高级计算机架构(九):理解 SMT 和 CMP 为什么会一起定义现代处理器
发布于 • 作者: Ethan
参考文章SMT and CMP Architectures。
今天讨论处理器性能,已经不能只盯着主频和单核速度。真正决定上限的,是一颗芯片能否同时把更多指令和更多线程都喂饱。SMT 和 CMP 正是围绕这个问题出现的两条路线:前者想办法让同一个核心在一个时钟周期里更充分地利用已有执行资源,后者则直接把多个完整核心放到同一颗芯片上,把线程分散出去执行。它们解决的是同一个瓶颈,但方法完全不同;理解这两者的差别,也就理解了现代多核处理器为什么会长成今天这个样子。
最早提升处理器性能的主线,是尽量从单个程序里榨出更多指令级并行性,也就是 ILP。典型做法是宽发射超标量处理器:一个周期里尝试发射四条甚至更多指令,并配合乱序执行,让指令按照依赖关系而不是程序原始顺序进入执行单元。这样做的目标很明确,就是让一个线程自己产生足够多的并行工作。
问题在于,一个线程能够提供的并行性并没有想象中那么多。即使处理器已经很“宽”,发射槽位也经常填不满,因为程序本身的指令相关性会限制可并行执行的数量。更麻烦的是,只要遇到一次明显停顿,比如指令缓存未命中,整个处理器都可能跟着空转。也就是说,硬件资源明明在那儿,却没有足够的可执行指令把它们利用起来。
这正是线程级并行性,也就是 TLP,开始变得重要的原因。与其逼一个线程独自撑满整个核心,不如让多个线程一起参与,把空出来的执行机会接住。
处理器开始面向多个线程之后,最直接的变化并不是立刻出现 SMT,而是先出现了两种过渡思路:细粒度多线程和粗粒度多线程。它们都试图减少停顿带来的浪费,但都没有真正把一个周期里的全部资源用到极致。
细粒度多线程会在几乎每一个时钟周期切换线程。它的优点很直接:不管是短延迟还是长延迟停顿,都更容易被别的线程掩盖掉,因为核心总能迅速切到另一个可运行线程上。代价也同样明显:准备充分、原本可以持续推进的线程,会因为频繁轮换而变慢;而且在任意一个时钟周期里,通常仍然只有一个线程发射指令。
粗粒度多线程则更克制。它只在代价很高的停顿上切换线程,例如 L2 级别的长延迟停顿。这样做避免了每周期切换带来的开销,也不会明显拖慢那些本来就能顺畅前进的线程,还能减少完全空闲的时钟周期。但它只能遮住较长的停顿,对较短的气泡和资源空洞帮助有限。
SMT,也就是同时多线程,真正把思路再往前推了一步:它不是在不同周期轮流给线程机会,而是希望在同一个时钟周期里,让多个线程的指令一起占用发射槽位。这样一来,线程级并行性和指令级并行性就不再是二选一,而是同时利用。
SMT 之所以有吸引力,是因为现代处理器内部往往有不少功能单元,而单个线程在很多时刻并不能把这些单元全部用满。只要处理器具备寄存器重命名和动态调度能力,不同线程里彼此独立的指令就可以同时存在、同时执行。原本因为单线程 ILP 不足而空出来的发射槽位、执行单元和调度窗口,就有机会被另一个线程填上。
从吞吐量角度看,这是非常有效的做法。特别是在处理器资源比较充足、可同时驻留多个线程时,SMT 的总体吞吐提升可以相当明显。在拥有八个线程、资源也足够丰富的配置下,整体吞吐量提升大约可以达到 2 到 4 倍。Alpha 21464 和 Intel Pentium 4 都是这一路线的代表性例子。
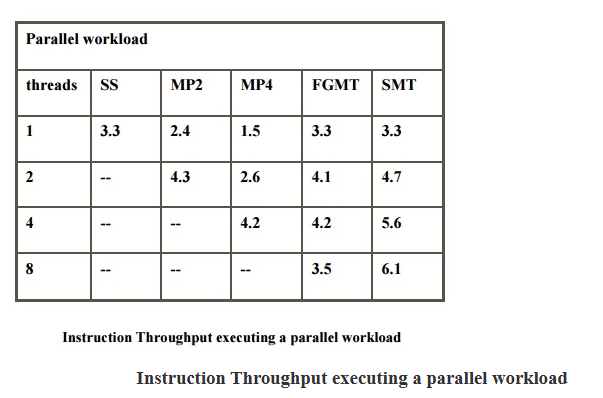
但 SMT 不是“把线程一加就会更快”这么简单。它能否把发射槽位填满,还要看几个现实约束:不同线程对资源的需求是否平衡,不同线程同时争用时资源是否足够,当前活跃线程有多少,缓冲区容量是否有限,前端能否从多个线程里及时取到足够多的指令,以及某些具体指令组合到底能不能在同一周期一起发射。
这也是为什么 SMT 往往伴随着一组新的调度问题。最典型的一点是,单线程性能经常会下降,因为缓存、分支预测器、寄存器等关键资源变成了共享资源。一个线程不再独占核心内部状态,自然可能受到别的线程干扰。这个问题可以通过优先照顾某个线程来缓解,但这样又会影响总吞吐。
