高级计算机架构(十):番外-当芯片不再靠单块变大时 计算性能开始转向封装与连接
发布于 • 作者: Ethan
今天讨论芯片性能,已经不能只盯着晶体管数量或者制程节点。更关键的变化是,性能、带宽、功耗和成本之间的平衡,正在越来越多地由“怎么把不同功能拼起来”决定。芯粒、3D 堆叠、硅中介层、背面供电,这些技术背后的共同主线很明确:当单片芯片继续做大越来越贵、越来越难时,先进封装和互连开始接过接力棒,成为继续提升系统能力的主要路径。
这条路线之所以值得关注,不只是因为它能做出更快的处理器,更因为它改变了芯片设计的基本方法。过去常见的思路,是在一个大晶圆裸片里尽量塞下更多逻辑与缓存;现在更现实的做法,往往是把计算、内存、I/O 和控制拆成多个部分,再通过封装把它们组合成一个系统。这样做并不完美,但它越来越像是高性能计算继续前进的现实答案。
最核心的原因,是先进制程下的成本上升速度,已经快到足以改变设计策略。
一方面,制程越先进,设计成本和建厂成本越高。随着节点从 65nm 一路推进到 5nm,芯片设计成本从几千万美元级别上升到数亿美元级别,晶圆厂建设成本也从数亿美元上升到几十亿美元。这意味着,继续依靠单一超大裸片去追求性能,财务压力会越来越重。
另一方面,大芯片在制造上更容易碰到良率问题。晶圆上的缺陷密度不会因为芯片更大就自动下降,裸片面积越大,踩中缺陷的概率越高,可用裸片比例也就越低。把一个大设计拆成多个较小芯粒,通常能提高良率,降低单颗可用芯片的制造成本。
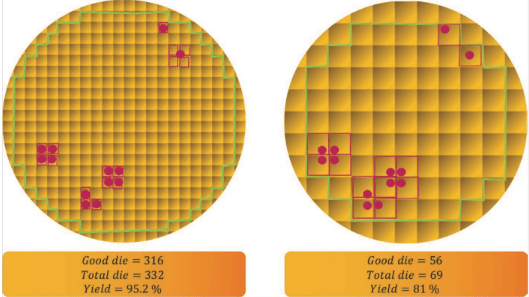
这也是为什么“芯粒”这个概念越来越重要。它本质上就是把原本可能做成一整块的大芯片,拆成多个更小、功能相对独立的裸片,再在封装阶段把它们连成一个整体。很多场景里,它也被叫作 tile。这样做不仅有助于良率,还给系统设计带来更高的灵活性:不同功能模块可以分别采用最合适的工艺,而不是强迫所有模块都用同一种最先进、也最昂贵的制程。
芯片系统里并不是所有部分都适合用同一种制造技术。
逻辑电路追求更快的开关速度和更高的晶体管密度,通常最依赖先进逻辑工艺;但 DRAM、Flash 等存储技术的优化方向并不相同。把这些部分强行做在同一块单片裸片上,不一定是最好的工程选择,也不一定是最经济的选择。
