MemFactory 正在把记忆型 Agent 的训练变成标准框架
发布于 • 作者: Ethan
论文原文MemFactory: Unified Inference & Training Framework for Agent Memory。
长时记忆已经是 AI Agent 能否真正持续工作的关键能力,但真正难做的不是“让模型记住”,而是把记忆的抽取、更新、检索和训练整合成一套能反复复用的系统。MemFactory 的价值就在这里:它不是再提出一种新的记忆策略,而是试图把这类策略统一到同一个训练与推理框架里,让研究者可以像搭积木一样组合模块、跑实验、做强化学习优化,并直接比较不同记忆范式的效果。
这件事之所以重要,是因为过去的记忆增强方案虽然已经出现了不少有代表性的工作,但实现方式通常高度绑定具体任务,代码结构也彼此割裂。结果是,只要想替换一个检索器、复用别人的更新策略,或者把某种记忆机制接进新的训练流程,往往都要付出大量重复工程成本。MemFactory 的核心判断很明确:记忆型 Agent 真正缺的,不只是更强的 memory policy,而是一套统一、可扩展、能训练也能推理的基础设施。
要理解 MemFactory 为什么值得关注,先要看清记忆型 Agent 和普通序列建模的差别。普通大模型微调,通常围绕输入到输出这一条链路展开;而记忆增强 Agent 处理的是一个持续演化的状态系统。它需要决定什么时候从历史上下文里提取信息,哪些信息值得写入记忆库,旧记忆是否应该删除或改写,当前任务又该从哪里取回最有用的记忆。这个过程不是单次生成,而是一连串相互影响的决策。
这也是为什么单靠静态 RAG 或手写规则很容易碰到瓶颈。随着交互时间变长,记忆会不断堆积,噪声、冗余和冲突都会出现。如果系统没有学会动态地管理记忆,最后上下文会越来越臃肿,检索也会越来越不稳定。相比之下,把记忆管理视为一个序列决策问题,再用强化学习根据结果奖励去优化策略,会更接近真实需求:模型不只是“会读记忆”,而是要学会“如何经营记忆”。
MemFactory 把整个系统拆成四层:Module Layer、Agent Layer、Environment Layer 和 Trainer Layer。这个拆法的意义在于,它把原本缠在一起的记忆流程拆成了清晰的职责边界,让“记忆操作”“策略执行”“环境反馈”“强化学习优化”分别独立,又能组合起来运行。这样做以后,研究者既可以复现已有范式,也可以替换其中某一层做新实验,而不必重写整套流水线。
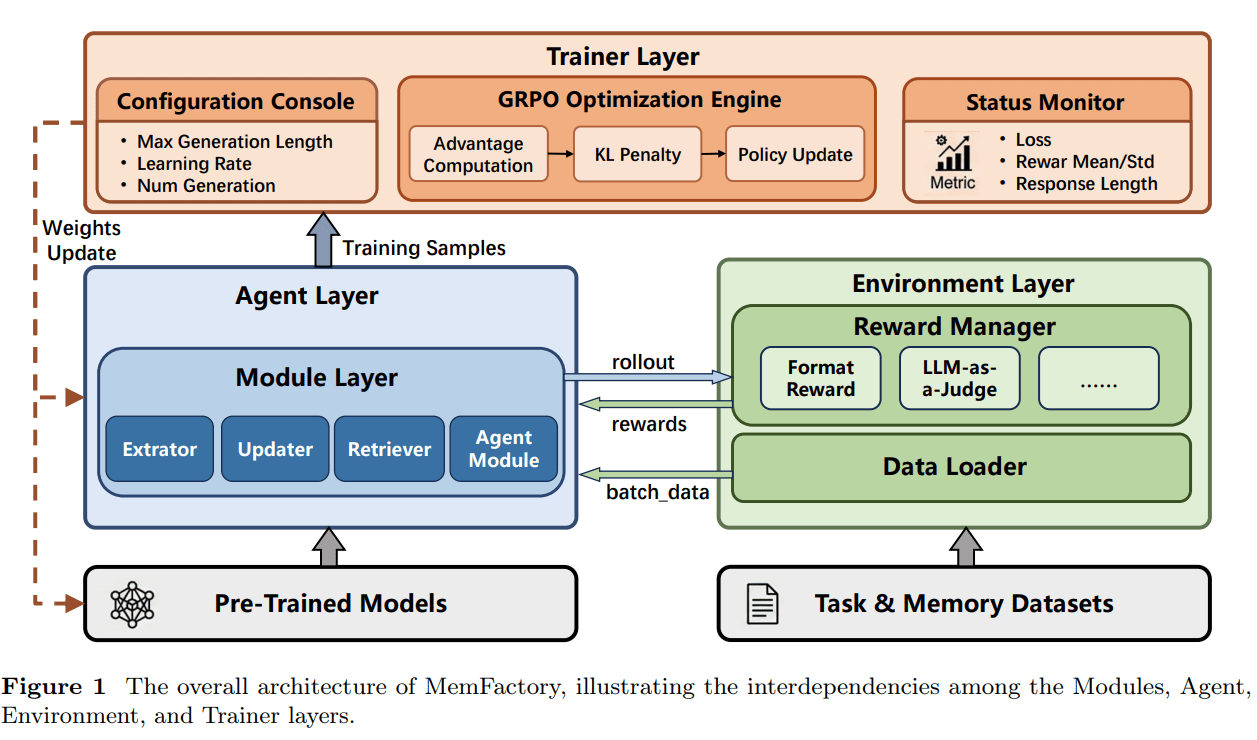
从上到下看,这四层分别解决不同问题。
首先是 Module Layer。这一层负责最原子的记忆操作,也就是抽取、更新、检索,以及一类更整体化的 Agent Module。它相当于把记忆系统拆成最小可组合单元。
