编译器Parsing(一):上下文无关语法
发布于 • 作者: Ethan
编译器不只要把源码切成 token,还要把 token 组织成有层次的结构。if 属于哪个代码块,while 的循环体在哪里,1 + 2 * 3 应该怎样分组,这些都不是词法分析能解决的问题。
词法分析把源码变成 token 流。语法分析,也就是 parsing,把 token 流变成树,再进一步得到更适合后续阶段使用的抽象语法树,也就是 AST。之所以要单独做这一步,是因为程序语言充满了递归嵌套,而正则表达式和有限自动机无法表达这种结构。
这篇文章按一条主线展开:先看为什么词法分析不够,再看上下文无关文法怎样描述结构,接着区分推导、解析树和 AST,最后看结合性、优先级和 LL(1) 预测分析是怎样写进语法里的。
token 流只是线性序列,还没有结构信息。真正有用的是把它组织成“块”“条件”“循环”“表达式”“调用”这些节点,再组成一棵树。
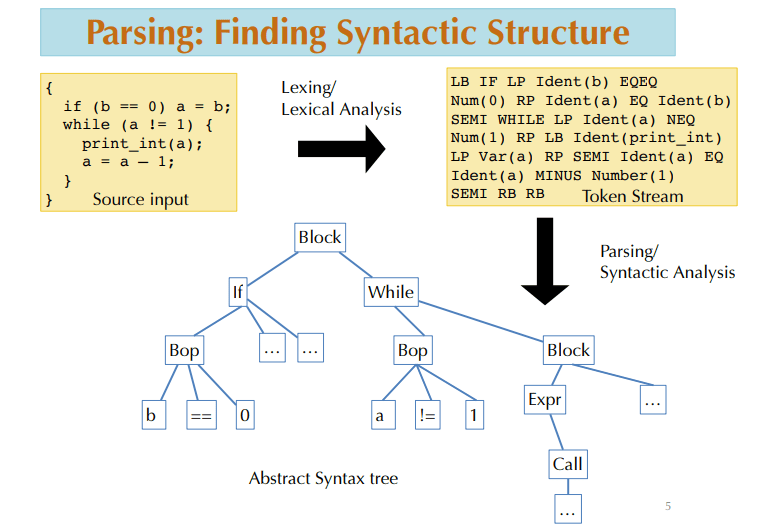
把源码、token 流和 AST 放在一起看,很容易理解为什么编译器要把“读字符”和“读结构”分成两个阶段。源码是文本,token 流是线性结果,AST 才是编译器真正开始理解程序的地方。词法分析和语法分析都在判断输入是否合法,但输出不同:前者输出 token 串,后者输出树。
这也是为什么 parser generator 常被看成另一类编译器。它先接收一种描述语言,也就是上下文无关文法;文法定义哪些字符串合法,以及它们对应哪些解析树;然后工具再把文法转换成更低层的表示,最后生成解析代码。只是这件事比 lexer generator 更复杂,因为语法分析的表达能力更强,代价也更高。
程序语言里最常见的结构,是括号、花括号和成对分隔符的嵌套。(1 + 2 + (3 + 4)) + 5 合法,(1 + 2 + (3 + 4) + 5 不合法,因为少了一个右括号。
这个问题已经超出了正则语言的能力。原因很简单:有限自动机只有有限个状态,只能记住有限多的信息;而括号匹配要求的是无上界计数。见过多少个左括号,后面就要匹配多少个右括号。嵌套深度可以任意大,这不是有限状态能完成的。
一个经典例子是只含 ( 和 ) 的平衡括号语言,也就是 Dyck language。它包含所有括号平衡的串,比如 (()()(((())))),不包含 (())(() 这种不平衡的串。这个语言不是正则语言。直觉上说,自动机读入足够长的一串左括号后,总会把不同长度的前缀落到同一个状态上,于是再也分不清前面到底有多少个左括号,后面就会把某些不平衡的串误判成合法。
所以,语法分析不是更复杂一点的正则匹配,而是需要一种本质上更强的描述工具。上下文无关文法正是为递归结构准备的。
顺着这个角度看,还能得到一个结论:每个正则表达式都能写成上下文无关文法,但反过来不成立。CFG 至少覆盖正则语言能做的事,还能继续表达嵌套和递归。
上下文无关文法的核心是用递归定义语言结构。一个 CFG 包含四部分:
A -> β左边必须是单个非终结符,右边可以是终结符和非终结符组成的串。
最经典的例子,是平衡括号:
S -> (S)S
S -> ε
这里的 S 表示“一个合法的平衡括号串”。第一条规则表示:一个合法串可以由“左括号 + 一个合法串 + 右括号 + 另一个合法串”组成;第二条规则表示:空串也是合法的。它的关键在于:嵌套直接写在定义里。
再看一个更像程序语言的例子,描述“由数字和括号组成的加法表达式”:
S -> E + S | E
E -> number | ( S )
这个文法接受像 (1 + 2 + (3 + 4)) + 5 这样的串。它不只定义“哪些串合法”,还定义这些串可以怎样从开始符号推导出来。
从开始符号出发,不断把某个非终结符替换成某条产生式右侧,这个过程叫推导。例如:
S -> E + S
-> (S) + S
-> (E + S) + S
-> (1 + S) + S
-> ...
