高级计算机架构(六):宽指令取指:现代处理器前端为什么越来越难做
发布于 • 作者: Ethan
一台处理器能不能把宽发射、乱序执行、多个功能单元真正喂饱,关键往往不在后端,而在前端。后端再宽,取不到足够多、足够连续、足够正确的指令,吞吐量就上不去。理解宽取指,真正要看的不是“每周期能取几条”这句口号,而是前端如何同时处理分支预测、错误恢复、跨块取指、多分支路径、对齐整理,以及各种为带宽而生的缓存结构。
更麻烦的是,程序并不是一条直线。整数代码的基本块平均往往只有 4 到 6 条指令,浮点代码也常常只有 6 到 10 条。对一台希望每周期取很多条、发很多条的处理器来说,这意味着前端几乎一直在碰到分支边界。单纯把 I-cache 块做大,并不能自动解决问题。真正的难点集中在三件事上:一次周期里要不要预测多个分支、能不能同时从多个取指组里拼出连续指令流,以及这些指令取回来之后怎样对齐、压缩、送进解码与派发。
宽前端最先撞上的问题,是分支预测来不来得及。
高精度分支预测器通常很大、很复杂,准确率高,但访问延迟也高,甚至可能需要多个周期才能给出预测结果。问题在于,前端等不起。于是实际设计里常见一种折中思路:先用一个更快、更简单的预测器尽早给出“初判”,让取指先动起来;随后再由更慢但更准确的预测器复核。如果两者意见不一致,再靠误预测恢复机制修正。这么做的意义不只是提高准确率,更重要的是把“预测结果出现的时间”往前挪。对宽前端来说,早一拍往往比高一点点准确率更值钱。