然后是 Agent Layer。这一层不发明新记忆,而是把前面的模块拼起来,形成真正执行策略的 Agent。不同模块如何衔接、训练时调用哪种接口、推理时是否走 API,都在这一层完成。
再往下是 Environment Layer。这一层负责把原始数据整理成统一状态,并根据 Agent 的动作给出奖励。也就是说,它既是数据接口,也是奖励管理器。
最后是 Trainer Layer。这一层用 GRPO 做策略优化,把环境给出的反馈真正转化成模型参数更新。训练监控、超参数配置和优化过程都在这里完成。
这四层架构最重要的地方在于,它把“做记忆型 Agent”从一种高度耦合的工程实现,变成了一套可以被替换、复用、比较和训练的标准系统接口。
MemFactory 并不是笼统地说“支持模块化”,而是把模块具体定义成四种类型,每一种都对应记忆生命周期里的一个关键动作。
抽取器的任务,是把原始历史上下文解析成结构化的记忆片段,包括事实、经验和可复用的信息。没有这一层,系统面对的永远只是冗长对话和原始文本;有了这一层,后续更新与检索才有明确对象。MemFactory 里提供了一个朴素实现 NaiveExtractor,用来完成这一步。
抽取出候选记忆之后,系统还需要判断这些内容和已有记忆之间是什么关系。MemFactory 用更新器来完成这件事,并把操作明确分成四类:ADD、DEL、UPDATE 和 NONE。这意味着记忆库不是只会越来越大,而是可以主动删除过期内容、修正旧信息,或者识别出无需变动的部分。对于长时交互来说,这一步是控制记忆质量的核心。
当 Agent 生成响应时,它需要从记忆库中取回最有帮助的内容。MemFactory 既提供基础的语义检索器,也提供带 rerank 的版本。后者先做初步召回,再利用大型推理模型重新排序候选记忆,提高最终命中质量。这个设计很实际,因为很多系统的问题不在“召不到”,而在“召回顺序不够准”。
并不是所有记忆范式都适合严格拆成“先抽取、再更新、再检索”。有些方法更像一个整体化的记忆状态机:它直接根据新上下文和旧记忆,合成下一轮记忆状态,使用时也不是检索局部记忆,而是把整个记忆状态直接放进上下文。MemFactory 为这类方法单独定义了 Agent Module,并实现了 RecurrentMemoryModule 来支持类似 MemAgent 的方案。这样,框架就不会因为过度强调模块拆分,反而限制端到端记忆策略。
模块化只有在接口统一时才真正成立。MemFactory 给模块定义了三类标准接口:generate、rollout 和 inference。这三者分别对应训练中的中间状态生成、接收最终任务奖励的轨迹生成,以及纯推理模式。
