编译器Lexing(二):NFA/DFA
发布于 • 作者: Ethan
手写词法分析器并不神秘,但它很容易写得又长又脆弱。真正高效的做法,通常不是直接写一堆分支和状态变量,而是把“如何识别 token”先写成正则表达式,再把这些规则系统地编译成自动机,最后再生成可执行代码。这条路线之所以成为经典,不是因为它最直观,而是因为它把“描述语言”和“执行识别”分开了。
理解这条路线之后,很多看上去分散的问题会连成一条线:为什么正则表达式足够描述 token,为什么 NFA 和 DFA 都能识别同一类语言,为什么词法分析器喜欢 DFA,又为什么真正的扫描过程还必须处理“最长匹配”和“规则冲突”。这篇文章就按这条主线展开,把词法分析器从规则到代码的核心过程一次讲清楚。
词法分析器的任务,是把输入字符串切成一个个更高层的记号,也就是 token。它不是在理解程序的完整语法,更不是在做语义判断;它做的是更靠前的一步:把字符流分组,识别出哪些子串属于哪一种 token。
这件事看起来像“模式匹配”,而正则表达式正是描述这类模式的自然方式。一个正则表达式并不只是一个写法方便的字符串模板,它代表的是一个形式语言,也就是某个字符串集合。于是,给定一个正则表达式,词法分析器最核心的问题就变成了:
怎样高效判断一个输入串是否属于这个语言。
这个“判断器”通常叫做 recognizer。如果只看单个规则,问题就是“一个字符串是否匹配某个正则表达式”;但真正的词法分析器还要同时面对多个规则,并在它们可能都匹配时作出选择。这也是后面自动机和冲突消解会出现的原因。
正则表达式负责“描述语言”,自动机负责“执行识别”。它们之间的配合之所以紧密,是因为正则语言正好可以由有限自动机识别。
一个有限自动机可以理解成一个会随着输入字符不断移动的状态机。它有:
当输入串逐字符读入时,自动机不断沿着迁移边前进。读完以后,如果它停在接受状态,就接受这个字符串;否则拒绝。
这种模型很适合词法分析,因为 token 的识别往往只依赖“目前读到了哪里”“接下来还能不能继续匹配”,而不需要无限历史。换句话说,自动机只保存识别这个模式所必需的有限上下文。
自动机常见地分成两类:
NFA,也就是非确定有限自动机,允许一个状态在同一个输入字符上走向多个不同状态,也允许 $\varepsilon$ 转移。它的好处是结构灵活,特别适合从正则表达式机械地构造出来。
DFA,也就是确定有限自动机,则要求每个状态在每个输入字符上至多只有一条出边,而且没有 $\varepsilon$ 转移。它的好处是运行特别直接:当前状态加当前字符,下一步去哪里是唯一确定的。
这两类自动机识别的语言能力是一样的,识别的都是正则语言。差别不在“能不能识别”,而在“构造是否方便”和“执行是否高效”:
这正是词法分析器生成器常见的总体设计:先从正则表达式生成 NFA,再把 NFA 转成 DFA,最后把 DFA 压缩并落成代码。
