高级计算机架构(七):乱序执行中的内存依赖与LSQ原理解析
发布于 • 作者: Ethan
现代乱序处理器之所以快,很大程度上靠的是“先做能做的事”。寄存器相关性可以靠重命名拆开,但一碰到内存,事情立刻复杂起来:一条 load 到底能不能先跑?它读到的值应该来自 cache,还是来自某条更老的 store?一条还没退休的 store,又为什么不能直接把数据写进内存?
把这些问题兜住的核心结构,就是 Load-Store Queue,简称 LSQ。理解它,基本就抓住了乱序执行里内存系统最关键的一层。
寄存器之所以容易管理,是因为目标很明确:在重命名阶段就知道自己读写的是哪个逻辑寄存器。但内存不是这样。指令在进入流水线时,往往还不知道最终地址,地址通常要等到执行阶段,甚至在乱序机器里,相关指令的地址和数据会以完全不同的顺序准备好。
这带来三个直接问题。
第一,内存地址没法像寄存器那样在重命名阶段提前“改名”。处理器在 dispatch 时还不知道 [base + offset] 最后会落到哪里。
第二,内存访问有不同宽度,可能是字节、字、双字,彼此还可能重叠,所以不能只看“是不是同一个地址”,还要考虑访问范围是否交叉。
第三,如果没有专门的内存排队结构,最保守的做法只能是在乱序核心里一次只允许一个 load 或 store 飞行,其他相关指令在 dispatch 处就要被堵住,性能会明显塌掉。
LSQ 可以理解成乱序核心和数据缓存之间的“内存秩序维护者”。它的任务不只是排队,而是同时完成几件事:
它要解析 load 和 store 之间的依赖关系。因为只有地址真正算出来以后,处理器才知道两条指令是不是访问同一块内存。 它要管理地址和数据的异步到达。比如 store 的数据先准备好、地址后准备好,或者反过来,LSQ 都得接住。 它要保护内存不被推测写坏。还没退休的 store 不能直接改写 cache 或内存,否则一旦分支预测错误,错误路径上的写入就“污染”了机器状态。 它还要支持并发内存访问,以及最重要的一件事:store-to-load forwarding,也就是把较老 store 的值直接转发给较新的 load,而不是傻等它真的写到 cache 里。
因此,内存指令会按程序顺序进入 LSQ。后来的 load 只能从两个地方拿值:要么来自更老的 store,要么直接来自内存层级。与此同时,store 即使已经执行完成,也只是把地址和数据写进队列;只有当它退休并走到队头时,才真正提交到数据缓存。这样一来,推测执行和精确异常都能被正确维护。
