编译器Parsing(二):LL(1)文法和解析器
发布于 • 作者: Ethan
编译器里的语法分析,看起来像是在“检查程序符不符合语法”,但真正的核心其实是搜索一条正确的推导路径。同样一套上下文无关文法,可以从顶向下猜接下来该展开什么,也可以从底向上把已经读到的符号一步步归约回开始符号。LL 和 LR 的差别,正是在这里展开的:LL 更直接、更容易手写,但要求文法更受约束;LR 更强大、更接近真实编程语言的需要,但实现也更复杂。
理解这件事,关键不是死记术语,而是抓住三条主线:什么叫推导,为什么有些文法不能靠一个向前看符号做顶向下分析,以及底向上分析为什么能处理更多语法形式。把这三件事串起来,LL(1)、预测分析、移进归约、LR(0) 状态这些概念就会自然落到实处。
上下文无关文法由终结符、非终结符、开始符号和产生式组成。产生式的左边一定是非终结符,右边则是终结符和非终结符组成的串。语法分析要做的,就是从开始符号出发,找到一条能生成输入串的推导过程。
比如下面这类表达式文法:
$$ S \to E + S \mid E $$
$$ E \to \text{number} \mid (S) $$
它可以生成像 (1 + 2 + (3 + 4)) + 5 这样的串。问题在于,同一个输入通常不只存在一种“展开顺序”。你可以每次优先展开最左边的非终结符,这叫最左推导;也可以每次优先展开最右边的非终结符,这叫最右推导。两者最终可能生成同一个句子,但中间经过的步骤不同。
这一点很重要,因为后面的 LL 和 LR,分别就是沿着这两条路线组织出来的:
这不是术语上的小差别,而是两类分析器能力边界的来源。
顶向下分析从开始符号出发,一路往下展开语法树。理想情况是:分析器看到当前要处理的非终结符,再看一眼当前输入符号,就能唯一确定该用哪条产生式。满足这一点的文法,就是 LL(1) 文法。
这里的 LL(1) 可以拆开理解:
L 表示从左到右扫描输入L 表示构造最左推导1 表示只看 1 个向前看符号难点在于,并不是所有文法都满足“看一眼就能选规则”。
还是看前面的表达式文法:
$$ S \to E + S \mid E $$
$$ E \to \text{number} \mid (S) $$
当输入以 ( 开头时,当前非终结符是 S。这时有两个选择:
问题是,这两条产生式的右边都以 E 开头,而 E 又都可能从 ( 开始。也就是说,只看当前一个输入符号 (,分析器无法判断到底该选哪条规则。
这正是 LL(1) 失败的典型模式:同一个非终结符的多个候选产生式,在开头部分长得太像,导致 1 个向前看符号不够用。
遇到这种冲突,通常不是修改语言本身,而是改写文法的写法,让决策点尽量往后推。最常见的方法有两个:左因子提取和消除左递归。
对于
$$ S \to E + S \mid E $$
两个候选都有公共前缀 E。更适合 LL(1) 的写法是先把这段公共前缀提出来:
$$ S \to ES' $$
$$ S' \to \varepsilon \mid +S $$
$$ E \to \text{number} \mid (S) $$
这样一来,分析器先稳定地把 E 读完,再根据接下来看到的是 +、) 还是文件结束,决定 S' 该走哪条规则。原来那个“太早发生”的选择,被推迟到了真正有足够信息的时候。
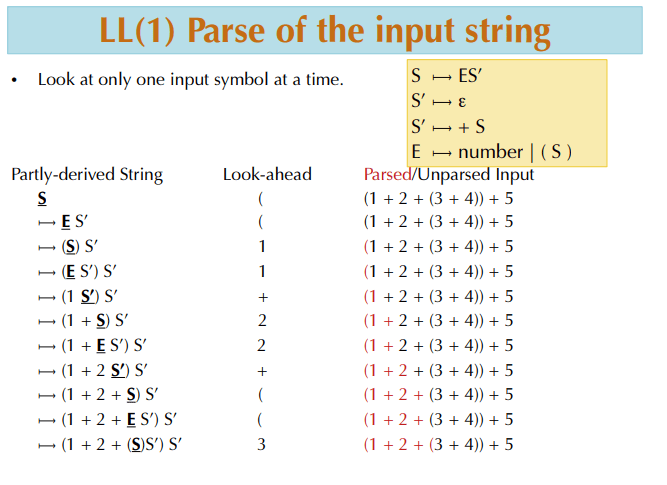
