自动代码评审离真正理解人类反馈还有多远
发布于 • 作者: Ethan
论文原文Code Review Agent Benchmark
AI 写代码越来越快,代码评审反而更容易成为新的瓶颈。
今天的问题已经不是“模型能不能写出一段能跑的代码”,而是“大量自动生成的代码进入仓库以后,谁来判断它到底有没有问题”。自动代码评审工具正在快速出现,但另一个更基础的问题也随之冒出来了:我们到底该怎样判断一个评审工具是不是足够好?
一个更靠谱的答案,不是去比较评论像不像人写的,而是去看这条评论能不能真的把代码往正确方向推。围绕这个思路,c-CRAB 这套基准把“人类评审意见”转成“可执行测试”,用测试是否通过来判断自动评审是否真正抓住了问题。这个改动看起来简单,意义却很大:它把代码评审的评价标准,从“像不像”变成了“有没有用”。
过去不少自动代码评审基准,主要依赖几类方法来评分。
第一类是文本相似度。比如 BLEU、ROUGE、chrF,或者 embedding 相似度。它们做的事情本质上都差不多:把自动生成的评论和人工评论放在一起,看文字是否接近。
问题在于,代码评审的价值并不在于措辞接近,而在于有没有指出同一个真实问题。
举一个很典型的例子。某个补丁里新增了对键盘输入维度的检查,但实现方式会在输入结构不合法时提前访问嵌套元素,导致像 check_keyboard_type([1]) 这样的输入直接抛异常。人工评审指出的是“在确认内部元素是不是序列之前,就先做了两层索引,这会让异常输入炸掉”。自动评审工具给出的评论虽然措辞完全不同,但核心担忧其实是同一个:这里的索引顺序不安全,会把本来应该被优雅拒绝的输入变成运行时错误。
如果只用文本相似度来打分,这种评论通常得分并不高,因为两边说法不一样,n-gram 重叠非常少,embedding 距离也未必足够近。可从工程角度看,这条自动评论明明已经抓住了真正的问题。
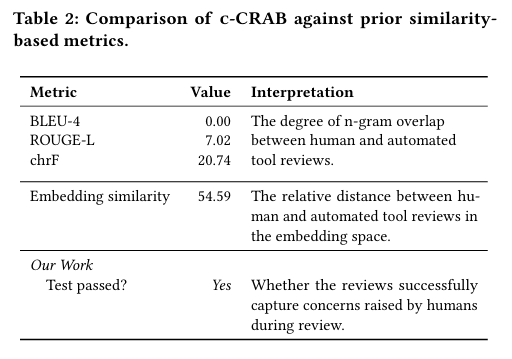
这正是传统指标最尴尬的地方:它们能衡量“表述有多像”,却很难衡量“问题有没有对上”。
第二类方法是定位指标。它会看自动评论是否落在和人工评论相同的代码位置上。这比纯文本相似度前进了一步,但依然不够。因为“指出了同一行”不等于“指出了同一个问题”,更不等于“给出了能推动修复的反馈”。
第三类方法是让大模型当裁判,也就是常说的 LLM-as-a-judge。它比简单相似度更聪明,能读上下文,也能判断评论是不是在说同一件事。但这条路也有两个明显问题:一是判断会受提示词影响,二是输出本身带随机性,复现实验时并不稳定。
更关键的是,它不一定能分辨“说到了问题”和“真的对准了解法”之间的差别。
再看另一个例子。某个 Django 模型里新增了一个 ArrayField(models.CharField(max_length=200))。人工评审的意思很直接:这里不该继续用 CharField,应该改成 TextField,因为数组里的字符串可能很长,固定长度会从设计上留下隐患。