在一些情况下,如果一条更晚的 store 会覆盖同一位置,较早、尚未对外可见的 store 甚至可能变得多余。也就是说,LSQ 不只是“等一等”,它还会帮处理器减少不必要的内存写流量。
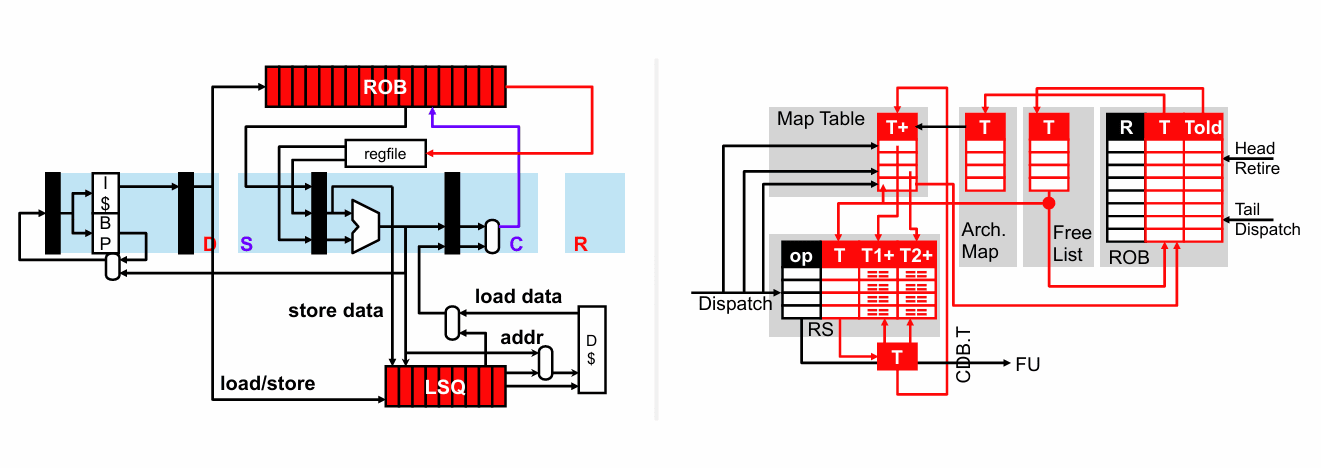
最直接的做法,是先只用一个 Store Queue,也就是把 LSQ 的核心先做成“只重点盯 store”。
这里的基本规则很清楚:
store 在 dispatch 时按程序顺序分配一个 SQ 表项; 到了执行阶段,把地址和数据写进对应槽位; 等到退休时,只允许队头的 store 把内容真正写入数据缓存,然后释放这个槽位。
load 的处理方式则更谨慎。它在 dispatch 时会记住“自己前面当时有多少个 store”,也就是自己的 load position。等它准备发射时,处理器必须先确认:所有比它更老的 store,至少地址都已经明确了。只有这样,load 才能安全执行。
执行时,load 会把自己的地址同时送给数据缓存和 SQ。SQ 会像内容寻址存储器那样,对所有 store 地址做并行比较;如果命中了多个地址,就选择“比这个 load 更老、但又离它最近”的那条 store,把值直接转发过去。如果一个都没命中,load 再去拿 cache 返回的数据。
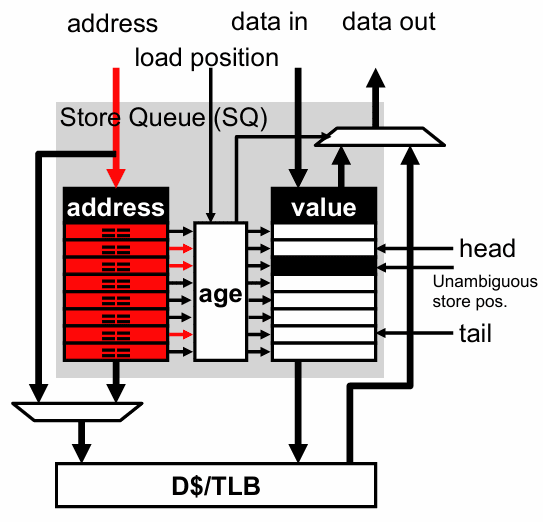
这种方案的好处是结构直观,恢复逻辑也相对简单。load 之间仍然可以乱序,store 之间也可以乱序准备好地址和数据。真正被限制住的是:load 不能越过那些地址尚未明确的更老 store。
问题也正出在这里。这个限制很安全,但常常太保守了。现实里,大多数 load 最后根本不会从 SQ 转发数据。
经验上,真正需要从 store queue 转发数据的 load 占比并不高,平均往往不到一成。换句话说,很多 load 其实被“白白等住了”。
这就引出了更激进的做法:除了 SQ,再加一个 Load Queue,也就是完整的 LSQ 结构。思路很简单——即使前面还有地址不明确的老 store,load 也先跑。大多数时候它会跑对;少数跑错的情况,事后再检测、再恢复。