把这整套流程放在一起看,会发现词法分析器生成器和普通编译器非常像。它也有源语言、中间表示、优化和代码生成。
最经典的流程可以写成下面这五步:
这条路线之所以稳定,是因为每一步都对应一个清晰的问题:
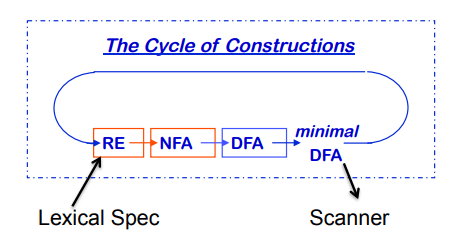
把这条流水线画出来之后,最重要的一点会变得非常清楚:词法分析器不是“直接解释正则表达式”,而是先把规则编译成自动机,再执行自动机。图里的关键不是术语本身,而是中间表示的转移:正则表达式便于书写,NFA 便于构造,DFA 便于运行,最小 DFA 则更适合真正部署。
很多 lexer generator 都沿着这条路线工作。它们的价值并不只是“帮你少写代码”,更重要的是把一整套成熟算法标准化了。手写 lexer 当然可以,但一旦规则增多、冲突变复杂,生成器的系统性优势会迅速放大。
从正则表达式到 NFA,最经典的方法是 Thompson 构造法。它的核心思想非常朴素:给每一种基本成分和运算符准备一个固定模板,再按运算优先级把这些模板拼起来。
单个字符最简单。比如字符 a,可以构造成两个状态,中间一条标记为 a 的边。它表达的意思非常明确:只有读到 a 才能从起点走到终点。
一旦有运算符,做法也还是模板化的:
ab:把识别 a 的小 NFA 和识别 b 的小 NFA 串起来a | b:新建统一入口和出口,用 $\varepsilon$ 边连到两条分支a^*:允许走零次或多次,因此会引入回边和可跳过分支的 $\varepsilon$ 边这里最关键的一点是,$\varepsilon$ 转移让“拼接结构”变得非常简单。它不消耗输入,所以非常适合做“胶水”:连接子表达式、分叉、回环、跳过。
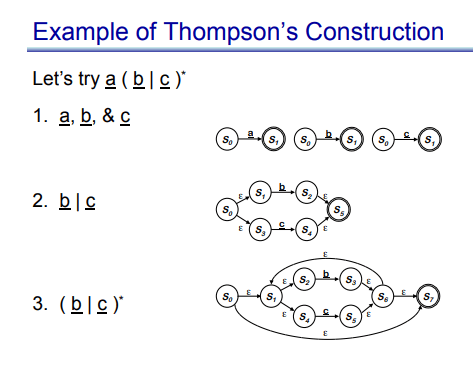
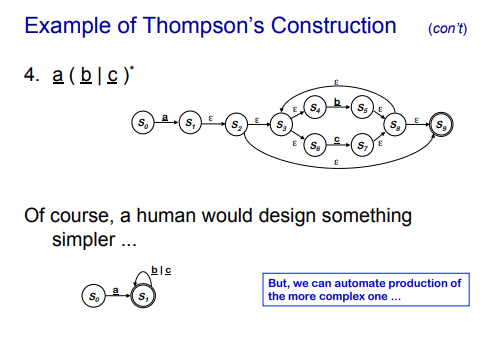
看一个像 a(b|c)^* 这样的表达式时,这张图最有价值的地方,不是最终结果看起来有点复杂,而是它把构造顺序拆开了:先有 a、b、c 的基本片段,再合成 b|c,再加上 Kleene 星号,最后再与前面的 a 顺序连接。Thompson 构造法的本质不是“想出一个聪明自动机”,而是“按规则稳定地产生一个正确自动机”。 这也是它适合自动化的原因。
人类看见一个简单正则时,常常能直接画出更紧凑的自动机;但自动生成不需要追求第一步就最优。只要构造规则统一、结果语义正确,后面还有确定化和最小化来收拾状态冗余。
这其实很像编译器前端生成比较“啰嗦”的中间表示,然后再靠后续优化整理结构。第一步最重要的不是优雅,而是可机械执行且不会出错。
NFA 容易构造,但它不好直接执行。因为一旦一个状态面对同一个输入有多条出路,甚至还能走 $\varepsilon$ 转移,运行时就像同时分叉出很多可能路径。理论上可以把它理解成“只要有一条路径成功,整个匹配就成功”,但实际硬件并不会替你免费并行这些分支。