自动评审工具也看到了风险,但它给出的建议只是“把最大长度放宽一些,例如从 200 提高到 400,或者至少说明限制”。这条评论并不荒唐,甚至能看出它确实理解了“长度限制会出问题”。但它和人工评审的真实意图并没有完全对齐,因为前者是在做缓解,后者是在做根治。
这就是很多“看起来说得没错”的自动评论真正的短板:它们未必足够可执行,也未必能把修复引到正确方向。
c-CRAB 的思路正好卡住了这个关键点。它不再直接比较评论文本,而是把人工评审背后的意图转成测试。然后把自动评审生成的评论交给一个编码代理,让它据此修改补丁。修改后的代码再去跑测试。测试通过,说明这条评审意见不仅“说中了”,而且真的足以引导修复;测试没通过,说明它可能只是看起来合理,却没有真正贴合问题。
在前面的键盘输入例子里,这个意图可以被写成一个非常明确的测试:当输入是 [1] 时,函数不应该抛异常,而应该安全地返回 False。这样的测试比任何相似度指标都更接近代码评审的本质,因为它直接把“评审到底想防住什么”变成了可执行规格。

这套基准的核心目标很明确:评估自动代码评审工具,是否能发现那些人类评审通常会指出、而且可以通过代码修复验证的问题。
它的工作方式可以概括成一句话:给工具一个真实 PR,让它生成评审意见;再把这些意见交给编码代理,让代理修改代码;最后用从人工评审中提炼出来的测试去验收结果。
如果修改后的代码能通过这些测试,就说明自动评审提出的问题,与人类评审关注的问题在行为上对齐了。
这个评价方法可以写成一个很直观的实例级分数。对第 (i) 个基准实例,设它对应的验证测试集合为 (T_i),编码代理根据自动评审修改后得到的补丁为 (\hat{P}_i)。那么该实例的得分就是:
$$ s_i=\frac{|{t\in T_i \mid t(\hat{P}_i)=\mathrm{PASS}}|}{|T_i|} $$
这里的含义并不复杂。分子是在说:有多少个测试在修改后通过了;分母是在说:这个实例总共有多少个测试。于是 (s_i) 就表示,自动评审到底帮助解决了多少个人类曾经指出的问题。把所有实例汇总起来,就得到一个工具在整套基准上的总通过率。
和“评论像不像人写的”相比,这个指标更接近工程现实,因为代码评审最终要落到两个字上:修复。
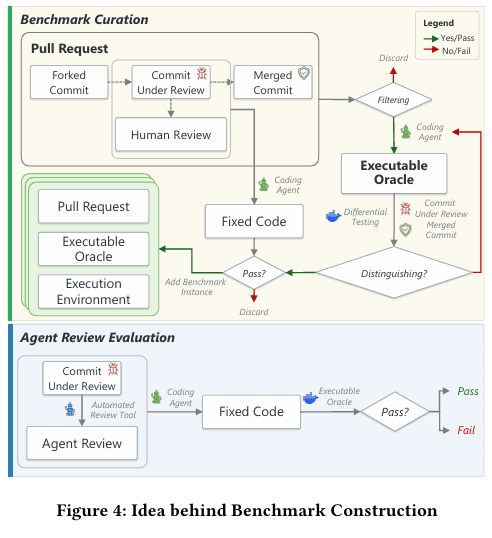
把“人类评论”变成“可执行测试”并不轻松。真正难的地方不在于写一个测试,而在于保证这个测试稳定、可复现,而且确实对应一个真实、可修复的问题。为此,整个构建流程被拆成了四步。
真实 PR 讨论里有很多评论并不适合进入基准。有人会提问,有人会表示赞同,有人只是讨论实现风格,还有些评论本身并不能对应一个可以执行验证的缺陷。
因此,只有同时满足三个条件的评论才会被保留:它指出了具体问题,它能引导实际修改,而且这个问题原则上可以通过测试验证。