芯粒设计的价值,就在于它允许把不同功能模块分开制造,再在封装层面重新组合。计算芯粒可以追求高性能逻辑工艺,内存则可以采用更适合容量和成本的工艺路线。系统最终获得的是“异构集成”能力:不是让所有模块都向同一种工艺妥协,而是让每一部分都尽量使用适合自己的实现方式。
这也是先进封装被频繁提及的原因。以现代处理器封装为例,封装内部已经不只是“装一块芯片”,而是会同时容纳计算 tile、平台控制 tile、内存以及作为连接基础的 base tile,并通过类似 Foveros 这样的 3D 封装方法把它们叠起来。这样一来,封装本身就从被动外壳,变成了系统架构的一部分。

计算系统的性能瓶颈,很多时候并不在算力本身,而在数据喂不喂得上。
从存储层级看,越靠近计算核心的存储,单位容量通常越贵,但带宽更高、访问延迟更低;越远离核心,容量更大,但性能更差。SRAM 缓存带宽最高,系统主存 DRAM 次之,持久内存和 SSD 容量更大,但速度更慢。对高性能处理器和加速器来说,真正稀缺的常常不是“总容量”,而是靠近计算单元的高带宽内存能力。
这也是 HBM 这类封装内存快速流行的直接原因。它把高带宽内存放到更靠近处理器的位置,在系统层面显著提升数据供给能力。这样做不仅提升带宽,也通常带来更好的单位比特能耗表现和更紧凑的外形尺寸。换句话说,封装内存并不是简单地“多装几颗内存”,而是在重建计算与内存之间的距离关系。
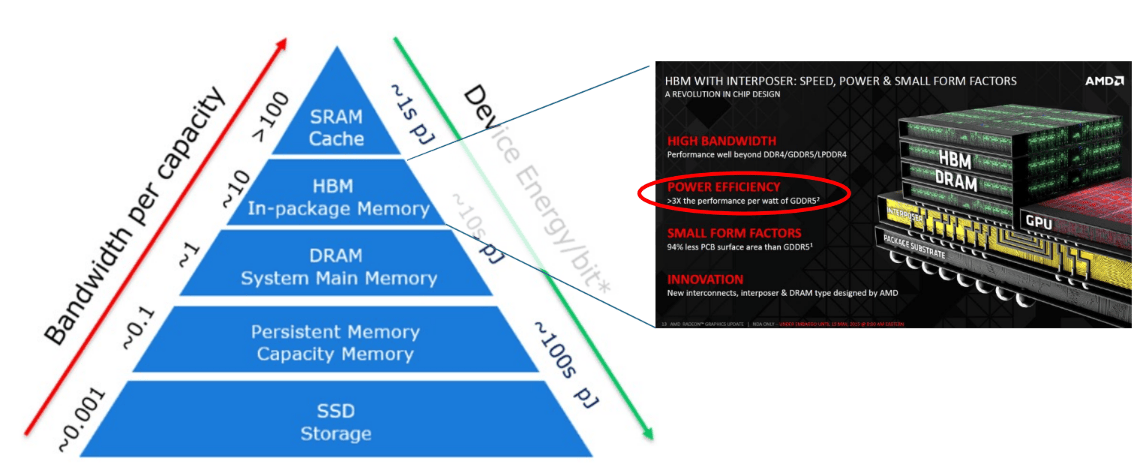
一旦这个问题被放到系统层面看,芯粒和先进封装的重要性就更清楚了。因为你真正需要的,不只是更多晶体管,而是让计算、缓存和高带宽内存以更短的物理距离、更高的连接密度协同工作。
从收益上看,芯粒最直观的优势是成本下降。
把大芯片拆成多个较小裸片后,良率通常会上升;同时,小裸片在光刻 reticle 限制和晶圆切割排布上也更容易做得高效。对于大规模、高性能设计,这种收益非常可观。实际案例里,采用 3D 分区和类似 SRAM-over-logic 的集成方式,成本可以出现非常明显的下降。

但芯粒并不是“白送的性能和成本优化”。拆开之后,原本芯片内部的本地通信,会变成芯粒之间的跨边界通信,而后者天然更难。