把这个改写后的结构放在一起看,会更容易理解为什么它能工作。图中最关键的是,S 不再一开始就分成两条都以 E 起步的路径,而是统一先进入 E,等表达式主体读完后,再由 S' 决定后面是继续接 + S,还是直接结束。这样,决策点从“表达式开始前”移动到了“表达式结束后”,向前看 1 个符号就足够了。
另一个 LL(1) 的硬约束是:文法不能左递归。
比如:
$$ S \to S + E \mid E $$
这是典型的左递归文法。要是把它直接翻成递归下降函数,parse_S() 一上来就会先调用 parse_S(),连一个输入符号都没消费,就会无限递归下去。
这也是为什么 LL(1) 文法经常需要人为重写。很多自然、直观的表达式文法,并不天然适合顶向下预测分析。
当文法已经满足 LL(1) 条件后,顶向下分析就可以机械化了。做法是建立一个预测分析表:
$$ \text{nonterminal} \times \text{lookahead token} \to \text{production} $$
意思是:当前要展开哪个非终结符,当前输入符号是什么,就查表决定用哪条产生式。
构造分析表要靠两个集合。
第一个是 FIRST。FIRST(γ) 表示从符号串 γ 出发,最终可能出现的第一个终结符集合。
第二个是 FOLLOW。FOLLOW(A) 表示在某个句型里,非终结符 A 后面可能直接出现哪些终结符。
填表规则可以概括成两步:
(A, a) 的表项里,其中 $a \in FIRST(\gamma)$(A, b) 的表项里,其中 $b \in FOLLOW(A)$如果某个表项里最终出现了两条不同产生式,这个文法就不是 LL(1)。
对于上面改写后的文法,像 E 这样的非终结符,看到 number 时选 $E \to \text{number}$,看到 ( 时选 $E \to (S)$;而 S' 看到 + 时选 $S' \to +S$,看到 ) 或 $ 时选 $S' \to \varepsilon$。整个过程没有歧义。
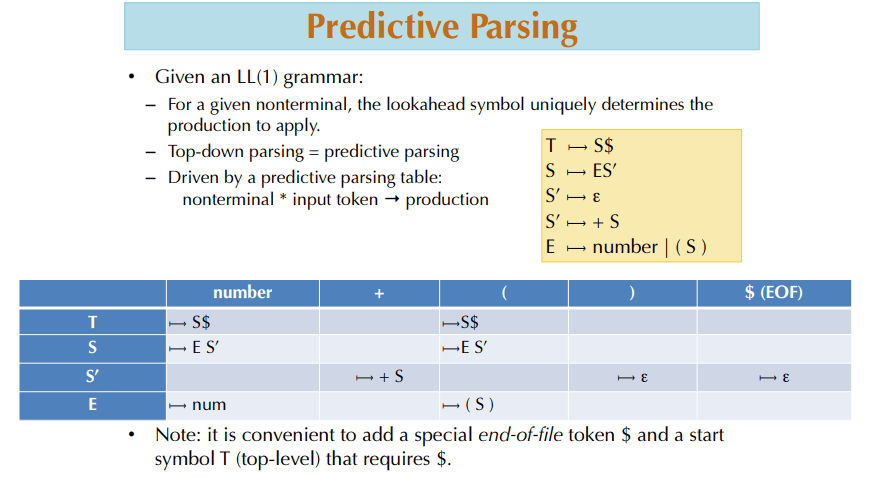
这张表的价值,不只是“把规则列出来”。更关键的是它把 LL(1) 的核心条件可视化了:每个格子最多只能有一个答案。只要某个格子里出现冲突,说明单符号预测已经不够;如果所有格子都唯一,递归下降分析器就能稳定工作。
在实际实现里,FIRST 和 FOLLOW 往往不是一眼就能写出来的,而是通过集合方程反复迭代,直到不再变化。这个过程本质上是一种不动点计算。
这一步和程序分析里常见的数据流迭代很像:先给出初值,再不断传播信息,直到达到最小稳定解。语法分析之所以常被放进编译原理的整体脉络里,原因之一就在这里——它和后面的静态分析在方法上并不割裂。
当分析表建好以后,最自然的实现方式就是递归下降。通常每个非终结符对应一个函数,例如 parse_S、parse_E。函数先偷看当前输入符号,再根据表项决定:
如果某个非终结符是为了左因子提取引入的辅助符号,比如 S',它的解析函数往往会额外接收前面已经构造好的部分 AST,这样才能在读到更多输入之后,决定如何把树接起来。
从工程角度看,LL(1) 最大的优点很明显:结构简单,代码直观,手写方便。但代价也同样明显:文法必须先被改造成 LL(1) 形式,很多本来很自然的写法要被拆开、重组,甚至引入辅助非终结符。
