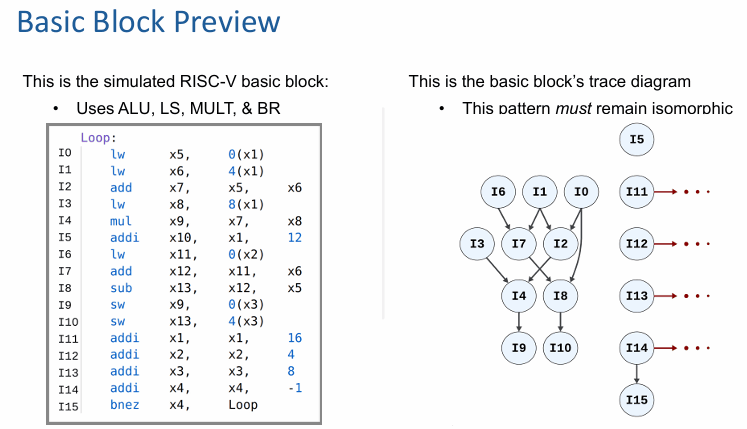
先看一个几乎“理想化”的处理器:取指无限宽、发射也无限宽,但遇到分支必须停下来等。
这时候最显眼的现象不是数据依赖,而是迭代之间出现了一道缝。上一轮循环快结束时,下一轮并不能立刻无缝接上,因为分支还没有给出结果。也就是说,就算前端和后端都足够豪华,分支本身仍然会制造空泡。
有意思的是,I11 到 I14 这种下一轮的准备指令仍然可以较早执行,因为它们不一定都压在最晚的控制依赖之后。但整个迭代之间的衔接,还是会被最后那条分支拉住。在 5 个周期的观察窗口里,这种配置能执行 39 条指令。

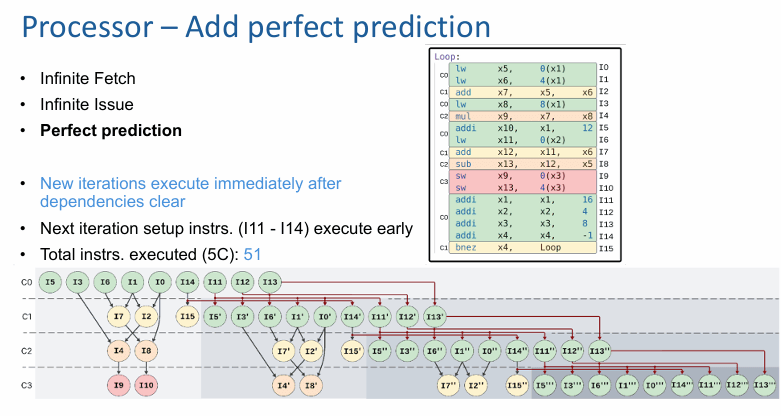
把上面的配置只改一件事:加入完美分支预测。
结果会非常直接。新的迭代不再需要傻等分支真正执行完,而是会在依赖一清空时尽快开始。原来那条卡在迭代边界上的“缝”明显缩小,循环体之间的重叠也明显增强。I11 到 I14 这些准备指令依旧能提早出现,但现在它们更容易和下一轮真正的计算部分拼成连续的流水。
在同样 5 个周期的观察窗口里,可执行指令数从 39 提高到 51。这个变化非常说明问题:很多时候,真正先把 ILP 压扁的,不是算术依赖,而是控制依赖。
接下来继续收紧模型。分支预测还是完美的,取指仍然可以看作无限宽,但发射宽度不再无限,而是每周期最多只能发 4 条。
这时新的瓶颈马上浮出水面:不是没有可执行的指令,而是一次塞不进去那么多。执行图里能看到,发射宽度几乎总是被填满,说明这时前端供给不是主要问题,真正挡住并行度的是“每周期最多发 4 条”这条硬限制。
一个很典型的细节是,I0′ 虽然已经被唤醒,但还是要因为发射宽度的限制再晚 1 个周期才能开始。第一轮迭代的完成时间也因此再往后拖了 1 个周期。在 9 个周期的观察窗口里,这种配置能执行 40 条指令。
这时候再把取指宽度改成 8,也没有变化,结果仍然是 40。原因不复杂:当发射宽度已经先把闸门关住时,前端把指令拿得更快并不会改变后端一次只能放行 4 条的事实。也就是说,超过后端吞吐上限的取指能力,在这一阶段基本白给。
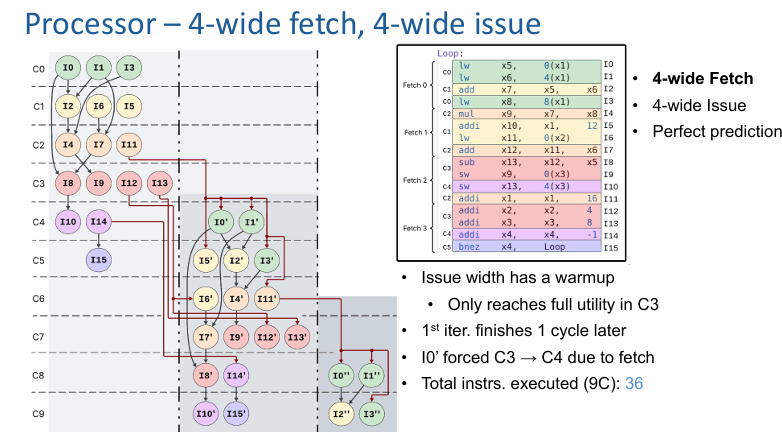