这个代价至少体现在三个方面。第一,延迟更高。芯片内部短距离金属互连,和跨芯粒、跨封装的连接,不可能完全等价。第二,带宽更低。哪怕先进封装已经把互连密度做得非常高,跨芯粒链路仍然往往比不上单片裸片内部的连接自由度。第三,集成良率会受影响。你不仅要让每个芯粒本身是好的,还要让它们被成功地组装、连接并通过封装测试。
所以,芯粒设计并不适合任何工作负载。只有当系统划分得足够合理,跨芯粒通信不过于频繁,芯粒方案才会把收益真正转化为整体优势。否则,节省下来的制造成本,可能会被通信代价和封装复杂度部分吃掉。
芯粒方案能不能成立,很大程度取决于封装层面的连接能力。
普通封装下,多个裸片之间的连接能力有限,很难支撑高密度、低延迟的数据交换。先进封装则试图缩小这种差距。无论是硅桥、嵌入式桥接,还是完整硅中介层,它们的目标都是一样的:在封装内部提供更细密、更高效的互连,让多个芯粒在行为上尽量接近单片集成。
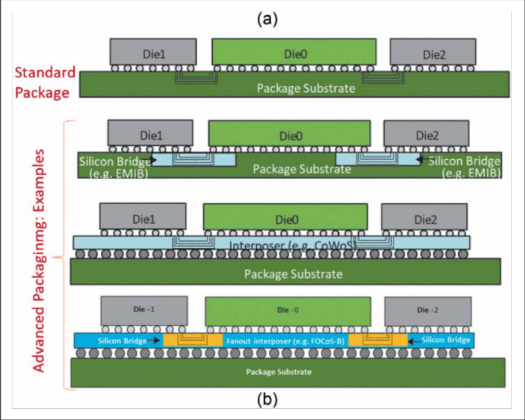
其中,硅中介层尤其关键。它相当于在封装里增加了一层高质量连接底板,把多个芯粒高密度地接到一起。只要系统不是过度依赖芯粒间的大量来回通信,这种方式就能让芯粒集成表现得“几乎像单片芯片一样”。这并不是说它真的没有差距,而是说,在足够合理的架构切分下,这个差距已经小到可以接受。
这也是为什么先进封装如今不再只是制造环节的细节问题,而是架构设计的一部分。系统该怎么切、哪些模块该分开放、哪些连接必须最短,这些问题已经和封装能力绑在一起了。
芯片为什么贵,不只是因为设备贵,还因为流程本身非常长、非常脆弱。
一块芯片的制造,从硅锭切片开始,形成空白晶圆;随后经过几十道工艺步骤,把电路图案转移到晶圆上;再经过晶圆测试,切割成一个个裸片;最后把合格裸片封装、再测试、再出货。每一步都可能影响最终可交付芯片的数量。
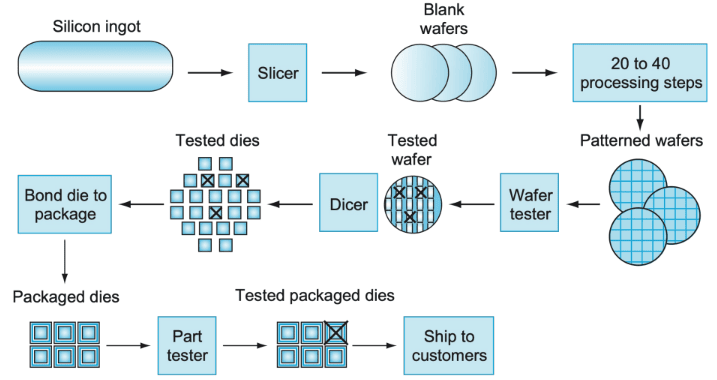
这个流程里,“良率”是贯穿始终的关键词。晶圆测试阶段可能淘汰一部分裸片,封装完成后的成品测试还会继续淘汰一部分。也就是说,芯片不是只要设计成功就算完成,而是要在长链条制造过程中不断通过筛选。裸片越大、工艺越复杂、封装越激进,任何一个环节的损失都可能放大整体成本。
从更细的制造视角看,芯片形成的过程还包括光刻、薄膜沉积、刻蚀、离子注入以及多层金属互连的构建。晶体管本身固然重要,但如果无法高效地把它们连接起来,它们就无法形成真正有价值的系统。