可一旦把预测器做成流水化结构,又会遇到另一个问题:分支历史寄存器必须几乎立刻反映最新分支的结果,后面的预测才不会落后。也就是说,预测不仅要准,还要能在非常短的时间里不断滚动更新。前端里很多复杂设计,本质上都是在解决这件事:先大胆推测,让机器不停;一旦发现推测不对,立刻回滚。
误预测恢复速度因此变成了一个核心参数。恢复时要尽快清掉所有比该分支更年轻、却走在错误路径上的指令,而且清理范围非常广:ROB、LSQ、重命名映射表、保留站、取指/派发缓冲区都要一起修正。恢复 PC 时,如果原先误判为“不跳转”,就必须改去真实的分支目标地址;如果原先误判为“跳转”,则要回到顺序下一条地址。恢复完成后,前端才能沿着正确路径重新开始投机执行。
这也是为什么分支误预测代价会直接影响流水线深度的最佳点。流水线加深可以提高频率,但每次误预测都会把更深的前端和更多级流水一起打断;恢复越慢,深流水的收益就越容易被吃掉。
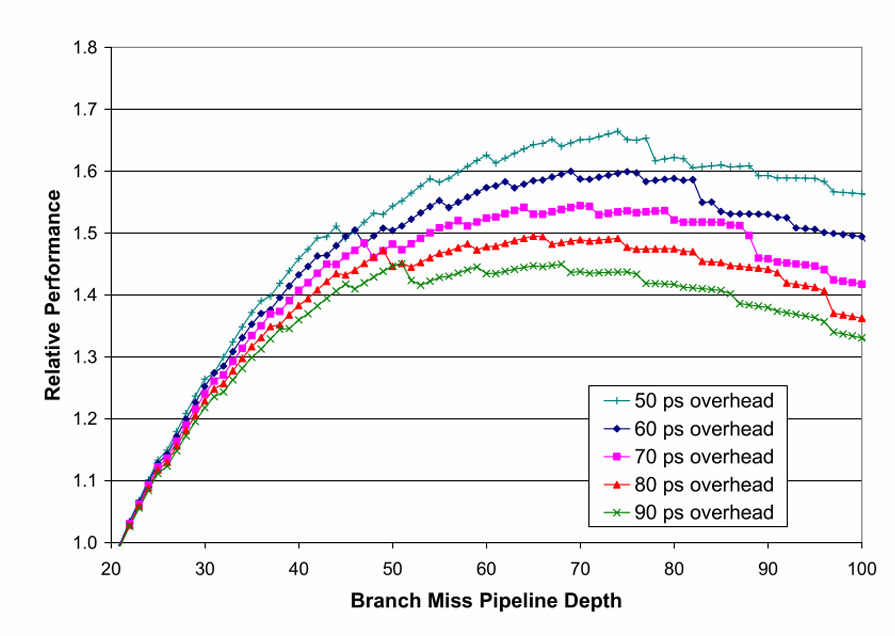
想让恢复足够快,一个很有效的办法是:每遇到一个分支,就把恢复所需的关键状态保存一份。
具体做法可以理解成一个分支栈。指令进入派发阶段时,只要遇到分支,就分配一个分支栈项;如果分支栈满了,前端就只能停下来。分配时要同时保存恢复所需的状态快照,包括重命名映射表、空闲物理寄存器列表、ROB 尾指针、LSQ 尾指针、恢复 PC,以及修复分支预测器所需的信息。这样一来,这个分支一旦被确认误预测,就不需要“慢慢推理之前的状态是什么”,而是直接把快照拿回来用。
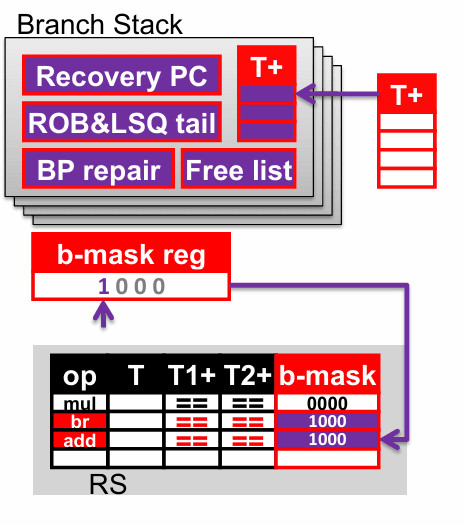
