把 AI Agent 当成系统来构建,才能真正上线
发布于 • 作者: Ethan
总结与AI Agents in 2026: Practical Architecture for Tools, Memory, Evals, and Guardrails。
很多 AI Agent 之所以在演示里看起来很神奇,不是因为它们已经解决了难题,而是因为最难的部分被藏起来了:状态怎么管理,工具怎么约束,失败怎么重试,效果怎么评估,危险操作怎么拦住。真正到了生产环境,Agent 不是一个提示词技巧,而是一个以大模型为计划器和执行器的系统工程。
要让 Agent 在真实业务里稳定工作,重点已经不是“它会不会回答”,而是“它会不会选对动作、在正确边界内行动、出了问题能不能定位、升级之后会不会退化”。一套能落地的生产级 Agent 架构,核心通常只有六件事:严格的工具契约、可重放的状态机、分层记忆、迭代式规划、可回放的评测,以及在模型之外生效的安全护栏。
先把定义讲清楚,很多后面的架构选择才不会走偏。生产环境中的 Agent,本质上是一个循环:
这件事看起来很简单,但真正决定系统质量的,不是“让模型想下一步”这件事本身,而是这个循环里哪些部分交给模型,哪些部分必须收回到确定性的系统里。

模型适合做概率性的判断,比如理解意图、选择策略、决定下一步动作。系统适合做确定性的事情,比如验证工具参数、执行权限控制、写入状态、记录轨迹、判断是否结束。只要把这两类职责混在一起,Agent 很快就会变成一个无法调试的黑箱。
所以,一个可上线的 Agent,首先不是“提示词写得好”,而是控制回路边界清楚:模型负责决策,系统负责约束和落地。
大多数 Agent 失败,并不是模型完全不会做事,而是在工具调用上持续犯低级错误:该查数据库时去做搜索,参数少字段,字段类型不对,还没确认约束就先调用,失败后重试又把副作用执行了一遍,结果重复发邮件、重复扣费、重复改数据。
这类问题不能靠“再优化一下提示词”解决。工具调用必须被当成 API 契约来设计,而不是给模型的宽松建议。
一个实用的工具层,至少要满足四个条件。
第一,输入和输出必须有类型约束。可以用 JSON Schema、Zod、OpenAPI,形式不重要,关键是工具必须能验证参数是否合法,并在失败时返回机器可读的错误,而不是模糊的一段文本。
第二,有副作用的工具默认要支持幂等。只要会发消息、改记录、扣款、创建工单,就应该要求显式的 idempotencyKey。这样即使模型或系统发生重试,也不会把同一件事做两遍。
第三,工具输出必须是结构化结果,而不是“看起来像人类能读懂”的漂亮文字。一个稳妥的返回结构通常应包含成功标记、业务数据、错误信息和元数据。这样后续的状态更新、评测和调试都能直接消费。
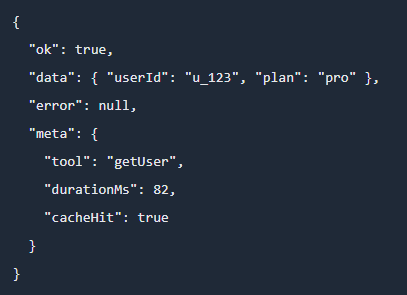
第四,每次工具调用都要有预算。至少要限制超时、最大重试次数,以及外部付费 API 的成本上限。Agent 不是单轮问答,而是多步流程;一旦没有预算控制,延迟、花费和失败级联都会变得不可控。
工具层一旦设计好,模型的“工具使用能力”才有稳定边界。否则,模型再强,也只是站在一组松散接口前面试错。
许多团队一开始会把一切都塞进聊天历史:用户说了什么、模型想了什么、工具返回了什么、下一步该做什么。这样做原型最快,但也是最容易在上线后失控的方式。
因为聊天记录天然有四个问题:它会无限增长,语义经常含糊,推理成本越来越高,而且几乎不可查询。你很难可靠地问系统:“它为什么走到这一步?”“哪一次工具调用导致后面全错了?”“同样输入为什么这次和上次行为不同?”