性能提升的另一个关键限制,并不在晶体管本体,而在它们周围越来越复杂的互连网络。
一颗晶体管是否有用,取决于它能否被可靠地连接进整个电路。前端工艺负责做出晶体管,后端布线负责把无数晶体管变成可工作的逻辑与存储结构。随着集成度继续提高,信号线和供电线的拥挤程度不断上升,互连瓶颈就会越来越明显。
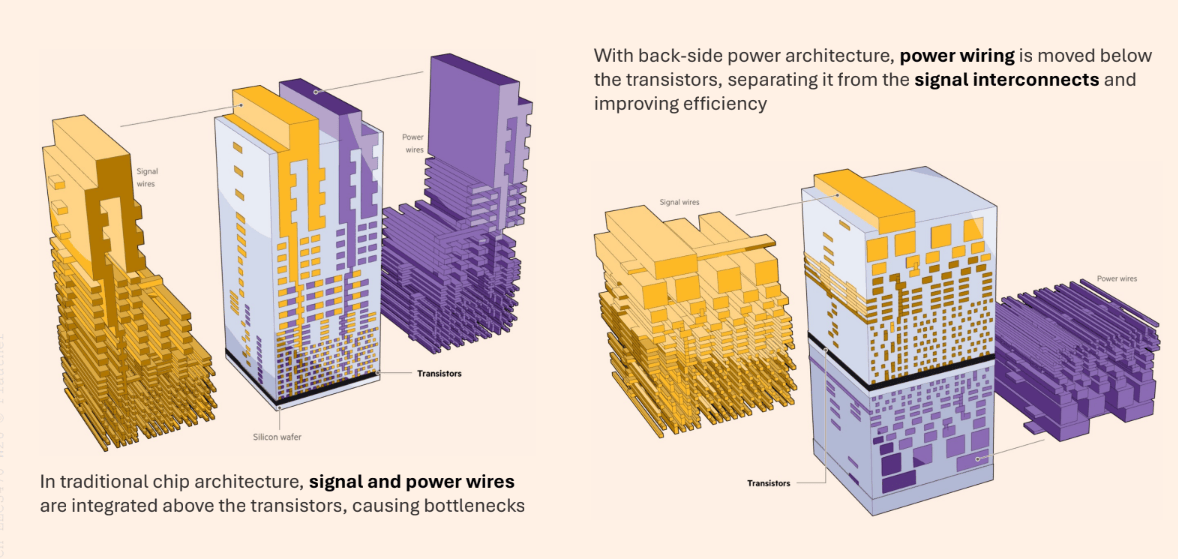
传统架构里,信号线和供电线都堆在晶体管上方,这会带来明显的拥塞与竞争。背面供电架构则把供电网络移到晶体管下方,让上方的互连资源更多地服务于信号传输。这样做的核心价值,不是某个单点参数的小优化,而是重新分配互连资源,减少信号与供电之间的冲突,从而提升整体效率。
这类变化说明了一个重要趋势:制程创新已经不只是“把晶体管做小”,而是“在三维空间里重新安排晶体管、供电和互连的关系”。从这个角度看,先进封装和背面供电其实属于同一类思路:它们都在利用垂直方向的结构重组,换取性能和效率。
过去人们熟悉的一种推进方式,是 Tick-Tock。
所谓 Tick,指的是在新工艺节点上实现已验证过的微架构收缩;Tock,指的是在已经成熟的工艺上引入新的微架构。后来还出现过 Tock+,也就是在成熟工艺基础上再做一轮额外的架构优化。这个节奏背后的逻辑很简单:不要同时冒太多风险,把工艺变化和架构变化分开推进。
但今天的现实是,单纯靠制程推进已经很难再维持过去那种节奏感。工艺更贵、设计更贵、互连更难、内存墙更突出,于是系统创新开始分散到更多层面:架构切分、封装堆叠、内存靠近、供电重构、异构集成。性能增长不再只来自“更小的晶体管”,而是来自“更聪明的系统组织方式”。
这也解释了为什么芯片行业越来越像系统工程。未来的领先设计,很可能不是单一维度最激进的产品,而是能在工艺、良率、内存、互连、封装和成本之间取得最好平衡的产品。
芯片行业正在从“把一切都做进一块大芯片”的时代,走向“把系统拆开、再用封装重新组织”的时代。这个转变背后有两个非常硬的现实:先进制程越来越贵,单片继续变大越来越难;而计算性能真正受限的地方,也越来越多地落在内存距离、互连效率和系统集成方式上。
所以,芯粒不是一个临时技巧,先进封装也不是配角。它们正在成为延续计算性能增长的主舞台。接下来决定一颗芯片好不好,已经不只是它有多少晶体管,而是这些晶体管、内存和互连,是否被组织成了一个真正高效的整体。