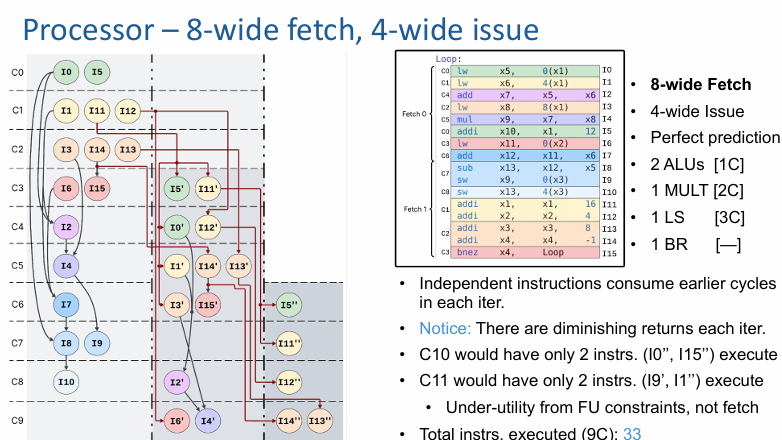
把配置改成 4-wide fetch、4-wide issue,情况就不一样了。
现在前端不再是“要多少给多少”,发射宽度开始出现明显的预热过程。前几个周期里,后端其实还没有被喂饱,要到 C3 左右,4-wide 的发射能力才真正被充分利用。原本在前一个模型里已经可以更早进入下一轮的 I0′,现在会被取指限制硬生生从 C3 推迟到 C4。第一轮迭代也因此晚了 1 个周期才收尾。
这一改动的结果,是 9 个周期内的可执行指令数从 40 降到 36。这里最值得记住的不是数字本身,而是判断方法:只有当前端供给速度开始影响后端的饱和时间时,取指宽度才算真正成了瓶颈。
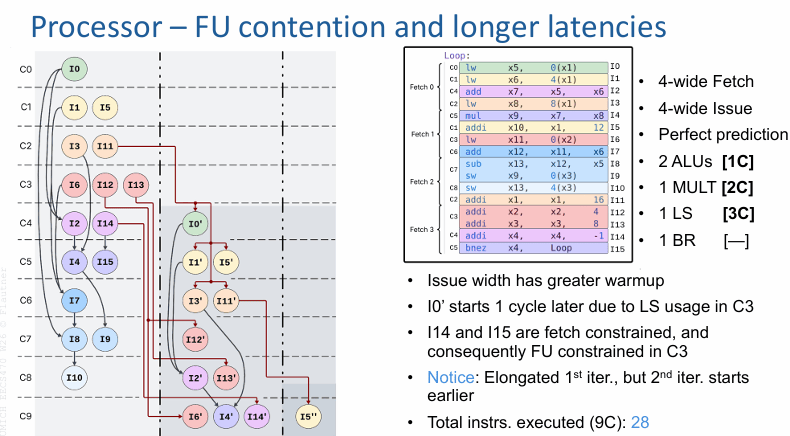
继续往现实世界靠,光有“每周期最多发 4 条”还不够,因为不同类型的指令还要抢不同的功能单元。
把资源限制设成 2 个 ALU、1 个乘法单元、1 个 Load/Store 单元和 1 个分支单元,马上就能看到另一个层次的拥塞。即使名义上的发射宽度还是 4,处理器也不可能在同一个周期里随心所欲地发所有准备好的指令,因为同类型操作会撞到同一个单元上。
这时候发射宽度的预热更明显了,要到 C5 之后才能比较稳定地接近满利用。I0′ 还会因为前一轮在 C4 已经占用了唯一的 Load/Store 单元,而被再往后拖 1 个周期。I14 和 I15 也会先受到取指约束,再在 C3 和 C4 受到功能单元可用性的二次约束。这样一来,9 个周期内可执行的指令数进一步降到 31。
这一步很关键,因为它说明“可并行”不等于“能同时落地执行”。图上看起来彼此独立的指令,到了真正发射的时候,仍然可能因为抢同一类硬件资源而排队。
如果再把“所有执行都当成单周期”这个简化拿掉,情况还会再变一次。设定为:ALU 延迟 1 周期,乘法 2 周期,Load/Store 3 周期,分支单元仍然单独存在。
这一变化有两个后果。
第一个后果是第一轮迭代被拉长了。尤其是加载和乘法不再立刻出结果之后,依赖它们的后续指令会更长时间地挂在空中,整条关键路径被明显拉长。