解决办法是显式状态机,哪怕它很小。最实用的做法,是实现一个 reducer,让每一步状态变化都由确定性的事件驱动。模型负责产出动作,系统再把动作执行结果转换成标准事件,由 reducer 更新状态。
这样做的好处非常直接。每一步边界都清楚,执行过程可以重放,调试变成可复现的问题,评测也能直接针对轨迹而不是只看最终回答。
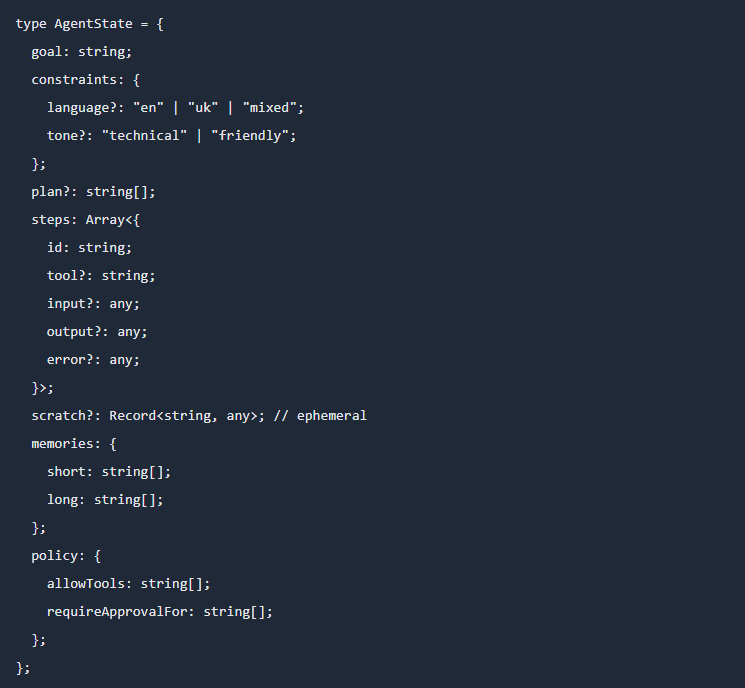
一个够用的状态结构,通常至少包括这些部分:任务目标、约束条件、当前计划、已执行步骤、临时草稿区、短期和长期记忆、以及当前生效的策略配置。这里最重要的不是字段名,而是原则:状态是系统事实,不是让模型从长上下文里自己“猜出来”。
一旦把状态抽出来,Agent 才从“会聊天的程序”变成“可控的工作流引擎”。
很多团队一说 Agent 记忆,马上想到向量数据库。它当然有用,但只把“记忆”理解成向量检索,通常会把系统做歪。
更实用的做法,是至少把记忆拆成四层。
第一层是工作记忆,也就是当前任务正在处理的临时上下文。比如已抽取的约束、尚未完成的计划、最近的工具中间结果。这些东西应该放在状态里,而不是不断拼接进 prompt。它们是短命、易变、和当前回合强绑定的。
第二层是会话记忆,也就是对长对话的压缩总结。没有必要无限保留完整聊天历史,更稳妥的方式是保留最近若干轮,再加一份滚动摘要。摘要本来就应该是有损的,但必须保持一致性,否则不同轮次会出现“总结漂移”。
第三层是任务记忆,也就是任务过程中产出的工件。比如生成的文件、做出的决策、创建出的 PR 链接、执行过的命令、关键日志。这一层最适合结构化存储,不适合扔进 embedding 里碰碰运气,因为它们往往是精确事实。
第四层是长期用户或组织记忆,也就是相对稳定的偏好和事实,例如技术栈偏好、输出风格偏好、组织规范等。这一层最需要治理:什么允许存,存给谁看,多久过期,是否需要显式同意,都要事先定义。
向量检索真正适合的,是文档上下文召回、代码库语义检索,或者长周期对话中“上个月提过的那件事”。它不适合承载关键事实、权限配置和交易相关信息。涉及权限、政策、资金和不可逆操作时,应使用数据库、配置系统或专门的业务系统,而不是相似度搜索。
Agent 很容易被设计成一种过于理想化的流程:先让模型生成一份完整计划,再严格照着执行。看起来很整齐,实际却经常不适合真实环境。
因为很多任务在开始时信息并不完整,真正可行的下一步,往往要等工具返回结果后才能确定。更现实的方式,是先生成一个浅层计划,做第一步,再基于反馈重规划。也就是说,规划不是一次性产物,而是执行循环的一部分。
一个好用的规划机制,重点不在“多聪明”,而在“多明确”。它应该强制模型说清楚假设、所需输入、工具限制和成功标准。越是多步骤任务,越应该把计划保存成结构化数据,而不是自然语言散文。

当计划以数据结构存在时,你就能检查很多本来无法回答的问题:它是否遵循了原计划,在哪一步发生偏离,偏离是否合理,哪些步骤是多余的,哪些步骤根本没有执行。这会直接影响后续评测和回归分析的质量。
换句话说,规划的目标不是把未来一次性预测对,而是让后续执行和修正有据可查。
如果一个 Agent 最终给出了对的答案,但中间走了十几步弯路,调用了不该调用的工具,花了过高的时间和成本,甚至差点触发风险操作,这仍然不是一个合格的生产系统。
所以 Agent 的评测不能只看最后一句回复,而必须覆盖整个轨迹。
最基本的评测维度有四类。第一类是任务结果,比如成功、失败、部分完成。第二类是工具正确性,比如是否选对了工具,参数是否合法,有没有不必要的调用。第三类是轨迹质量,比如总步数、总耗时、总成本、重试次数。第四类是安全与策略合规,比如是否调用了禁用工具,是否发生数据泄露,是否被提示注入诱导偏航。
要把这些评测真正用起来,关键是建立一个可重放的测试 harness。最理想的方式,是为一组真实任务样例提供固定输入和工具 mock,让 Agent 在 CI 里跑完整轨迹。这样测试既便宜又稳定,不会因为外部系统变化而失真。
模型充当裁判也可以用,但不能盲信。更稳妥的做法是给清晰 rubric,要求输出结构化结果,再对样本进行人工抽查。只有在 judge 评分足够稳定后,才能把它当作有参考价值的自动指标。否则,它更像是一种可能波动的测试信号,而不是最终裁决。