但光有快照还不够,还得知道哪些年轻指令依赖于哪些尚未解析的旧分支。一个常见办法是给每条在飞指令都带一个分支掩码,也就是 b-mask。它记录了这条指令前面还有哪些分支没有最终确认。分支一进入机器,就占用 b-mask 的一个比特位;之后所有更年轻的指令,都会把当前 b-mask 复制进自己的条目里。这样,依赖关系就被编码成了一个很简单的位向量。
一旦某个分支被证实误预测,恢复动作就能非常直接地展开。ROB 和 LSQ 的尾指针恢复到该分支对应的检查点;映射表和空闲列表也恢复到快照版本;保留站和功能单元流水线里,凡是 b-mask 对应位为 1 的年轻指令,全部清掉。最后释放这个分支栈项,把对应的比特位置空出来。由于每个未决分支各占一个独立比特位,这种方法天然支持嵌套分支,甚至能处理“错误路径里还有更年轻分支”的情况。
如果分支最后被证实预测正确,处理方式就温和得多:清掉它在 b-mask 里的对应位,释放分支栈项即可。这也解释了一个很容易被忽略的现象:即使预测一直正确,分支在“被确认正确”之前,仍然会占着前端资源不放。如果分支解析延迟很长,未决分支会在前端层层堆积,最后可能形成结构性阻塞。
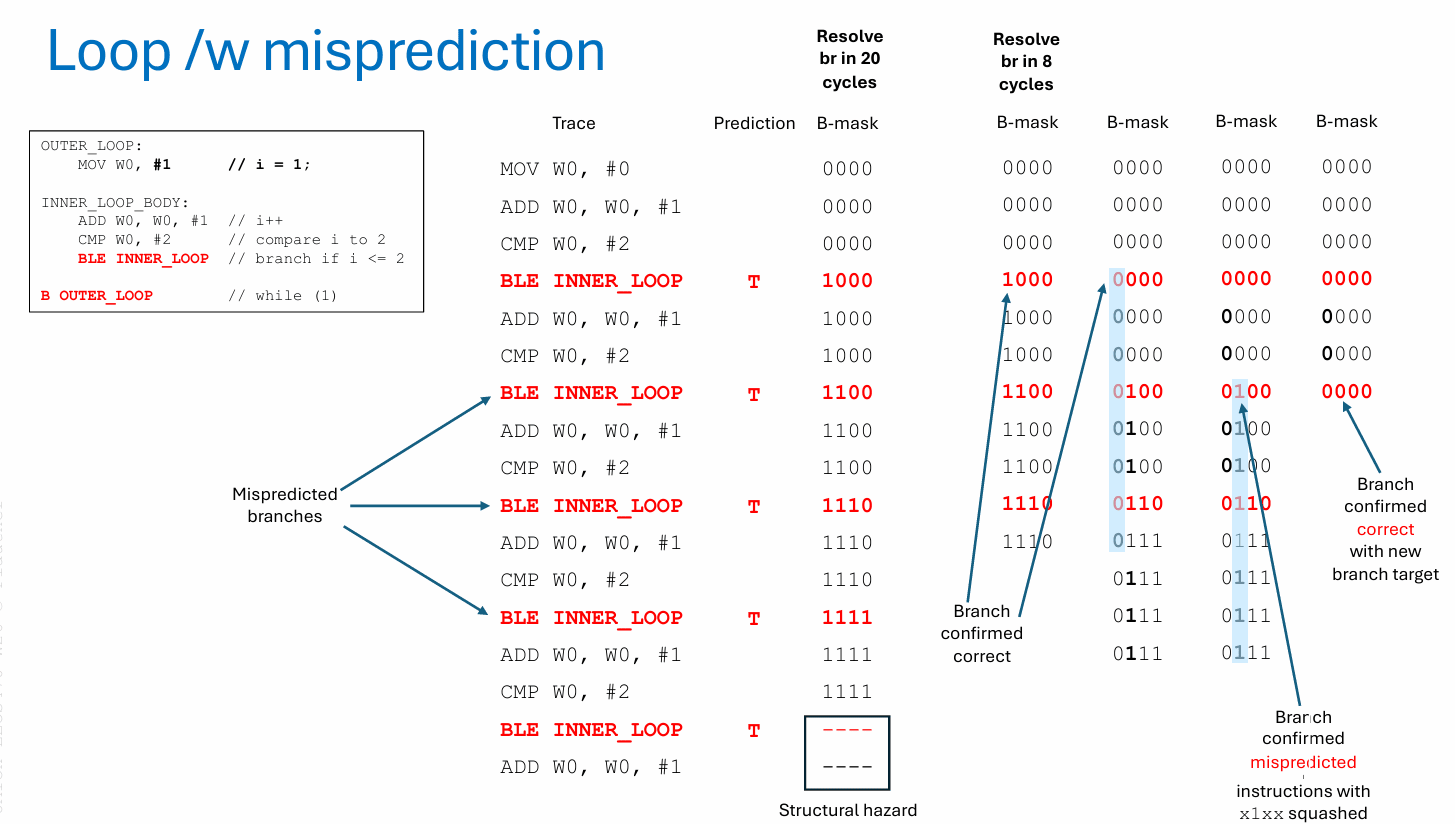
把这个机制放进一个小循环里看,会更直观。假设前端持续预测循环回边会被取走,那么每遇到一个新分支,b-mask 上就会多一个活跃位。分支解析得快,这些位很快就能被清掉;分支解析得慢,活跃位就越积越多,直到分支栈满,前端不得不停顿。若其中某个较老分支后来被确认误预测,那么所有 b-mask 中该位仍为 1 的年轻指令,都会被整体冲刷掉,取指随即切回修正后的目标路径。