第二个后果更有意思:虽然第一轮更长了,但第二轮的开始反而可能更早。原因在于,一部分相对独立的工作会被更早地塞进前面的空隙里,于是“前一轮还没彻底结束”和“下一轮已经开始动起来”这两件事可以同时成立。
在这个更真实的模型里,I0′ 会因为 C3 上的 Load/Store 使用而再晚 1 个周期开始;I14 和 I15 则会在 C3 先受到取指约束,随后又受到功能单元限制。最终,9 个周期里能执行的指令数降到 28。
有,但不是无限有。
在前面的更真实模型上,把取指宽度从 4 提到 8,而发射宽度仍然保持 4,独立指令确实会更早地吃掉每次迭代前面的空档。结果也能看到改善:9 个周期内可执行指令数从 28 回升到 33。
但这不是线性增长,更不是“取指翻倍,性能也跟着翻倍”。随着迭代继续往后推,收益会越来越小。后面的周期里,即使理论上还能继续执行,单个周期里也只剩下很少几条指令可放:例如 C10 只会执行两条,C11 也只会执行两条。此时的低利用率,已经不是因为前端拿不到指令,而是因为后端功能单元和执行延迟共同决定了并行窗口的形状。
换句话说,更宽的取指能把“能提早准备的东西”更早准备好,但它救不了那些天生受限于功能单元数量、操作类型冲突和长延迟依赖链的部分。这就是为什么在更真实的模型里,8-wide fetch 有帮助,但很快就会碰到边际收益递减。
这一整串变化,实际上是在回答同一个问题:为什么“更宽”不总是“更快”?
先是分支把迭代切开;分支问题缓解后,发射宽度变成上限;再往下看,取指宽度只有在前端真喂不饱后端时才重要;继续逼近现实后,功能单元数量决定了许多指令虽然独立,却不能同周期发射;最后,真实执行延迟把关键路径重新拉长,让瓶颈从“宽度不够”进一步变成“依赖链太长、资源冲突太多”。
所以,ILP 不是“处理器有多宽”的简单函数,而是控制流、数据依赖、前端带宽、后端资源和操作延迟共同塑造出来的结果。真正有价值的优化,永远不是盲目加宽某一个环节,而是先看当前最先把图压扁的到底是哪一个约束。
当你能从执行图里一眼看出“空洞是分支造成的”“拥塞是发射宽度造成的”“拖延是 Load/Store 单元冲突造成的”“边际收益递减是后端限制造成的”,你就不只是在看一张课上示意图了,而是真的开始理解 ILP 是怎么在现实处理器里被一点点榨出来的。