让 AI Agent 排行更便宜的一种办法
发布于 • 作者: Ethan
论文原文Efficient Benchmarking of AI Agents。
给 AI agent 做评测,正在变成一件越来越贵的事。和传统语言模型基准不同,agent 评测往往不只是“一问一答”,而是要让系统真的去调用工具、执行多步流程、与环境交互,最后再看任务有没有完成。任务一多,成本就会迅速上升。
但这里有一个很关键的问题:我们真的每次都需要把整套 benchmark 全跑完吗?
如果目标是得到一份可靠的排行榜,而不是执着于一个绝对分数,那么答案很可能是否定的。更具体地说,只测试那些“难度适中”的任务,往往就足以保住 agent 之间的相对顺序,而且能显著降低评测成本。
先把目标说清楚。评测通常有两种完全不同的诉求。
第一种是分数预测。也就是希望用一小部分任务,尽量准确还原整套 benchmark 的总分。这个目标要求很高,因为它不仅要求知道“谁比谁强”,还要求知道“强多少”。
第二种是排序预测。也就是只关心 agent 的先后顺序有没有保持住。排行榜、模型选择、脚手架选择,绝大多数实际使用场景关心的其实都是这个问题。
这两者听起来差不多,但稳定性完全不同。
设一个 benchmark 有 $m$ 个任务,第 $i$ 个 agent 在第 $j$ 个任务上的结果记为 $X_{ij}$。如果每个任务只跑一次,$X_{ij}$ 可以看成 0 或 1;如果任务会重复多次,$X_{ij}$ 也可以是成功率。这个 agent 的完整 benchmark 分数就是:
$$ y_i=\frac{1}{m}\sum_{j=1}^{m}X_{ij} $$
如果只挑出一个更小的任务子集 $S$,目标就是看这个子集能不能代替完整 benchmark。
衡量“分数还原得准不准”时,常见指标是 $R^2$:
$$ R^2=1-\frac{\sum_i (y_i-\hat y_i)^2}{\sum_i (y_i-\bar y)^2} $$
这里的 $\hat y_i$ 是用子集任务预测出来的分数,$\bar y$ 是所有 agent 的平均分。$R^2$ 越高,说明子集越能还原完整 benchmark 的绝对分数。
而衡量“排名保得住保不住”时,更适合看排序相关性,比如 Spearman 相关系数 $\rho$ 和 Kendall 的 $\tau$。其中 $\tau$ 很直观:如果 $\tau=0.80$,那就意味着任意随机抽两个 agent 来比较,大约有 90% 的成对比较顺序是对的,因为正确比较的概率可以写成:
$$ \frac{\tau+1}{2} $$
真正重要的发现是:在 agent benchmark 里,排序比绝对分数稳得多。
传统语言模型 benchmark 的压缩已经做过很多了,核心思路大致都是:从海量样本里挑一小部分代表性样本,看看能不能保留整套 benchmark 的信号。