先看最容易的一种情况:如果一个周期内要取的多条指令刚好都在同一个 I-cache 块里,事情并不复杂。但只要这些指令跨了块边界,前端就需要同时取相邻的多个块,再把它们拼接起来。这通常意味着分银行 I-cache、额外的组合网络,甚至为了不拖慢时钟而再插入新的流水级。
编译器当然可以帮忙,比如把基本块尽量对齐到 cache line 边界上,甚至插入 no-op 填充布局。但这种做法的代价也很明显:有效指令缓存容量会下降,取指带宽也会被无意义的填充浪费掉。对高性能前端来说,这通常不是根治之道。
真正让宽前端头疼的,是非顺序取指。最简单的设计往往是“每周期只预测一个分支,而且不支持同一周期跨多个被取走的分支继续取”。这样一来,如果本周期里预测某个分支会跳转,那么分支之后顺序位置上的那些同周期取回指令,很多都要被扔掉。有效取指宽度马上缩水。
这个损失并不小。假设程序里大约 20% 是分支,而分支中有一半会被取走,那么平均大约每 10 条指令就会碰到一次被取走的分支。现在再假设机器本来是 8 发射,一个循环体正好 10 条指令。如果前端只会“一次看一个分支”,那它很可能第一拍取到 8 条,第二拍却只能再取到剩下的 2 条,平均下来只有 5 条/周期,根本喂不满 8 发射的后端。编译器通过循环展开可以降低被取走分支的频率,但这只能缓解,不能替代硬件前端本身的能力。
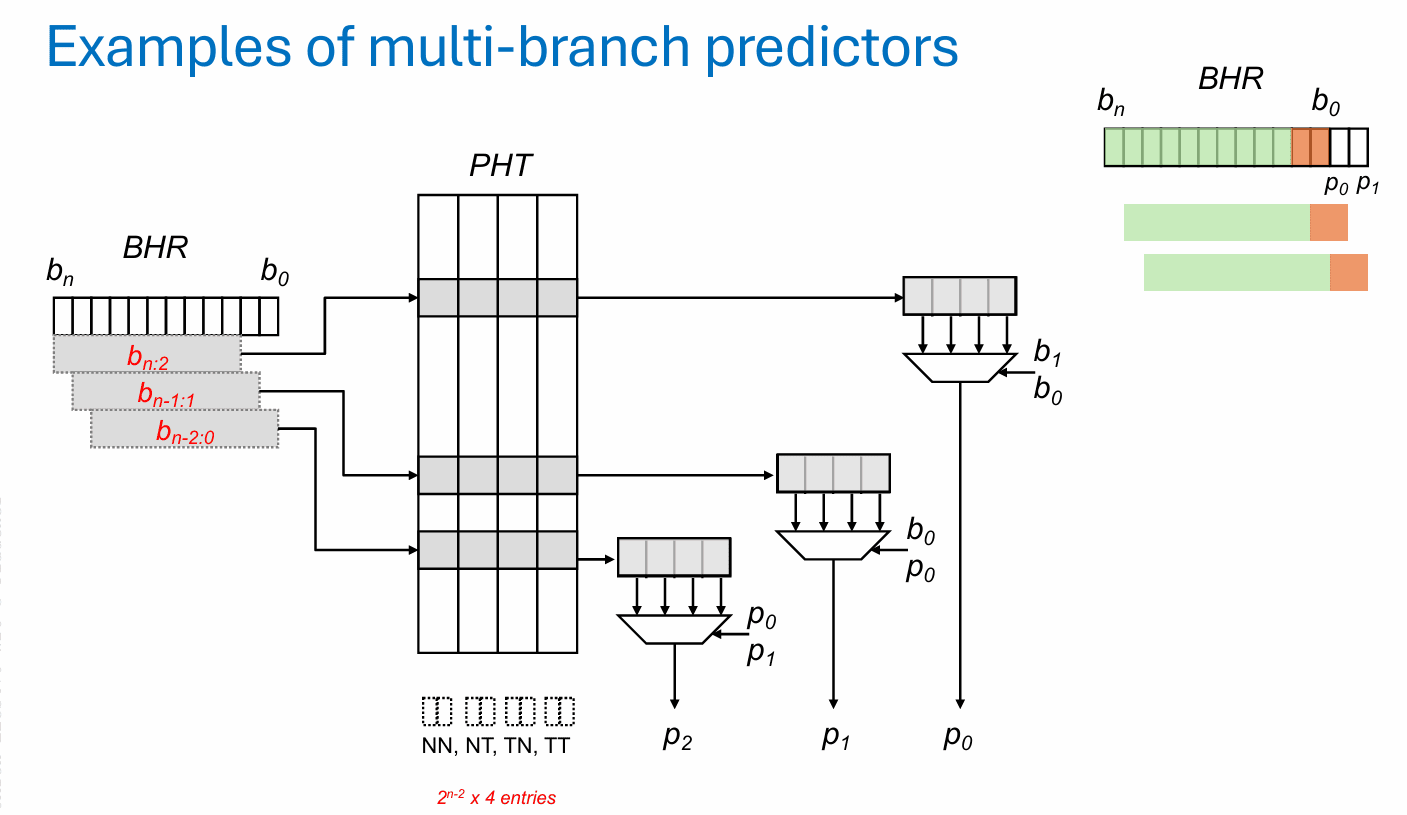
要把宽取指做上去,前端往往希望一个周期里处理不止一个分支。但多分支预测并不是把单分支预测器简单复制几份。