为了自动化完成这一步,流程里先人工抽样标注了 100 条评论,区分哪些属于高质量、哪些属于低质量。随后再用这些标注去反复调优一个 LLM 过滤器。这个过滤器最终追求的不是尽量多保留,而是尽量少放进噪声,因为一旦把无从验证的评论混进来,后面的测试就会失真。最终这个过滤步骤在标注集上做到了 86% 的精确率。
测试不是凭空跑的,它必须回到当时那个 PR 所在的仓库、依赖和运行环境里。
所以每个实例都会被构造成一个隔离环境,默认用 Docker 来承载。流程会自动生成脚本,拉取仓库、检出待评审提交、识别构建工具、推断依赖,并尽可能完成可编辑安装。
这一步的难点主要出现在历史 PR 上。很多老项目当年写依赖比较松,只写了下界,甚至根本没钉版本。今天再去安装时,包管理器很可能会拉到一个已经发生破坏性变化的新版本,导致环境直接搭不起来。解决办法不是人工逐个修,而是再让一个编码代理去审计依赖,综合文档、提交时间、测试配置和 API 用法,把更准确的版本范围补出来。
这一步才是 c-CRAB 最有辨识度的地方。
每条评论都会先和对应的 diff hunk 对齐,再拿到修改前后的完整文件内容,以及相关代码上下文。接着让大模型根据评论含义生成候选测试。这个测试必须满足一个硬条件:在问题还没修之前失败,在问题修掉之后通过。
如果第一次生成的测试不能满足这个“先失败、后通过”的要求,系统会把报错和执行轨迹反馈回去,让模型继续改。这个循环最多尝试三次,直到生成一个可靠的测试,或者直接放弃该实例。
这一层验证是为了避免一个很现实的混淆因素:如果将来评测时测试没通过,到底是评审意见不行,还是负责改代码的编码代理不行?
为了解决这个问题,每个实例在真正入库之前,都要先做一次“人类评论驱动的修复验证”。也就是说,把原始人工评审意见交给同一个编码代理,看它能不能在固定尝试次数内根据评论修好代码并通过测试。只有能通过这道验证的实例,才会进入最终基准。
这样做的意义很大:后续自动工具表现不好时,至少可以更有把握地说,是它给出的评审反馈没有抓住人类关心的问题,而不是评测流程本身有偏差。
经过完整筛选后,最终留下了 184 个 PR 实例、234 条经过验证的评审评论,覆盖 67 个仓库。平均每个实例涉及 418.1 行修改,中位数是 123 行,说明这不是只看几行 diff 的玩具任务,而是需要处理相当真实的 PR 上下文。
这些测试又分成两大类。
一类是行为测试,一共有 62 个,占 (26.5%)。这类测试会真正导入并执行代码,用具体输入检查输出或异常行为是否符合预期。
另一类是结构测试,一共有 172 个,占 (73.5%)。这类测试不一定直接运行目标逻辑,而是检查源码文本、模式或 API 表面是否发生了期望中的改动。平均每条测试有 31.8 行,中位数 28.5 行,说明测试本身也不是一句断言就结束,而是足以承载比较具体的评审意图。
这套基准评测了四个代表性工具:Claude Code、Codex、Devin Review 和开源的 PR-Agent。为了保持公平,真正负责“按评论修代码”的编码代理始终是同一个,也就是使用 Sonnet-4.6 后端的 Claude Code。
最终结果非常清楚。