如果说 LL 的思路是“我先猜接下来该怎么展开”,那么 LR 的思路更接近“我先把已经读到的部分收集起来,等证据足够再归约”。
这就是底向上分析。
LR 的全称可以拆成:
L:从左到右扫描输入R:恢复最右推导k:允许看 k 个向前看符号它比 LL 更强大,原因在于它不要求你在结构还没读完整的时候就做决定。很多左递归文法、很多更接近程序语言自然写法的文法,对 LR 来说反而更友好。
顶向下分析最痛苦的地方,是你必须过早做判断。比如看到输入开头是 (1 + 2 时,LL 风格的分析器会被迫推测整棵树后面长什么样,才能决定当前展开哪个规则。
但底向上分析并不急着猜。它一边读入,一边把已经看到的符号压到栈里。只有当栈顶的某一段明确匹配某条产生式右部时,才把那一段归约成左部非终结符。这样,决定往往发生在信息已经足够的时候。
对左递归表达式文法来说,这一点尤其重要。像
$$ S \to S + E \mid E $$
这样的写法非常自然地表达了左结合,而 LR 能直接处理它;LL 则必须先消除左递归,再左因子提取,文法会变得更绕。
LR 分析最基础的形态是移进归约分析。它维护两个部分:
接下来不断重复两种动作:
Shift 很简单:把当前向前看符号压到栈顶,并向前推进输入。
Reduce 的意思是:如果栈顶恰好有一段符号 $\gamma$,并且存在产生式
$$ X \to \gamma $$
那么就把这段 $\gamma$ 弹出,再把 X 压回栈顶。
这个过程本质上是在倒着重建最右推导。也就是说,LL 在“展开”,LR 在“收缩”;LL 是从树根往叶子走,LR 是从叶子往树根走。

把移进和归约的状态变化放在一起看,底向上分析的节奏会特别清楚。栈里保存的是“已经确认下来的结构前缀”,输入流保存的是“还没处理的后缀”。一旦栈顶出现完整的右部,就立刻归约;如果证据还不够,就继续移进。这个节奏正是 LR 比 LL 更少“提前猜测”的原因。
移进归约听起来简单,但马上会遇到一个关键问题:当前到底该移进还是归约?
有时候栈顶确实能归约,但如果现在就归约,之后会走错;有时候还可能存在多种归约方式。最典型的两类冲突是:
因此,LR 分析的核心不是“归约规则是什么”,而是如何用有限状态概括当前栈前缀,从而判断现在允许做哪些动作。
为了知道当前哪些归约合法,LR(0) 引入了两个关键对象:项目和状态。
一个 LR(0) 项目,就是在某条产生式右边插入一个点 .,表示“已经看到了哪里”。
例如:
$$ S \to .(L) $$
$$ S \to ( . L ) $$
$$ L \to S . $$
直觉上可以这样理解:
如果点已经在最右边,比如 $L \to S.$,就意味着这条产生式的右部已经完整出现,当前状态可能允许一次归约。
构造 LR(0) 自动机时,先给文法加一个新的开始规则:
$$ S' \to S$ $$
初始项目是:
$$ S' \to .S$ $$
但这还不够。因为点后面是非终结符 S,说明接下来可能进入任何一个 S 的产生式,所以需要把这些项目也补进来:
$$ S \to .(L) $$
$$ S \to .id $$
这种“只要点后面是某个非终结符,就把它所有以点开头的产生式补进来,并不断重复直到稳定”的过程,就叫闭包。
这里 again 是一个不动点过程。它的作用是把“当前状态下所有可能的下一步”一次性展开完整。
当一个状态里有若干项目,查看所有点后面可能出现的符号。对其中每个符号 X,都可以构造一条转移:
A -> α . X β 的项目中的点右移,得到 A -> α X . β这样,所有状态和转移连起来,就形成一个 DFA。这个 DFA 不是识别源程序字符串本身,而是在概括:当前栈前缀对应着哪些可能的归约前景。
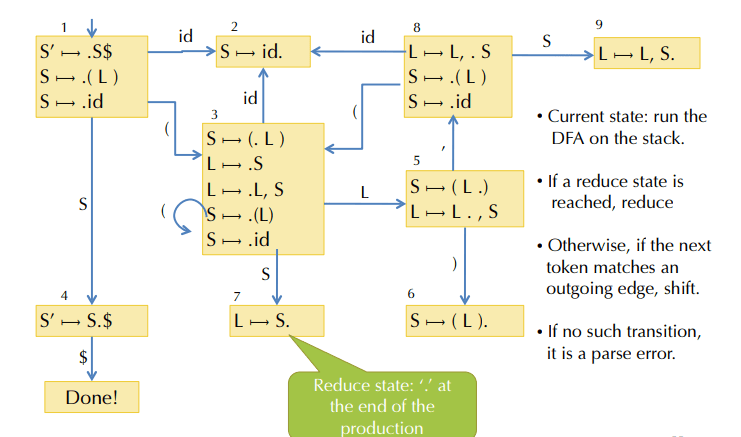
这类 DFA 最值得盯住的不是边数,而是状态里那些带点的项目。点的位置就是“进度条”。当多个项目被放进同一个状态里时,表示当前这段栈前缀兼容多种后续可能;而一旦某个状态里出现点在最右边的项目,就意味着这里存在候选归约。把这个图和前面的移进归约过程连起来看,就能明白 LR 其实是在用自动机替代人工判断。
有了 DFA 之后,LR 分析就可以表驱动执行。通常会用两张逻辑上的表:
运行过程可以概括成:
X 和目标状态压栈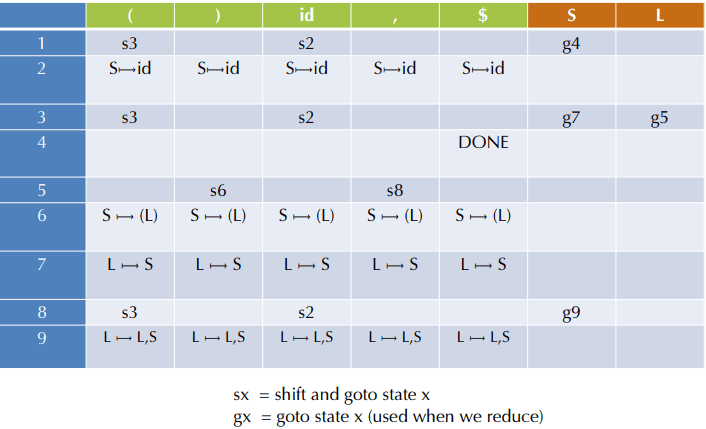
这张解析表把 LR 的执行方式压缩得非常具体。左半边的 action 决定遇到终结符时该移进还是归约,右半边的 goto 决定归约成非终结符后该进入哪个状态。真正运行时,分析器几乎不“理解语法”,它只是沿着这两张表机械地改写栈;而文法知识已经被提前编译进状态和表项里了。
LR(0) 故意不看任何向前看符号,因此它很干净,也很适合教学。但它的限制也很明显:只要某个状态里既存在归约候选,又可能继续移进,LR(0) 就无能为力。
在 LR(0) 中,如果状态里有点在最右端的项目,分析器会倾向于“立刻归约”。问题是,有时候正确做法其实是再看一下下一个输入符号。
例如某些表达式文法里,栈上已经形成一个 E,这时既可能把它归约成更高层的 S,也可能继续读入一个 +,把它当成更长表达式的一部分。这里就会出现移进/归约冲突。
类似地,如果一个状态里同时出现两个可以完成的项目,就会产生归约/归约冲突。
这也是为什么真实编译器里更常见的是:
它们都比 LR(0) 多了一点判断信息:至少允许结合 1 个向前看符号来消解冲突。这样既保留了 LR 底向上的表达能力,又把过于粗糙的“无脑立刻归约”改造成了更精确的决策。
把整件事压缩来看,LL 和 LR 的差别主要落在四点上。
LL 必须在结构还没读出来时就决定怎么展开,所以要求文法足够“好猜”。
LR 则先收集证据,等右部真的出现在栈顶时再归约,因此更晚决策,也更稳。
LL(1) 通常需要:
LR 对自然文法更宽容,尤其擅长处理左递归表达式结构。
LL 更像一组互相递归的函数,思路直接,手写方便。
LR 更像一台表驱动状态机,前期构造状态和表更麻烦,但自动化程度高,也是 parser generator 最常走的路线。
LR 文法严格强于 LL 文法。 这不是说 LL 没用,而是说在真实语言设计里,很多自然写法对 LR 更友好;而 LL 常用于教学、简单语言、手写解析器,或者经过精心重写后的文法。
语法分析不是“把 token 过一遍规则”这么平面,它更像是在受限条件下寻找推导。LL(1) 的精彩之处,在于它把这个搜索压缩成“看一个符号就能预测”;LR 的精彩之处,在于它把这个搜索转成“沿着栈和状态机逐步归约”。
所以学习这部分内容,最值得建立的认知不是“LL 用 FIRST/FOLLOW,LR 用项目集”,而是更前面的一层:顶向下是在提前决定未来,底向上是在利用已经确认的过去。 一旦抓住这一点,为什么 LL 需要改写文法、为什么 LR 更强、为什么 LR(0) 还会不够用,这些问题都会连成一条清楚的线。