但 agent benchmark 更难,因为它多了一个麻烦来源:scaffold,也就是脚手架层。
同一个底层模型,换一个 agent 框架,表现可能就变了。提示词组织方式、工具调用策略、记忆模块、重试逻辑、执行控制流,这些都会改变结果。这意味着 agent 的表现不只取决于模型本身,还取决于把模型包起来的那一层工程实现。
所以 agent benchmark 的缩减,不能只要求“对子集任务上的模型表现有代表性”,还得要求这个子集能跨脚手架、跨时间保持有效。今天挑出来的一组题,不能只对当前那批 agent 有用;过一段时间来了新的 scaffold、新的模型组合,还得尽量继续有效。
这也是为什么在 agent 场景里,“预测绝对分数”会比“保住排序”脆弱得多。分数需要校准,排序只需要保持大致的单调关系。
直觉上看,最难的题似乎最能拉开差距,最简单的题至少稳定。但实际情况恰好说明,这两种题都不太理想。
如果一个任务太难,几乎所有 agent 都做不出来,那么它就没有区分度。大家全是 0,根本分不出谁更强。
如果一个任务太简单,几乎所有 agent 都能做出来,那么它同样没有区分度。大家全是 1,也没法拉开差距。
真正最有信息量的,是那些难度适中的题。用通过率 $p$ 来表示一个任务被完成的概率,那么在经典的二元响应设定下,任务对能力区分的 Fisher 信息量是:
$$ I(\theta)=p(1-p) $$
这个量在 $p=0.5$ 时最大。也就是说,一道大约“半数 agent 能做出来、半数做不出来”的题,最适合拿来区分不同 agent 的能力高低。
基于这个思路,一个非常简单的规则就出现了:只保留历史通过率在 30% 到 70% 之间的任务。
这就是所谓的“中等难度筛选”。它不需要复杂优化,也不需要专门训练一个任务选择器,只依赖已有历史结果统计出每道题的通过率,然后把落在中间区间的题留下来。
这个规则之所以值得认真对待,不只是因为它直觉上说得通,而是因为它在多种 benchmark 和多种分布变化下都表现得很稳。
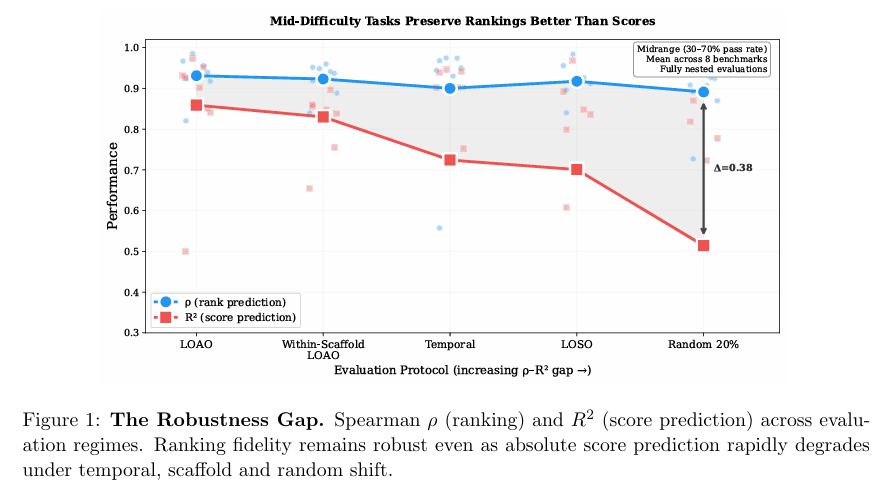
核心现象可以概括成一句话:绝对分数会崩,排名却往往还能保住。
当评测环境发生变化时,比如:
子集任务对完整 benchmark 的分数映射关系会越来越不稳定,所以 $R^2$ 会明显下降。但只要这个映射大体还是单调的,排序相关性就仍然会很高。
这件事非常关键,因为排行榜本来就主要消费“排序”而不是“校准后的绝对能力值”。
从结果上看,排序相关性的表现普遍维持在很高水平。不同协议下,Spearman $\rho$ 大多还在 $0.90$ 左右甚至更高,而 $R^2$ 则会随着分布偏移明显下滑。在更严苛的 scaffold 留一验证中,分数预测显著恶化,但排名仍有很强保真度。
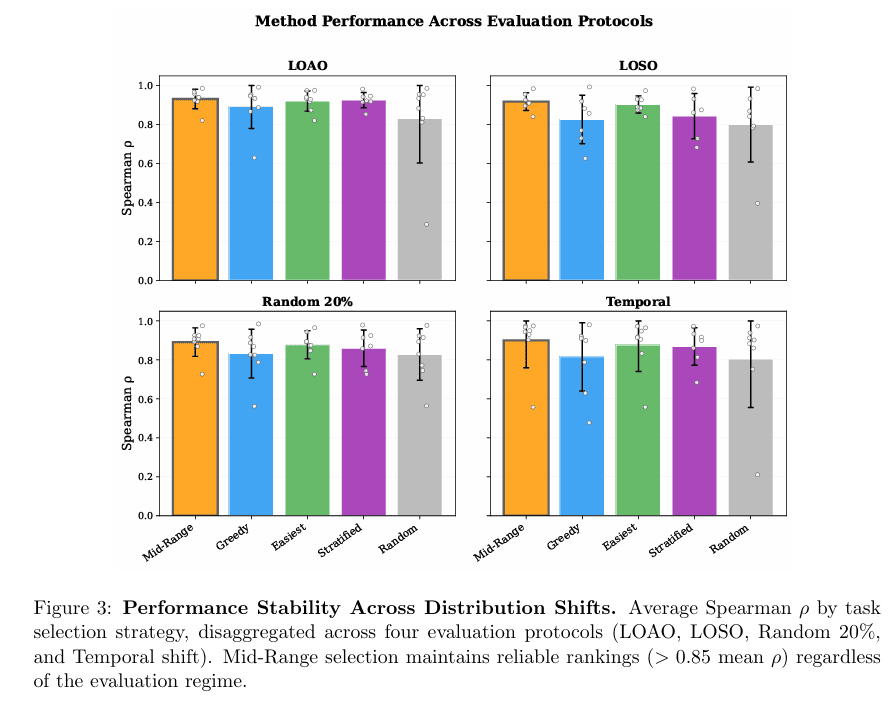
一种自然想法是:既然只需要少量任务,那随机抽一部分不就行了?