第一层困难是延迟。如果后一个分支的预测建立在前一个分支的结果之上,那么串行做多个预测会直接拉长关键路径。第二层困难是历史污染。后面的预测需要使用分支历史,而这段历史本身又可能还处在推测状态,既可能过旧,也可能将来被回滚。第三层困难则是准确率会连乘下滑:一个分支 95% 的预测率看起来不错,但连续三个相关分支串起来,整体正确率只有大约 85%。
因此,多分支预测器往往会尝试一次性给出多种“可能路径”下的预测结果。可以把它理解成这样一种问题:如果前一个分支判为不跳转,后一个该怎么预测?如果前一个判为跳转,后一个又该怎么预测?于是预测器不再只输出一个 bit,而是并行为多种路径分支情况准备多个候选预测。这样可以缩短串行依赖,但新的难题马上出现:分支真正解析之后,究竟该更新哪一条路径对应的状态?哪些历史该保留,哪些该丢弃?硬件结构和更新逻辑都会迅速复杂起来。
就算前端已经能从多个地方把指令取回来,问题还没有结束。因为这些指令往往不是天然整齐的。
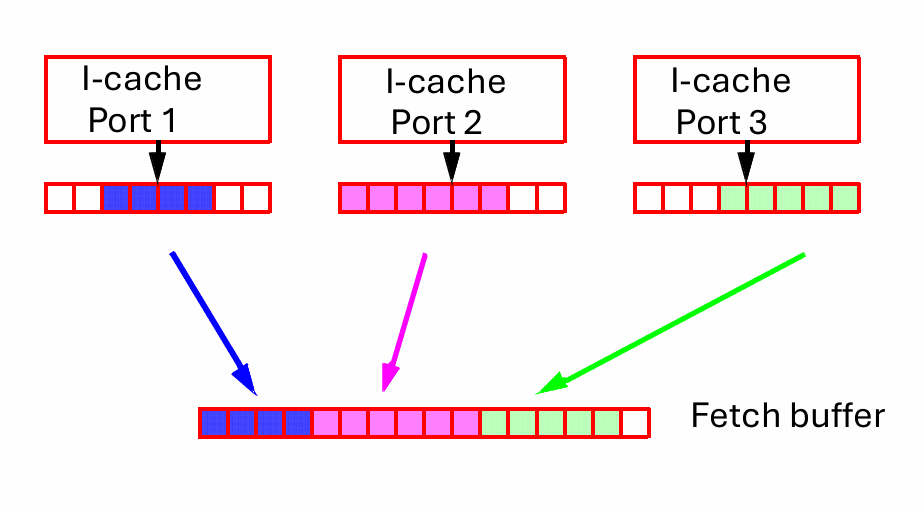
如果同一周期里需要跟随多个被取走的分支继续向前取,前端可能需要多次 I-cache 访问。做成真正多端口 I-cache 可以解决问题,但访问延迟往往会更长;做成多银行结构则更像是一种折中,用更复杂的组织方式去近似多端口能力。
接下来是对齐问题。取指组的边界经常和 cache line 的边界不一致,不同端口、不同银行返回的指令块长度也可能不同,还夹杂着“分支之后其实不该再要”的无效部分。前端不能把这些零散结果原样丢给解码器,而必须先做一次整理:旋转、拼接、去掉无效段,再把有效指令压成连续的一串,送进取指缓冲区或解码队列。