这个设计很关键,因为记忆型 Agent 的训练并不总是“生成一句答案然后打分”。有些模块只负责中间状态,它们本身不直接接收奖励;有些模块对应完整 rollout,需要按最终任务结果回传优化信号;还有些模块只是推理组件,根本不参与训练。把这三类接口统一起来以后,同一套 Agent 结构既能跑实验,也能切换到纯推理,还能混合本地模型、OpenAI 风格 API 或高吞吐推理引擎。
为了让训练真正跑通,框架还处理了一个很工程但很重要的问题:长上下文批量生成时,不同样本的长度经常不一致。MemFactory 在 rollout 中对 prompt 左填充、对生成结果右填充,并同步对齐 action mask,这样后续的 advantage 计算才不会出错。别看这是细节,它恰恰决定了框架是概念演示,还是能稳定复现的训练系统。
在强化学习优化层,MemFactory 目前重点支持的是 GRPO,也就是 Group Relative Policy Optimization。它选择 GRPO 的理由很直接:记忆型 Agent 本来就吃上下文长度和显存,若再像 PPO 那样引入一个体量接近策略模型的 value network,训练成本会立刻升高很多。
GRPO 的核心做法是,对同一个输入采样一组候选结果,用组内奖励的均值和标准差来归一化每个样本的优势值,而不是依赖单独训练的 critic。它的优势估计写成:
$$ \hat{A}_i = \frac{r_i - \mathrm{mean}({r_1,\ldots,r_G})}{\mathrm{std}({r_1,\ldots,r_G})} $$
这里,$r_i$ 是第 $i$ 个候选轨迹的奖励,$G$ 是同组采样数量。直观地看,这个公式衡量的不是“这个结果绝对有多好”,而是“它在同组候选里相对有多好”。这样一来,就不需要额外的价值模型来估计 baseline,也就降低了训练显存开销。
对于记忆管理任务,这种做法尤其合适。因为很多奖励本来就是结果驱动的,比如 exact match、格式正确性,或者让模型做裁判给出 LLM-as-a-Judge 分数。GRPO 很适合这类规则型、结果型反馈,能在较低资源消耗下完成 policy optimization。MemFactory 也正是借此,把复杂记忆策略的训练门槛压了下来。
记忆型 Agent 的困难不只在模型本身,还在于数据组织方式很不统一。不同任务的数据格式、上下文组织方式、记忆介质和奖励定义都可能完全不同。MemFactory 在 Environment Layer 中把这个问题单独抽出来处理。
它设计了两类主要环境:一种面向显式记忆库管理,另一种面向长上下文记忆。前者维护可更新的 memory bank,后者直接处理长对话或长文历史。两种环境背后的共同目标,是把原始数据整理成统一状态表示,再配合多维奖励信号完成训练。这样做的好处是,Agent 侧不需要为每个任务重写数据适配逻辑,Trainer 侧也能在统一奖励接口上工作。