所以,真正高效的做法通常是把 NFA 预先改写成 DFA。这一步做的事,不是改变语言,而是把运行时的不确定性提前消化掉。
这一步通常叫 subset construction,也叫幂集构造。它的核心想法是:
于是,DFA 的起始状态不再只是 NFA 的单个起点,而是它的 $\varepsilon$-闭包。所谓 $\varepsilon$-闭包,就是从某个状态出发,只靠 $\varepsilon$ 边能走到的所有状态集合。
之后,当 DFA 读入一个字符时,它会:
如果直接执行 NFA,你是在运行时维护很多可能分支。把它变成 DFA 后,这些“可能分支的集合”被预先编号成确定状态,于是运行时只剩单一路径。
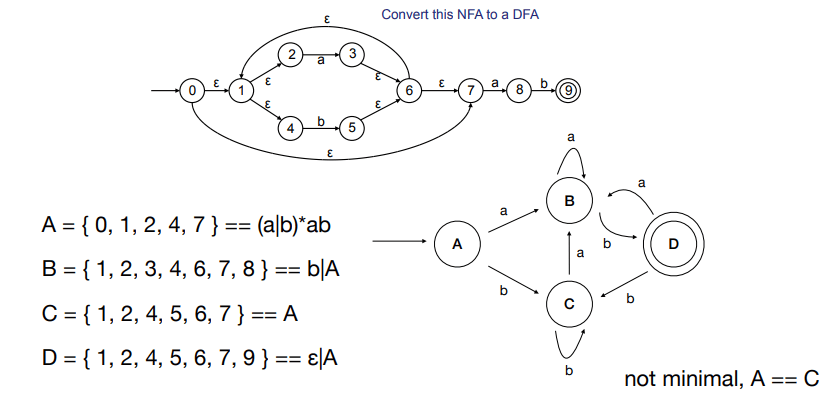
这张图最值得看的地方,是右侧那个由集合命名的 DFA。像 A = {0,1,2,4,7} 这样的状态,并不是新发明出来的抽象点,而是“当前 NFA 可能所在状态集合”的压缩表示。把左边的 NFA 和右边的 DFA 对照起来看,就能直观看到确定化到底做了什么:它没有减少信息,而是把运行中的不确定分支提前编码进状态本身。
DFA 的优势是执行简单。对于每个字符,只需要看“当前状态 + 输入字符”对应的唯一下一状态即可。
但代价也非常现实:如果 NFA 有 $N$ 个状态,那么理论上 DFA 最多可能出现 $2^N - 1$ 个非空状态集合。也就是说,确定化可能带来指数级膨胀。这也是为什么很多实际工具会在速度和空间之间做权衡,而不是盲目追求最大最纯粹的 DFA。
确定化之后得到的 DFA 往往包含冗余状态。有些状态虽然名字不同,但对未来输入的行为完全一样;这种状态没有必要同时保留。
DFA 最小化做的事情,就是把这些等价状态合并。
两个状态是否等价,不看它们长得像不像,而看从这两个状态出发,面对任意后续输入时,接受或拒绝的结果是否总是相同。
经典做法是分区细化:
这个过程的重点,在于发现“可区分行为”。只要某个输入能把两个状态带到不同命运,它们就不能合并。
一旦 DFA 已经最小化,后续生成代码就简单了。最常见的实现方式是二维表:
运行时,扫描器只需要不断做查表:
$$ \text{next_state} = T[\text{state}, \text{input}] $$
这里的 $T$ 是转移表,$\text{state}$ 是当前状态编号,$\text{input}$ 是当前读到的字符或字符类别。这个式子之所以重要,不是因为它复杂,而是因为它说明了 DFA 执行为什么快:每一步都是一次固定成本的查表。
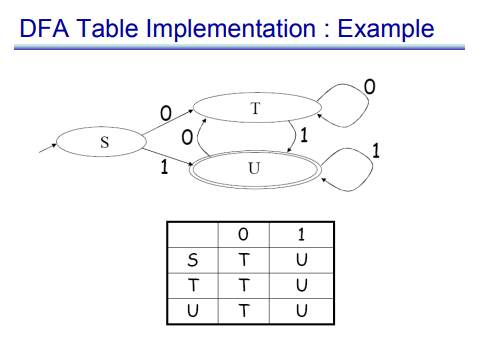