Claude Code 的总通过率最高,为 (32.1%)。Devin Review 是 (24.8%),PR-Agent 是 (23.1%),Codex 是 (20.1%)。作为对照,人类评审对应的通过率是 (100%)。
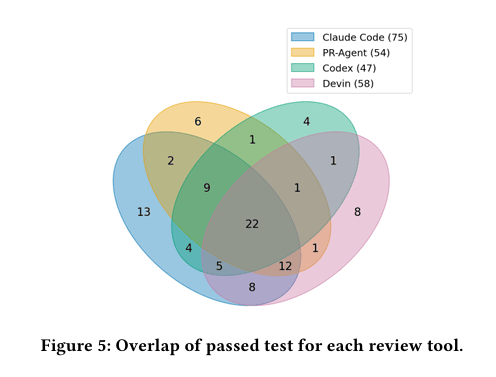
如果把四个自动工具的结果取并集,也只有 234 个测试里的 97 个被至少一个工具覆盖到,总体覆盖率是 (41.5%)。换句话说,即便把今天这几类主流自动评审工具全叠在一起,仍然有一大半人类会指出的问题没有被抓住。
还有一个很值得注意的现象:自动工具通常比人类评审更“高产”。例如 Claude Code 和 Devin 平均每个 PR 都会给出 7.3 条评论,而人类平均只有 1.3 条。但评论数量更多,并不等于更有效。自动工具给得越多,维护者要读的内容越多,误报成本也越高;如果这些评论没有真正推动修复,数量反而会变成负担。
这也是为什么“通过率”比“评论数”更接近真实价值。代码评审不是刷存在感,关键是能不能让代码变好。
只看总通过率,还不足以解释差距到底来自哪里。更细一点看,会发现自动工具和人类评审在“关注什么问题”上,本来就存在明显偏移。
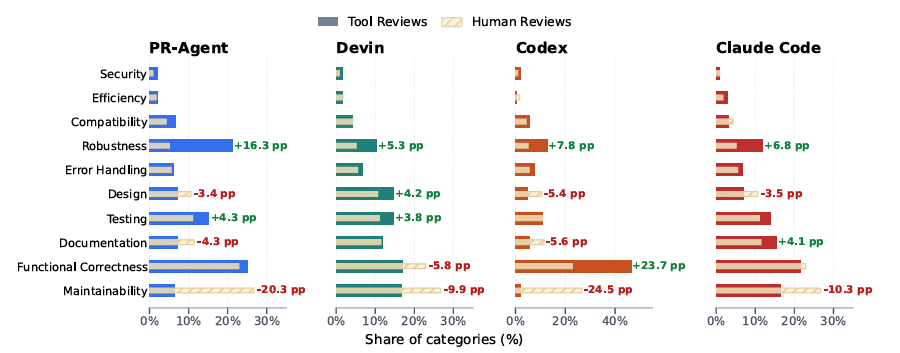
为了看清这一点,所有评审意见被手工归入十个类别:功能正确性、测试、鲁棒性、兼容性、文档、设计、错误处理、可维护性、效率和安全。标注过程由两位标注者独立完成,再对分歧进行消解。
结果显示,自动工具在安全、效率、兼容性、错误处理这些类别上的分布,和人类没有差得特别离谱;但在设计、文档和可维护性上,明显提得更少。相反,它们在鲁棒性和测试相关问题上往往提得更多。
这说明两件事。
第一,自动工具确实擅长抓某些“模型更容易看见”的问题,尤其是边界情况、潜在异常和测试覆盖不足。它们对这类问题往往比较敏感。
第二,人类评审有大量判断依赖仓库上下文,而这正是今天很多自动工具最薄弱的部分。比如某个项目长期沿用某种 API 包装方式、某个模块约定了特定的命名策略、某个目录下的文档格式有隐含规范,这些都不一定写在 diff 里,但人类维护者会自然把它们当成“应该指出的问题”。
从这个角度看,自动评审和人类评审更像是两套不同的感知系统,而不是简单的替代关系。
再进一步看每个类别上的通过率,差异会更明显。
整体上,自动工具在鲁棒性和功能正确性上表现相对更好。Claude Code 在鲁棒性类别上的通过率甚至达到 (75.0%),在功能正确性上也有 (41.5%)。这类问题通常更局部,往往能直接从补丁和附近代码中看出端倪,因此更容易被模型捕捉。
但在文档、设计和可维护性上,表现普遍偏弱。以可维护性为例,各工具通过率大致落在 (7.9%) 到 (27.0%) 之间。文档和设计的情况也不理想。这类问题往往依赖更宽的仓库背景、长期演化的约定,以及“这个项目一贯怎么做”的隐性知识。当前工具既拿不到足够背景,也不太会主动利用这些背景,所以很容易错过。
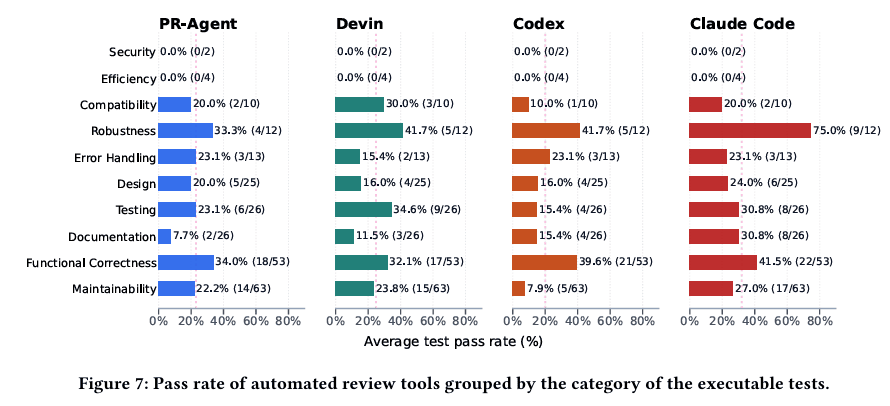