评测体系一旦建立,Agent 才能像普通软件一样被迭代,而不是每次升级都靠手感判断“好像更聪明了”。
Agent 一定会失败。设计目标不应该是“绝不失败”,而应该是失败时足够安全、可观察、可恢复。
这就要求系统从一开始就限制爆炸半径。
最先要做的是能力分级。不同环境允许使用的工具应该不同,开发、测试、生产不能一套权限全开。其次,不可逆操作必须设置人工审批,比如发送消息、删除数据、扣款、变更关键资源。模型可以建议,但不应自动越过最后一道门。
然后是密钥与数据边界。不要把原始密钥直接放进模型上下文,工具最好使用短期令牌,工具返回结果也要做脱敏处理。很多“安全事故”并不是模型主动作恶,而是系统把不该给它看的东西提前给了。
提示注入则要按“不可信输入”来处理。网页、文档、检索结果,本质上都只是数据,不应被当成指令来源。提示模板里必须明确区分“数据”和“系统指令”,并且永远不要让模型直接执行来自外部文档的操作建议。
此外,还要给 token、工具调用和总成本设预算,对高风险工具进行沙箱化,把所有命令完整记录下来。这些措施看起来不像“智能”,却往往决定系统能不能上线。
这里最容易被低估的一点,是把策略写成代码。比如把环境允许调用的工具、哪些操作必须审批,写成机器可读的配置,并在模型外强制执行。只有这样,策略才不是“提示词里的一句提醒”,而是系统层面的硬约束。

很多团队会上日志,但日志常常只能告诉你“报错了”。而 Agent 真正需要的是 trace,也就是一条完整、按步骤串起来的执行轨迹。
一条合格的 trace,至少应该回答这些问题:调用了哪些工具,顺序是什么,输入输出是什么,延迟和成本花在哪里,Agent 为什么卡住,哪一步开始偏离预期。
因此,每一步至少要记录 traceId、stepId、工具名、参数哈希、执行时长、结果摘要、模型信息和 token 使用量。这里故意强调参数哈希而不是原始敏感数据,是因为可调试和隐私保护需要同时成立。
观测能力不只是线上排障工具,它也直接决定你能否做离线评测。没有轨迹,就没有回放;没有回放,就几乎无法判断一次架构调整到底改善了什么,还是只是换了一种失败方式。
落地时,Agent 通常会有几种常见架构。
一种是“Agent as a Service”,由后端服务暴露运行接口,工具通过内部 API 调用。这种方式适合产品型 Agent,比如客服、运营助手、内部工作台。
一种是“Agent in the repo”,直接在本地或开发环境运行,工具包括 git、shell、测试和文件编辑。这类模式更适合编码 Agent 和团队内部自动化。
还有一种是“Supervisor + Workers”,由上层 Agent 负责拆解任务,多个下层 Agent 分别处理研究、编码、测试等步骤,再由上层整合和校验。这适合复杂任务,但前提是职责拆分清楚。
无论采用哪种形态,都应坚持同一个原则:不要让每个 Agent 都拥有全部工具。工具权限越泛,系统越难控制,错误和风险也越难隔离。
如果要在一到两周内做出第一版能上线的 Agent,最实际的顺序不是先堆记忆、先做复杂规划、先接一堆工具,而是按可靠性最关键的依赖关系来排。
最合理的起点,是先做工具契约和验证,再做状态 reducer,然后补 tracing,接着准备一小套真实评测数据,再加策略控制和审批流程,最后再补记忆层,且优先做摘要和工件存储,把向量检索放后面。
这个顺序的价值在于,它先把“能不能控制、能不能观察、能不能评估”建起来。这样即使第一版能力还不强,也至少是一个可调试、可迭代、可放心加功能的底座。反过来,如果一开始先追求“看起来很聪明”,往往很快就会得到一个出了问题根本不知道怎么修的系统。
今天的模型已经足够强,很多场景里,差距不再主要来自“谁回答得更像人”,而来自更实际的问题:它是否能选对动作,是否能遵守策略,是否能度量退化,是否能复盘路径,是否能在涉及真实用户、真实数据和真实资金时依然可信。
所以,生产级 AI Agent 的关键结论其实很简单:Agent 部分并不难,难的是把它放进一个可靠的系统里。工具必须像 API 一样被约束,状态必须可确定地演进,记忆必须分层,规划必须可修正,评测必须覆盖轨迹,安全必须在模型之外生效,观测必须细到每一步。
当这些基础设施到位后,模型能力才会真正转化为产品能力。否则,再惊艳的演示,也很难撑过第一次真实上线。