-> (1 + 2 + (3 + 4)) + 5
推导强调的是“怎么得到这个串”。解析树强调的是“这个串的结构是什么”。
解析树里,内部节点是非终结符,叶子节点是终结符。叶子从左到右读一遍,就能还原输入 token 序列。更重要的是,树保留了层次关系:哪一部分是子表达式,哪个 + 连接哪两个部分,这些都会体现在树上。
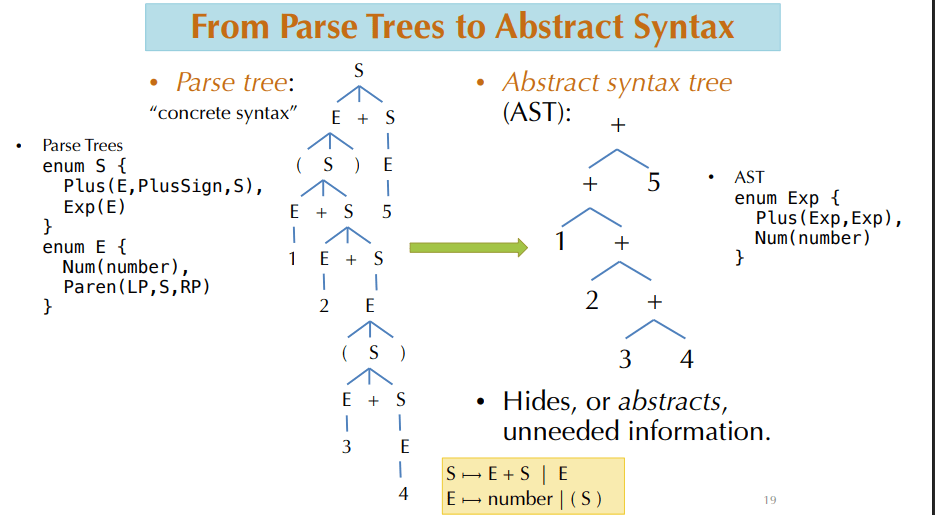
解析树和 AST 保留的信息并不一样。解析树接近具体语法,会保留括号、非终结符层次和产生式展开痕迹。AST 会去掉不影响语义的细节,比如某些中间非终结符和括号本身。对编译器后续阶段来说,AST 更有用,因为它更接近表达式真正的计算结构。
可以把两者的区别概括成一句话:解析树回答“这串 token 是怎么按语法拼起来的”,AST 回答“这个程序真正表示了什么结构”。
推导时,可以在任意一个非终结符上应用产生式。于是有两种常见策略:每次展开最左边的非终结符,叫左最推导;每次展开最右边的非终结符,叫右最推导。
这两种策略的推导过程不同,但只要对应同一个结构,得到的解析树是一样的。推导顺序是搜索路径,树才是结果。
CFG 的递归能力很强,但也容易写出“看起来像文法,实际上生成不了任何字符串”的规则。
比如:
S -> E
E -> S
或者:
S -> ( S )
它们的问题都一样:永远绕不回只含终结符的串,所以不存在有限步推导,语言实际上是空的。判断标准很直接:每个非终结符都应该最终有机会改写成纯终结符串。
文法不只是“字符串是否合法的规则表”。对编程语言来说,它还决定表达式如何分组。一旦分组确定,结合性和优先级也就确定了。
看这条加法文法:
S -> E + S | E
E -> number | ( S )
这里 S 出现在 + 的右边,所以它是右递归。结果是,1 + 2 + 3 会被解析成 1 + (2 + 3),也就是右结合。
如果想把 + 设成左结合,就要改写文法。文法的写法不是表面形式,它会直接决定 AST 的形状。
再看一个更短的写法:
S -> S + S | ( S ) | number
这个文法有歧义。1 + 2 + 3 可以对应两棵不同的树,一棵是 (1 + 2) + 3,另一棵是 1 + (2 + 3)。
对加法来说,这个歧义不一定影响结果,因为普通整数加法满足结合律。但很多运算不是这样。减法、除法、赋值,都不能随便换分组方式。更麻烦的是,一旦同时出现不同运算符,歧义还会扩散到优先级上。
1 + 2 * 3 就是一个标准例子。解析成 (1 + 2) * 3,结果是 9;解析成 1 + (2 * 3),结果是 7。所以编译器不能只说“这串输入合法”,还必须给出唯一的结构解释。
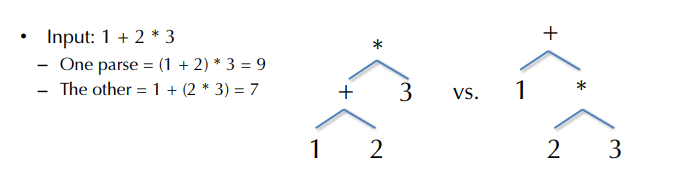
这里的关键不是“有两种写法”,而是同一输入可以长成两棵不同的树。只要树不同,语义就可能不同。
常见做法是为不同优先级引入不同层级的非终结符,让高优先级运算离叶子更近、离开始符号更远。比如:
S0 -> S0 + S1 | S1
S1 -> S2 * S1 | S2
S2 -> number | ( S0 )
这里最外层的 S0 负责加法,下一层的 S1 负责乘法,S2 负责原子表达式。这样一来,乘法天然比加法优先级高,因为它发生在更深的层次里。递归方向同时决定结合性:上面的写法让 + 左结合,让 * 右结合。
这条经验很重要:优先级是语法层级,结合性是递归方向。
从理论上说,解析一个一般 CFG,本质上是在搜索推导或解析树。这件事能做,但代价不低。对一般上下文无关文法,实用算法通常是 $O(n^3)$,其中 $n$ 是输入长度。对编译器来说,这往往太慢。
所以工程上的常见做法不是支持所有 CFG,而是限制文法形状,换取线性时间解析。这就引出了 LL、LR 这些文法家族。它们更像是为了让解析器高效、可实现而加上的结构约束。