这张表最能说明 DFA 的工程价值。图上方是状态图,下方是对应的转移表;两者表达的是同一件事。真正上线运行时,系统往往更接近下面这张表,而不是上面的圆圈箭头图。自动机理论在这里不是停留在图示层面,它最终落成了一个非常朴素、非常高效的数据结构。
到这里,单个正则表达式怎么识别已经清楚了。但真正的 lexer 从来不是只处理一个规则,而是同时处理很多 token 规则。冲突也正是从这里开始的。
最常见的问题不是“能不能匹配”,而是“有多个匹配时该选谁”。
假设有两条规则:
for[A-Za-z_][A-Za-z0-9_]*当输入是 fort 时,前缀 for 能匹配关键字规则,也能成为标识符的前三个字符。但 lexer 不能在读到 for 时就停,因为后面还有 t,整个 fort 是一个更长的合法标识符。
因此,词法分析通常遵循 maximal munch,也就是最长匹配优先。它要求扫描器总是匹配剩余输入的最长前缀,而不是最早成功的那个规则。
一个直接而有效的思路是:
这套做法的关键,不是遇到成功立刻返回,而是继续向前看,直到再也无法延伸。只有这样,才能保证拿到最长前缀。
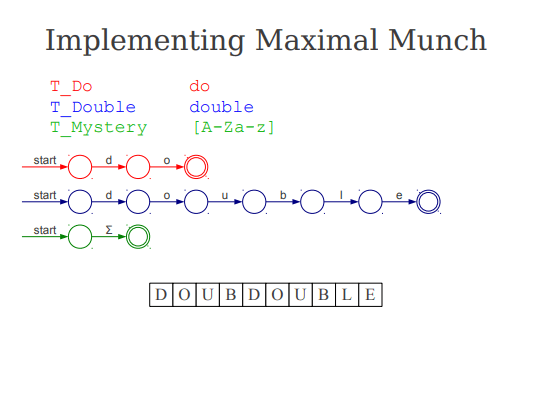
把 do、double 和一个单字符字母规则放在一起看时,最长匹配的必要性会立刻变得直观。扫描器在读到 d、o 时,短规则已经成功了;但它不能立刻交出 do,因为更长的 double 仍然有可能成立。只有继续推进到更后面,直到所有候选无法再延伸,扫描器才能安全地确认应当选择哪一个 token。图里连续的状态推进,正好展示了“持续前进、记录最近成功、最后回退确认”的过程。
最长匹配并不能解决所有冲突。比如 double 既可能被关键字规则匹配,也可能被标识符规则匹配,而且两者匹配长度一样。
这时就需要第二层规则:当匹配长度相同,按规则顺序或显式优先级消解冲突。
所以,常见词法分析策略其实是两层:
这也是为什么关键字规则通常写在标识符规则之前。它不是语法层面的特殊待遇,而是词法层面的冲突消解策略。
把正则表达式编译成自动机,是词法分析里极其成功的方法。它成熟、稳定、可自动化,而且非常适合 token 这类局部结构的识别。
但它的能力边界也很明确。自动机擅长的是正则语言,而不是完整编程语言的语法和语义。
这意味着:
换句话说,lexer 很强,但它强在“切分字符流”,不是强在“理解程序”。
词法分析器之所以常常从正则表达式一路走到自动机,不是因为这是一条历史遗留的老办法,而是因为它把问题拆得刚刚好:规则用正则表达式写,构造用 NFA 承接,执行用 DFA 加速,规模用最小化控制,歧义再用最长匹配和优先级处理。这是一整套从表达、构造、优化到运行都能闭环的方案。
一旦把这条主线看清楚,很多编译原理里的术语就不再零散。正则表达式不是孤立的记号系统,自动机也不是抽象练习题,它们共同构成了词法分析最核心、也最工程化的一层基础设施。