这也是为什么“看起来很聪明”的自动评审,一到真实团队里就常常让人感觉“不太懂我们项目”。它未必不会看代码,但它还不够懂语境。
最直接的一条结论是,自动代码评审暂时更适合做补充,而不是替代。
它可以在鲁棒性、测试和部分功能正确性问题上提供额外视角,帮团队多扫一遍潜在边角;但在设计、文档、可维护性这类更依赖项目历史和团队规范的问题上,人类评审仍然明显更强。如果把自动工具当成“第一道补充筛网”,而不是“完整接管评审”,它的价值会更容易释放出来。
第二条启发是,仓库级上下文很可能是下一阶段的关键增量。
很多人类评审意见,并不是因为发现了某个普适性 bug,而是因为知道“这个仓库不这样写”。这意味着,想让自动评审真正变强,不能只喂它 PR diff,还要给它更丰富的项目背景,比如架构说明、风格指南、历史评审记录、命名约定,甚至专门面向代理的说明文件。像 AGENTS.md 这样的仓库内文档,很可能会成为未来自动评审的重要上下文入口。
第三条启发是,测试不只是评测工具,也可能成为训练信号。
当一条评审意见能被转换成“先失败、后通过”的测试时,它就获得了一个非常清晰的优化目标。未来的自动评审系统,完全可以不只在文本上模仿人工评论,而是直接学习怎样提出那些能推动代码通过测试、完成真实改进的反馈。这比单纯优化措辞相似度,更接近代码评审的真正目标。
这套方法已经比传统相似度评测强很多,但也不是没有边界。
首先,整个流程依赖一个编码代理去根据评论修改代码,因此结果多少仍会受到代理能力影响。为减少这个问题,基准在入库前已经用相同代理做过验证,确保留下来的任务至少是“这个代理在看懂人类评论时能修掉的”。这让评测更公平,但并不意味着代理因素被完全消除了。
其次,最终规模虽然已经足够有代表性,但仍然只是更大软件生态中的一个精细子集。184 个 PR、234 条验证过的评论,强调的是“可靠”和“可复现”,不可能完全覆盖现实世界所有评审模式。
最后,前面的评论筛选依赖 LLM 分类器,后续类别分析也涉及人工判断。流程已经通过高精确率过滤、独立标注和双人消歧来降低偏差,但这类偏差依然不可能被彻底抹平。
自动代码评审真正缺的,可能从来不是更花哨的评论文风,而是更可靠的“问题对齐能力”。
c-CRAB 的价值就在这里。它把评估标准从文字层面挪到了行为层面,不再问“这条评论像不像人工评论”,而是追问“它能不能把代码引到正确修复上”。在这个标准下,今天的自动评审工具离人类还有明显距离:单个工具大多只能覆盖大约五分之一到三分之一的人类关切,即便合并起来也只碰到 (41.5%) 的测试。
但这并不意味着自动评审没价值。更准确的理解是,它已经形成了自己的优势区间,只是还远没有抵达人类维护者所在的语境层级。接下来真正值得做的,不只是继续提升模型的局部缺陷识别能力,更是让它更懂仓库、更懂团队规范,也更懂一条评审意见最终应该如何落成一个可验证的修复。
当自动评审开始围绕“可修复、可验证、可落地”来设计时,它才会真正从一个会说话的评论生成器,变成一个有工程价值的评审伙伴。