LL(1) 可以拆开理解:
L 表示从左到右读输入L 表示构造左最推导1 表示每次只看 1 个向前看符号真正的要求是:当解析器面对某个非终结符时,只看当前 1 个 token,就能唯一决定该用哪条产生式。
前面的加法文法做不到这一点:
S -> E + S | E
E -> number | ( S )
问题在于 S 的两条候选产生式都有相同前缀 E。当输入以 ( 开头时,解析器知道应该先进入 E,却还不知道整个 S 是单独一个 E,还是 E + S。这个决定要等读完整个左边表达式、再看后面有没有 + 才能做出。也就是说,问题不在输入,而在文法把决策点放得太早。
解决办法是把共同前缀先抽出来:
S -> E S'
S' -> ε | + S
E -> number | ( S )
现在解析 S 时不需要立刻决定“有没有加号”。先把前缀 E 读完,等真正来到 S',再根据当前 token 判断:如果看到 +,就走 + S;如果看到右括号或输入结束,就走 ε。

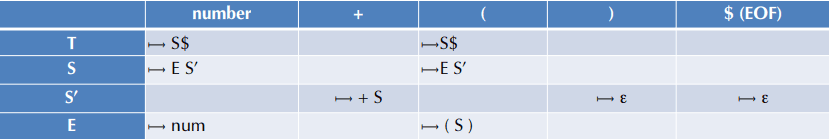
这类改写叫左因子提取。它不改变语言本身,只是把选择点移到真正可以判断的位置。
LL(1) 还有一个硬约束:文法不能左递归。比如:
S -> S + E | E
如果把它直接翻译成递归下降函数 parse_S(),这个函数一开始就会再次调用 parse_S(),输入却一点没消耗,于是程序会无限递归。
所以把文法改写成 LL(1) 时,通常要同时做两件事:提取公共前缀,消除左递归。前者解决“看 1 个 token 还无法决定”的问题,后者解决“解析器一上来就自我调用”的问题。
一旦文法是 LL(1) 的,就可以把“根据非终结符和当前 token 选择产生式”做成一张预测分析表。
它的行是非终结符,列是输入 token,表项是应该使用的产生式。通常还会引入一个额外的顶层开始符号,比如:
T -> S $
这里的 $ 表示文件结束符。这样解析器不只要确认表达式本身合法,还要确认输入正好在这里结束。
构造这张表时,核心要用到两个集合:FIRST 和 FOLLOW。
对于一个产生式 A -> γ:
γ 能推导出的串,哪些 token 可能出现在最前面,这些 token 构成 FIRST(γ)。对每个这样的 token,都把 A -> γ 填进表里。γ 还能推出空串 ε,那就再看哪些 token 可能出现在 A 后面,也就是 FOLLOW(A),并把 A -> γ 填进这些位置。只要整张表里每个单元格最多只有一条产生式,这个文法就是 LL(1) 的。只要某个位置需要填两条规则,就说明只靠 1 个向前看符号还做不出唯一决策。
在实现上,这张表几乎就是代码生成的蓝图。可以为每个非终结符生成一个解析函数,比如 parse_A。函数先看当前 lookahead token,再按表项选择规则,然后依次消费终结符、递归调用别的解析函数、构造 AST。那些为左因子提取引入的辅助非终结符,有时还会接收已经构造好的部分 AST,等读到更多输入后再把整棵树补完整。
换句话说,LL(1) 是一种很容易直接翻译成递归下降代码的文法形状。
把这些内容连起来看,语法分析最核心的价值很统一:它在解决结构确定性。
正则表达式做不到无限嵌套,所以不足以描述真实程序语言。上下文无关文法补上了这件事,让表达式、语句块和括号结构可以被递归定义。推导、解析树和 AST 分别对应生成过程、具体结构和语义骨架。结合性和优先级不是后面补上的小规则,而是应该提前编码进文法的结构约束。到了工程实现上,LL(1) 又把这些结构决策变成了可以线性时间执行的解析流程。
编译器之所以能看懂程序,不是因为它读到了字符,也不是因为它记住了 token,而是因为它最终得到了一棵唯一、明确、可计算的树。