问题在于,随机方法平均值看起来可能还可以,但方差太大。也就是说,你这次抽到的子集可能很好,下次换个随机种子就不行了。对于真正要上线维护排行榜的人来说,这种不确定性是不能接受的。
在实验里,随机抽样的平均表现并不差,但最坏情况会明显失真。有些 benchmark 上,它的排名相关性会掉得很低。这说明随机方法不适合当稳定的部署方案,最多只能作为一个参考基线。
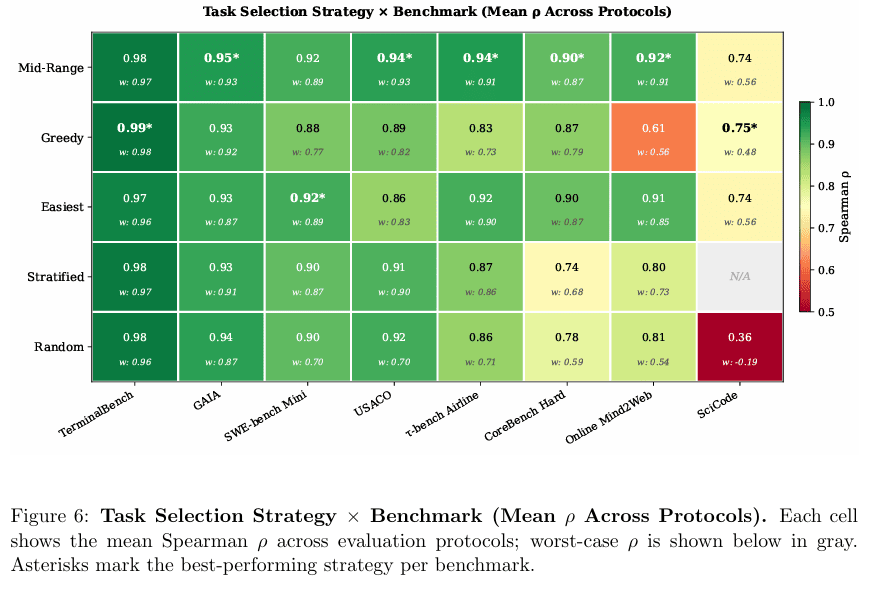
相比之下,中等难度筛选的优势不是“偶尔特别好”,而是“长期都比较稳”。它的平均表现高,最坏情况也更可控。
另一种更“聪明”的方法是贪心选择:每一步都挑一个当前最能提升预测效果的任务,逐步构建一个小任务集。听起来比固定阈值筛选更高级,但在 agent benchmark 上,它反而更容易过拟合。
原因不难理解。贪心方法是在已有 agent 数据上直接优化选择结果,容易把当下数据里的偶然模式也一起学进去。只要测试时的 agent 分布发生变化,比如 scaffold 变了、时间往后推了、模型族谱换了,它就可能失灵。
这类方法在“同分布”条件下有时能拿到很高的峰值表现,但一旦遇到分布偏移,下滑就会比中等难度筛选更明显。换句话说,贪心方法擅长把历史数据榨干,却不一定擅长应对未来变化。
实验里还有一个很有意思的现象:按“最简单的 $k$ 个任务”来选,表现有时也很接近中等难度筛选。
这并不意味着“简单题最好”。更准确地说,在一些 benchmark 的难度分布里,最简单的那批题恰好与“30% 到 70% 通过率”这段区域高度重合。于是“选最简单的题”在这些数据上,看起来像是一个不错的方法。
但一旦这种重合度降低,两者差距就出来了。中等难度筛选之所以更可靠,不是因为它碰巧有效,而是因为它有明确的区分度理论支撑,同时会主动避开两端任务:既不保留大量几乎全错的题,也不保留大量几乎全对的题。
这套方法最吸引人的地方,当然是省钱。
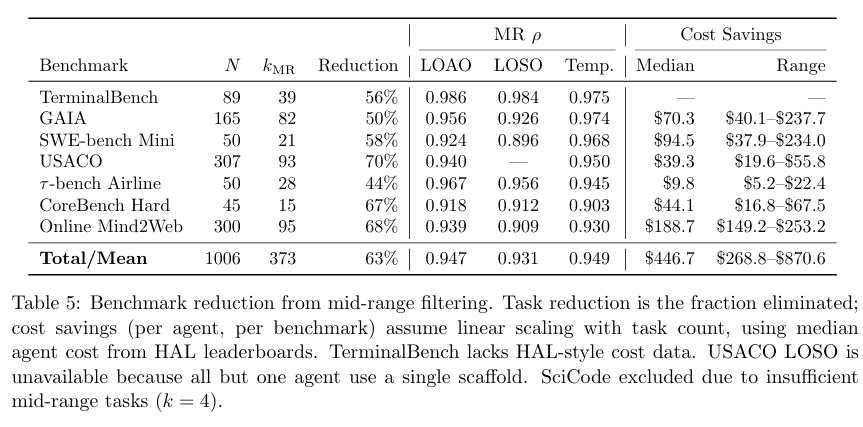
在多个 benchmark 上,中等难度筛选带来的任务削减通常在 44% 到 70% 之间,中位数大约是 58%。换句话说,很多情况下只跑原来一半左右的任务,就能维持相当可靠的排行榜顺序。
一些 benchmark 的单次评测费用并不低。整套任务全跑,单个 agent 的 API 成本可能达到数十到数百美元,复杂场景下还会更高。任务数减少以后,成本通常可以近似按比例下降。
更实际一点看,这种缩减并不是“省一点零花钱”,而是能直接改变评测体系的可持续性:
这类方法最适合几种场景。
第一,benchmark 有持续新增的 agent。前期先花一次成本,把完整结果收集起来,后续就可以把这些历史数据当作“任务筛选训练集”,把前期成本摊薄到未来很多次评测里。
第二,benchmark 能提供逐任务结果,而不是只给一个总分。没有 per-task 数据,就没法知道哪些题是中等难度,也没法验证缩减后是不是还能保住排名。
第三,目标主要是维护排行榜,而不是发布一个特别严肃的“绝对能力值”结论。如果你需要的是“谁更强”,这个方法非常合适;如果你需要的是“这个 agent 的真实能力究竟是多少”,那问题会复杂得多。
一个实用的部署方式可以分成四步。