这就是 collapsing buffer 这类结构存在的意义。它会从两个甚至更多 cache block 里同时取回候选指令,把它们旋转到正确位置,再把被取走分支之后的无效部分折叠掉,最后输出一个紧凑、连续、宽度稳定的指令流。对于宽前端来说,这一步不是锦上添花,而是把“能取到”变成“能用上”的关键。
当普通的 I-cache + 分支预测 + 对齐折叠还不够时,前端通常会再引入更激进的结构。
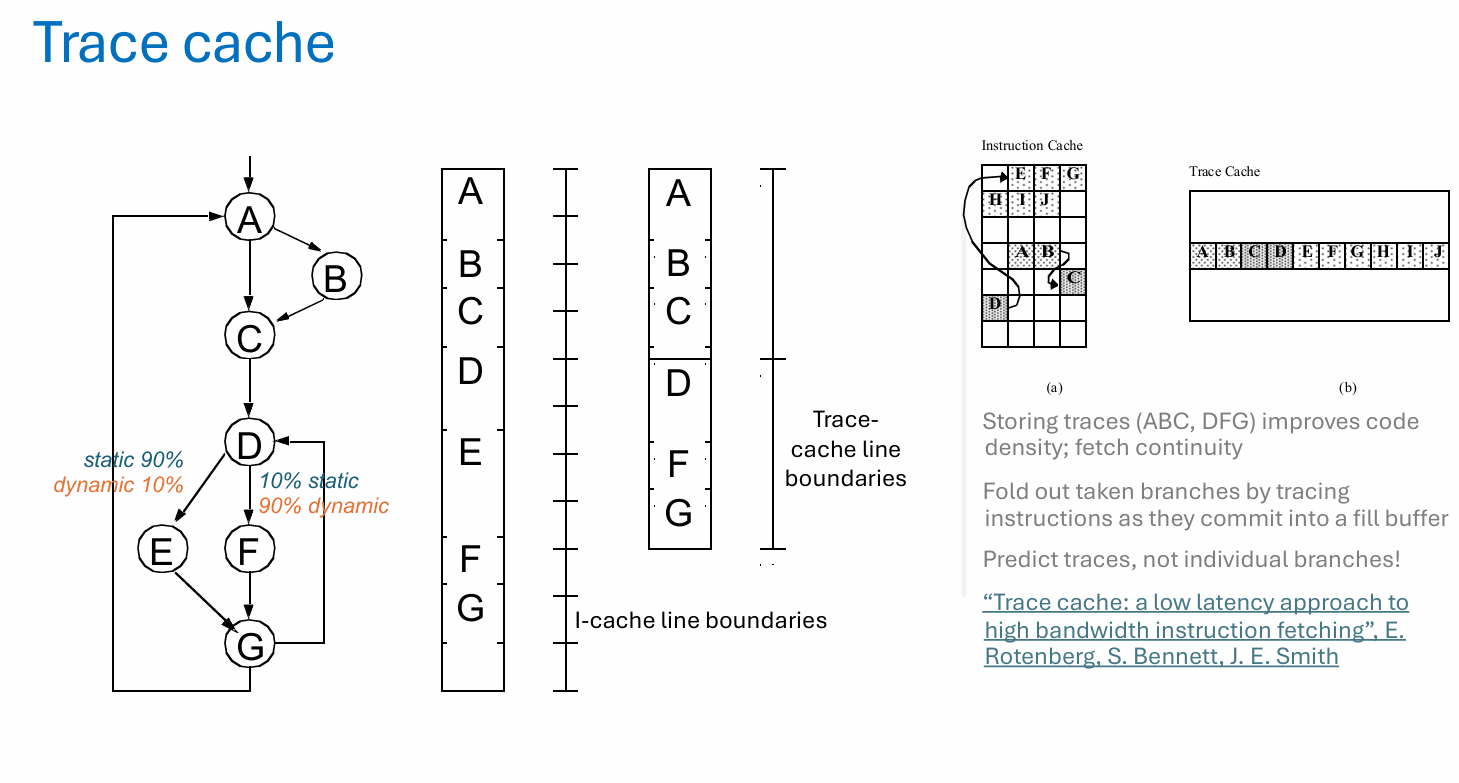
传统 I-cache 存的是程序的静态布局,但程序真正跑起来时,热门执行路径往往会跨越多个基本块、穿过若干被取走的分支,形成一条“动态轨迹”。静态上看,代码可能散在不同 cache line 里;动态上看,它们却常常是连续出现的。
trace cache 的思路,就是把这些高频动态轨迹直接存起来。这样一来,前端下次遇到同样的执行模式时,不需要再一边读普通 I-cache、一边跨行拼接、一边处理被取走分支,而是直接按轨迹把连续指令流取出来。这样既提升了代码密度,也改善了取指连续性。填充 trace cache 时,常见做法是把已经提交的指令沿着真实执行路径收集到填充缓冲区里,等形成一段有价值的轨迹后再写入。到了真正取指时,前端预测的就不再只是单个分支,而是整条轨迹。
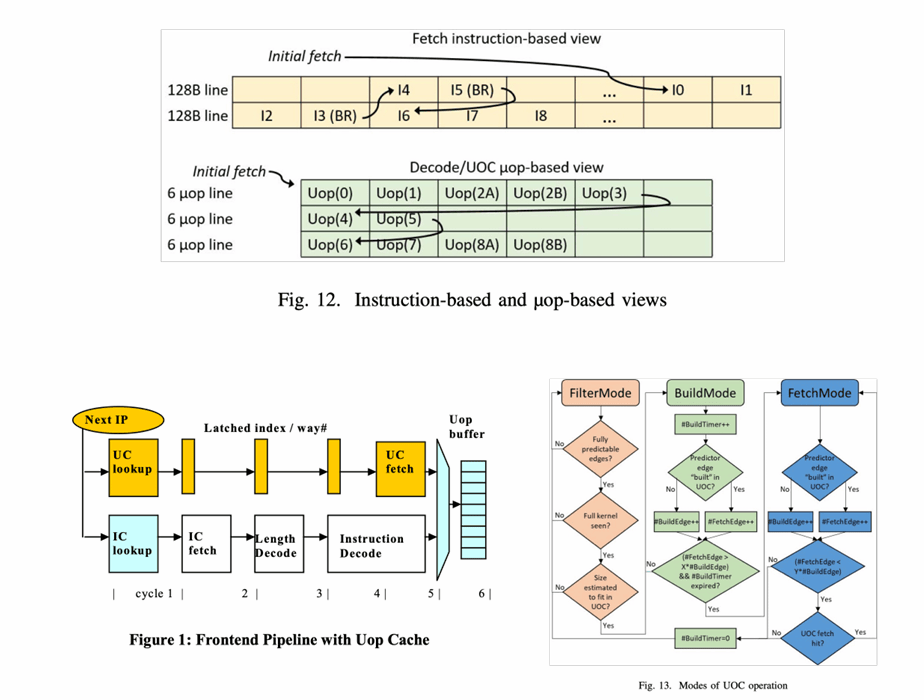