前端取指阶段的线程优先级尤其关键。一个常见做法是使用 ICOUNT 这样的启发式策略,让每个线程在处理器资源里尽量保持相对均衡的占比,从而避免某个线程长期占满前端,拖累整体吞吐。也正因如此,评估 SMT 不能只看“平均更快没有”,还要看它对功能单元利用率、取指单元利用率、分支预测准确率、一级缓存命中率和二级缓存命中率分别造成了什么影响。归根结底,SMT 的提升主要来自三个地方:更多发射槽位被有效利用、更多功能单元不再闲置,以及寄存器重命名带来的更强并发容纳能力。
如果说 SMT 的目标是把一个核心内部没用完的资源吃满,那么 CMP,也就是芯片级多处理器或多核,思路就更直接:把两个或更多相互独立的核心集成到同一封装、同一颗芯片,甚至多个裸片封装在一起,让每个核心独立执行线程。
这条路线的特点,是每个处理核心都带着一整套相对完整的体系结构资源。换句话说,很多处理器功能单元会被整体复制出来,不再像 SMT 那样集中在一个核心里共享。多个处理器可以共享片上缓存,也可以各自拥有自己的缓存层次。HP Mako 和 IBM Power4 都属于典型例子。
CMP 的优势在于实现思路更清晰,也更适合那些天然拥有大量线程级并行性的负载,尤其是服务器类任务。服务器程序往往有很多彼此独立的请求或会话,可以直接分配给不同核心,而不必指望从单个线程里继续深挖 ILP。这使得 CMP 在很多实际场景里非常有效。
CMP 之所以后来几乎成为高性能微处理器的主流方向,还有一个更根本的背景:大核心单处理器已经越来越难继续线性提升性能了。一方面,单条指令流里能挖出来的并行性有限;另一方面,单纯继续拉高时钟频率会让功耗和散热迅速变得不可接受。到了这个阶段,“继续把单核做得更激进”不再划算,“把并行放到芯片级”就成了更现实的道路。
进一步往前走,就会出现 CMT,也就是芯片多线程。它可以理解成“芯片多处理 + 硬件多线程”的组合:既可以通过一颗芯片上的多个核心来并行处理软件线程,也可以通过单个核心内部支持多个硬件线程来继续提高资源利用率。处理器通过共享流水线、缓存和预测器等片上资源,可以支撑更多硬件执行流,这种组织方式与高 TLP、低 ILP 的服务器负载尤其匹配。
把两者放在一起比较,差别会非常鲜明。CMP 更容易实现,因为它更像是把多个完整处理单元并排放在同一颗芯片上,结构边界清楚,设计逻辑也更直观。SMT 则更复杂,因为它要求多个线程在同一个核心内部同时争用和共享资源,尤其在集中式指令发射的框架下,线程之间的协调和冲突处理都更难。
但真正能主动隐藏延迟的,恰恰是 SMT。只要一个线程因为缓存未命中或其他长延迟事件停下来,另一个线程就能立刻把空档补上。CMP 虽然能把线程分给不同核心,却不一定能像 SMT 那样细粒度地回收核心内部每一个发射空位。
SMT 的难点也正出在这里。由于指令发射是中心化的,核心内部很难做到彻底功能分区。把线程队列分开可以部分缓解这个问题,但并不能消除中心发射本身带来的约束。因此,从长期看,最有吸引力的往往不是二选一,而是把 SMT 和 CMP 结合起来:芯片层面用多个核心扩展总体吞吐,核心内部再用多线程把局部资源利用率做高。
这也是很多后续研究继续推进的方向。一类思路是让编译器或硬件能够从单个线程中主动生成更多线程;另一类思路是做线程级推测执行,让原本没有显式暴露出来的并行机会也能被硬件尝试利用。再往前走,这种设计会逐渐接近 multiscalar 一类更激进的并行执行模型。
现代处理器的发展并没有在 SMT 和 CMP 之间给出唯一答案,因为它们从来就不是完全替代关系。SMT 擅长减少单核心内部的闲置,CMP 擅长扩大芯片级的并行规模。前者更像是在“把现有资源用满”,后者更像是在“把可用资源做大”。理解这一点,就能看清现代多核架构真正追求的目标:不是单纯增加核心数,也不是单纯增加线程数,而是在功耗、面积、吞吐和单线程体验之间,找到最划算的并行方式。