先用已有 agent 的完整评测结果,估计每道任务的通过率。只要有最初几批 agent,通常就足以形成一个可用的粗估计。样本越多,边界任务的估计越稳。
先选通过率在 30% 到 70% 之间的任务。如果这一段任务太少,比如不到总任务数的 10%,就把范围逐步放宽到 25% 到 75%,再不够的话可以继续放宽到 15% 到 85%。
这一步的关键不是死守一个数字,而是确保你最后留下来的仍然是一批“有区分度”的任务。
新 agent 进来后,只在选中的任务上运行,然后用这部分结果生成排行榜。此时最推荐直接报告排名,而不是把缩减后的原始均分当成完整 benchmark 分数来对外宣称。
如果确实需要给出近似全量分数,更合理的做法是用回归方法去预测完整分数,并明确告诉读者这是估计值而不是完整测量值。
缩减评测不是一劳永逸的。随着模型能力整体上升,原本处于中间难度的任务可能逐渐变得太简单;或者某类新 scaffold 的加入,让任务区分结构发生改变。
因此需要偶尔做一次全量 benchmark,用来检查当前子集是否仍然可靠。一旦发现排序相关性明显下降,或者出现能力跃迁,就需要重新选题,甚至判断这个 benchmark 是否已经接近饱和。
这套办法并不是万能的。
最典型的不适用情况,是 benchmark 的难度分布过于偏斜。比如某些 benchmark 里,真正落在中间难度带的任务少得可怜,这时中等难度筛选就没有足够的“可选空间”,稳定性会变差。
另一个限制是冷启动成本。如果你只打算评测极少数 agent,那前期全量跑出来的那批数据未必能摊回本。只有当 leaderboard 会持续接收新 agent 时,前面的完整评测投入才有意义。
还有一点也很重要:很多 agent benchmark 本身就不一定能准确测到“绝对能力”。任务设计偏差、评分器误判、脚手架耦合,都会让分数带有系统性偏差。既然绝对分数本来就不完美,那么把重点放在相对排序上,反而更符合这些 benchmark 的实际用途。
如果希望社区以后能更系统地做这类“低成本但高保真”的评测,benchmark 运营者最好默认公开逐任务结果,而且格式要足够好用。
最理想的形式,是直接提供一张平铺表,每行对应一个 agent–task 组合,至少包含:
这件事几乎没有额外计算成本,但价值很大。只有当历史 rollout 数据能被社区直接拿来分析,大家才可能发现冗余任务、诊断 benchmark 饱和、构建缩减评测流程,并持续降低评测门槛。
给 AI agent 做评测,不一定非要每次都把整套 benchmark 全跑完。只要目标是得到可靠的排行榜,而不是过度解读绝对分数,那么“只测中等难度任务”就是一种非常实用的办法。
它之所以有价值,不在于方法有多复杂,恰恰相反,在于它足够简单:先看历史通过率,再保留通过率大约在 30% 到 70% 的任务。这样做通常能砍掉一半以上的评测任务,却仍然保住相当高的排序保真度。
对 agent 评测来说,这其实是一个很重要的观念转变。与其把 benchmark 当成一个必须穷尽执行的能力标尺,不如承认它更常见的用途本来就是“比较谁更强”。一旦目标从“精确量尺”转向“稳定排序”,选择性测量就不再是偷工减料,而是更合理、更节制,也更适合真实世界的一种评测方式。