另一条路线,是把“已经解码好的结果”缓存起来。micro-op cache 最早是为了降低 x86 这种可变长指令集的解码时间和功耗而出现的,但后来这个想法也被很多 RISC 设计吸收。它的基本工作方式,是把一个基本块对应的微操作序列缓存起来。前端命中之后,可以直接吐出 uop,而不用每次都回到复杂的指令解码路径。
这种缓存也有自己的限制。每条缓存线能容纳的 uop 数通常有上限,所以有些行会留空;并不是所有基本块的翻译结果都会被缓存进去;前端还需要在“值得不值得翻译并缓存”“正在构建翻译结果”“已经可以直接命中取用”这几种模式之间切换。尽管如此,只要命中率足够好,它对前端延迟和功耗的帮助都非常直接。
还有一种更小巧的办法,是 loop buffer。它不去缓存目标地址,而是直接缓存分支目标处最开始的几条指令。这样,某个分支一旦被取走,下一拍最先要用到的那一小段指令可以绕开 I-cache,直接送到前端。如果循环体非常短,比如不超过 4 条指令,这种结构几乎就相当于一个迷你 loop cache。它通常只能覆盖有限数量的分支目标,但成本低、收益稳,在很多设计里都很讨巧,DSP 中更是很常见。
宽取指从来不是“把前端做宽一点”这么简单。真正困难的地方在于,前端面对的是一条不断拐弯、不断推测、不断回滚的指令流。它既要尽早预测,又要在预测错时极快恢复;既要跨越 cache line 和分支边界持续取指,又要把零散结果整理成稳定、连续、能喂给后端的宽指令流;在必要时,还得干脆绕开普通 I-cache 的静态视角,直接缓存动态轨迹、微操作,甚至只缓存最常见的循环入口。
后端越宽,前端就越像整台处理器真正的节拍器。谁能更快、更连续、更正确地把指令送进去,谁才能把“理论峰值吞吐量”变成真正跑得出来的性能。