为了做到这一点,LQ 也按程序顺序分配表项,并且支持关联搜索。规模通常会做到 ROB 的约 20% 到 30%。 load 在 dispatch 时分到一个 LQ 槽位,执行时把自己的地址写进去。 store 在 dispatch 时会记住当前的 LQ 尾指针,等于给自己留下一个“分界线”:这个位置之后进入的 load,都是它的后辈。
真正关键的动作发生在 store 执行时。此时 store 的地址终于算出来了,它会拿这个地址去搜索整个 LQ:如果发现某个更年轻的 load 已经抢先执行过,而且地址相同,那就说明发生了 memory ordering violation,也就是内存顺序违规。
这类错误的本质是:load 跑得太早了,提前从 cache 读了值,但后来发现本该先看到的是一条更老 store 写入的内容。处理器必须恢复,典型做法是通过 ROB 记录异常或违规信息,选择最老的违规 load 作为恢复起点,随后 flush 并重新取指、重新执行。
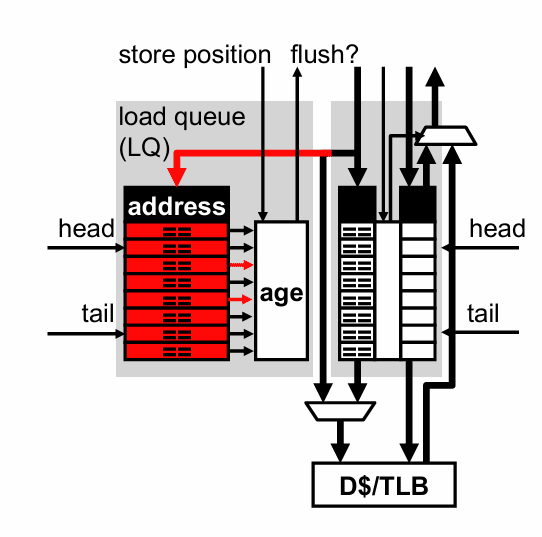
这就是机会主义调度的核心:先赌大多数不会冲突,少数赌错了再回滚。
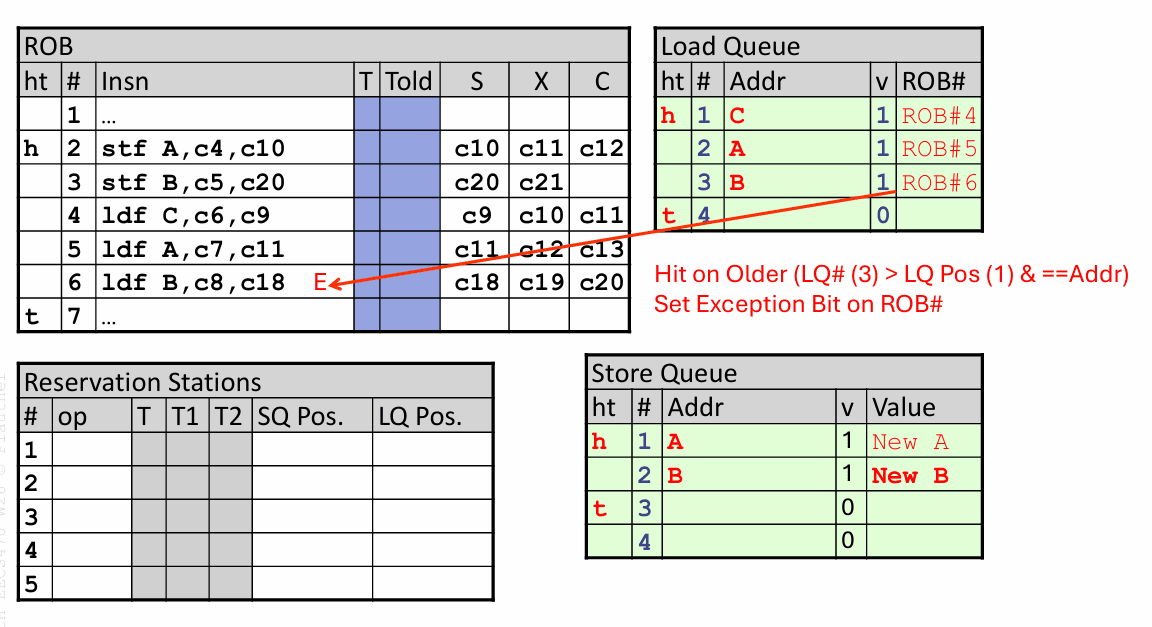
把 ROB、保留站、SQ 和 LQ 放在一起看,这个过程会更清楚。处理器里常见的做法,是在保留站里给每条内存指令额外记录 SQ 位置和 LQ 位置,这样执行阶段才能快速判断“谁比谁老”。
假设程序里先后出现两条 store 和三条 load,分别访问 A、B、C 三个地址。这个例子很能说明 LSQ 为什么必须同时支持转发和违规恢复。
先看访问 C 的那条 load。它执行时,SQ 里虽然有更老的 store 在飞行,但没有任何已知地址与 C 匹配,所以它直接从 cache 里拿到值。
再看访问 A 的那条 load。等它执行时,较老的 store A 已经把地址和数据写进了 SQ,于是 load 命中这个更老的表项,直接从 SQ 转发得到 New A,根本不用等 store 真正退休写入 cache。
最后看访问 B 的那条 load。它执行时,store B 还没算出地址,所以它暂时看起来“像是安全的”,于是先从 cache 读到了旧值 B。
问题出在后面:等 store B 的地址和数据终于就绪,它去扫描 LQ,发现那条更年轻的 load B 早就跑过了,而且地址完全相同。于是处理器立刻知道,刚才那次读取是错的。
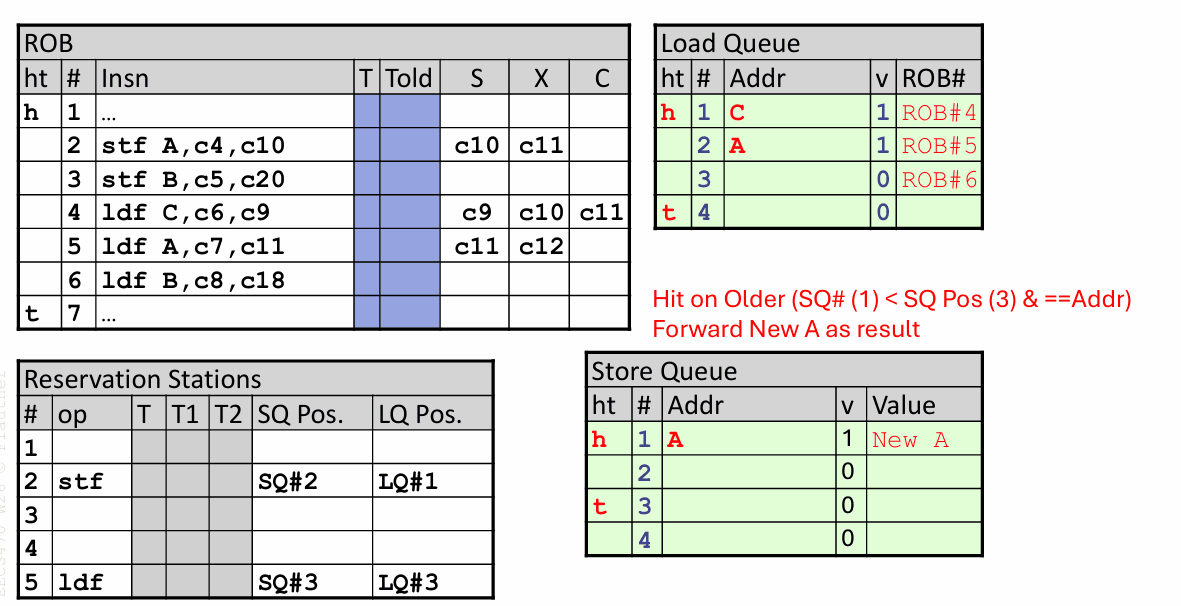