这一步看似不如模型结构“显眼”,实际上却决定了框架能不能真的成为基础设施。因为如果环境和奖励仍然各写各的,所谓统一框架就只剩下表面相似。
MemFactory 没停留在“架构设计”层面,而是用公开的 MemAgent 数据和两种开源基座模型做了验证:Qwen3-1.7B 和 Qwen3-4B-Instruct。实验选取了两个主任务测试集和一个分布外测试集,并把每个问题的结果做了四次独立试验平均。整个训练与评估流程可以在单张 NVIDIA A800 80GB GPU 上完成,这说明它并不是只能在极高算力条件下运行的框架。
结果里最醒目的一点,是较小模型的平均成绩相对提升达到 14.8%,较大模型的平均成绩也提升了 7.3%。更具体地看,Qwen3-1.7B 从 0.3118 提升到 0.3581,Qwen3-4B-Instruct 从 0.6146 提升到 0.6595。小模型在主任务集上进步更明显,但分布外测试略有下降;大模型则在各测试集上都更稳定,连分布外设置也有提升。
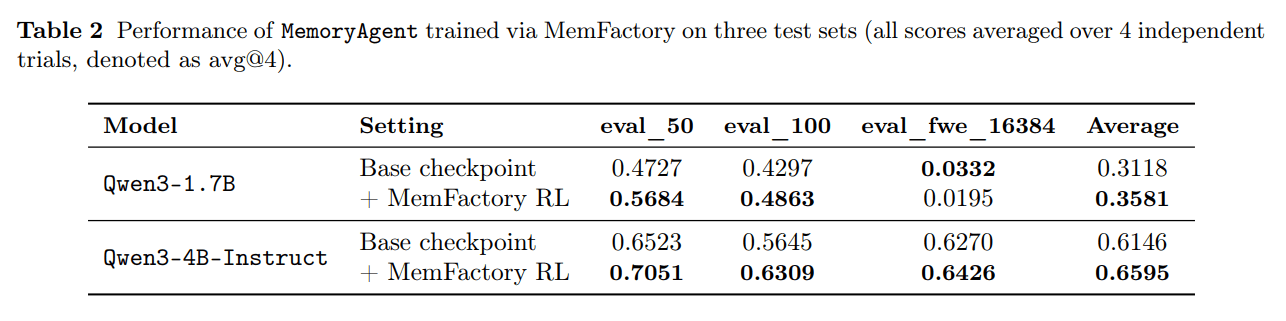
这组结果传达的信息很清楚。第一,MemFactory 确实能把类似 MemAgent 的循环记忆策略在统一训练框架里复现出来,并继续做强化学习优化。第二,这种统一化不是纯工程包装,它能够转化为可测量的任务收益。第三,模型规模越大,这套框架学到的记忆策略越容易稳定迁移到未见设置中。
如果只把 MemFactory 看成“又一个 agent framework”,会低估它的意义。它更重要的作用,是为记忆增强 Agent 提供了一个统一实验面。过去不同记忆方法常常难以直接比较,因为它们的数据格式、训练流程、实现细节和推理方式都不同。现在,如果抽取器、更新器、检索器、环境、训练器都能按统一接口协同工作,那么“比较方法差异”这件事才更接近科学实验,而不是工程体力活。
这会直接改变后续研究的重心。研究者可以更快地回答一些更本质的问题:到底是更新策略更关键,还是检索重排更关键;端到端循环记忆和显式 memory bank 各自适合什么任务;同样的奖励定义在不同模块组合下会产生什么行为差异。统一框架的价值,不只是复现已有方法,而是让这些问题第一次有机会在同一平台上被系统比较。
MemFactory 目前覆盖的是一批代表性记忆范式,而不是所有可能的记忆系统;训练效率也仍有继续优化的空间。换句话说,它现在更像一套可靠的起点,而不是终局方案。
但这并不削弱它的现实价值。对于记忆增强 Agent 来说,今天最稀缺的往往不是某一个更花哨的 memory trick,而是一套能让方法快速落地、统一训练、稳定对比的公共底座。MemFactory 正在补上的,就是这块基础设施空白。只要这套底座继续扩展,未来无论是更复杂的长期记忆系统,还是更强的 RL 驱动 memory policy,都更有可能从零散论文,变成真正可积累、可继承的系统能力。