接下来,ROB 会把这件事当成一条需要精确处理的违规事件保留下来。与此同时,store 仍然要按退休顺序提交:前面的 store A 先提交,store B 再提交。等违规的 load 走到合适的恢复点时,处理器再统一处理异常,冲刷流水线,并让那条 load 重新执行。
这也解释了一个常被忽略的事实:机会主义调度虽然平均更快,但一次 flush 的代价通常比单纯“多等几拍”要昂贵得多。
既然保守调度太慢,机会主义调度又可能带来高代价回滚,更合理的方向就是折中:只对“容易出事”的 load 保守,其余的继续大胆乱序。
这背后的观察很重要:会产生违规的 load/store 关系,往往是稳定的。它通常由程序本身决定,而不是每次运行都完全随机变化。也就是说,内存依赖是可以预测的。
因此,更高级的 LSQ 设计会加入 Intelligent Load Scheduling,也就是智能 load 调度,或者更具体地说,内存依赖预测。它不要求一个 load 等所有老 store,只尝试预测“它真正需要等哪一条”。
经典方法之一是 Store Sets。可以把它理解成两张表配合工作:
第一张表记录“某条 load 往往依赖哪类 store”,也就是从 load 的 PC 映射到 store 的 PC。 第二张表记录“这个 store 最近一次动态实例现在在 SQ 的哪个位置”,也就是从 store 的 PC 映射到最新的 SQ 索引。
这样一来,load 就不用盲等所有老 store,而是只等那个最可能与自己冲突的目标。这个方向比单纯的保守或机会主义都更精细,复杂度更高,但能明显减少无谓等待和高代价回滚。类似思路也确实进入过实际处理器设计,Pentium 4 就是一个经典例子。
从表面看,LSQ 像是一个给 load 和 store 排队的结构;但真正重要的是,它在乱序执行里同时解决了三个互相冲突的目标:既要快,允许尽可能多的内存操作并发;又要准,保证 load 读到的值符合程序顺序;还要安全,确保推测路径上的 store 不会提前污染内存。
只用 Store Queue,逻辑简单但会把很多本可提前执行的 load 挡住。再加上 Load Queue,处理器可以更激进地前冲,但必须承担违规检测和恢复的成本。再往前一步,就进入了预测驱动的智能调度:不是所有 load 都一视同仁,而是让处理器逐渐学会“谁该等,谁可以先跑”。
这正是现代微架构最有意思的地方:性能从来不是靠一条规则硬推出来的,而是在“尽量大胆”和“绝不出错”之间,不断做出越来越聪明的折中。