Meta-Harness 正在把提示工程变成可搜索的软件工程
发布于 • 作者: Ethan
论文Meta-Harness: End-to-End Optimization of Model Harnesses。
大模型系统的上限,往往不只由模型参数决定,还取决于包在模型外面的那层“运行方式”。Meta-Harness 的核心判断很直接:很多时候,真正拉开效果差距的不是模型本身,而是 harness——也就是那段负责存什么、取什么、什么时候取、以及怎么把信息呈现给模型的代码。
这件事重要,是因为一旦把问题看成 harness 优化,思路就会彻底变化。过去常见的做法,是人手工改 prompt、改记忆策略、改检索逻辑,然后靠经验反复试。Meta-Harness 想做的,是把这个过程也交给模型系统本身:让一个 coding agent 读取之前所有候选 harness 的代码、分数和执行轨迹,再自己提出新的 harness,跑评测,记录结果,继续搜索。它不只是“自动改提示词”,而是在做端到端的 harness 工程自动化。
更关键的是,这个方法并不只在一个小任务上成立。它在在线文本分类、检索增强数学推理和 TerminalBench-2 智能体编程三个场景里都拿到了实打实的提升:文本分类比强基线更准、上下文还更省;数学检索策略能跨五个未参与搜索的模型迁移;在 TerminalBench-2 上,自动发现的 harness 甚至超过了强手工系统。
把大模型想成一个“会推理的内核”并不完整。真实系统里,它前后总会包着一层控制逻辑:要不要存历史、怎么压缩历史、从哪里检索例子、提示词怎么拼、工具调用结果怎么回填、什么时候结束。这层控制逻辑,就是 harness。
它之所以重要,是因为 harness 不是装饰层,而是决定模型每一步到底看见什么。同一个模型,换一套 harness,性能差距可以非常大。问题在于,harness 往往是有状态的程序:一个早期的检索或记忆决策,可能会在很多步之后才暴露后果。这使得它很难靠“看一次分数、改一句提示”这种短反馈方式优化。
Meta-Harness 正是抓住了这个特点。它不把 harness 当成几段 prompt,也不把优化目标缩成一个可局部微调的小文本,而是把 harness 当成完整的、可执行的程序来搜索。
很多已有方法也在做文本优化,但它们更适合短回路任务:一次输入、一次输出、一个分数,然后根据总结或评分改一版文本。对 harness 工程来说,这种压缩通常过头了。
原因有三个。
第一,很多方法是无记忆或短记忆的。它们只看当前候选,或者只看少量历史,无法跨很多次尝试比较失败模式。
第二,很多方法主要依赖标量反馈。但 harness 失败,常常不是“它得分低”这么简单,而是“它在第 8 步检索了错误类型的证据,导致第 20 步开始反复验证,最后白白烧掉预算”。
第三,很多方法依赖摘要。摘要对小任务有用,但在 harness 搜索里,摘要会把最有诊断价值的细节抹平:到底是哪一次 prompt 改动和哪一个控制流改动一起出现,哪个是因,哪个只是同一轮改动里的陪跑项,这些信息一旦被压成几句总结,后面就很难还原。
Meta-Harness 的做法是反过来:尽量不要预先替 proposer 压缩经验。它把每次评测产生的代码、分数和执行轨迹都保存在文件系统里,让 proposer 自己决定看什么、比什么、怎么归因。和一些每步只使用几千到几万 token 历史的方法相比,这里单次评测产生的诊断信息规模可以高到千万级 token,量级完全不是一个问题。
从形式上看,Meta-Harness 优化的是这样一个目标:
$$ H^*=\arg\max_H \mathbb{E}_{x\sim X,\ \tau\sim p_M(H,x)}[r(\tau, x)] $$
这里,$H$ 是 harness,$M$ 是固定不变的底层模型,$X$ 是任务分布,$\tau$ 是在 harness 包裹下跑出来的交互轨迹,$r(\tau, x)$ 是任务奖励。直白一点说,目标就是:在不改模型权重的前提下,找到那套让模型在目标任务上表现最好的外部程序。
Meta-Harness 的外循环很简单,但这个“简单”反而是它的关键。它大致做四件事:先准备一批初始 harness;逐个评测;把每个候选的源码、得分和执行日志写进文件系统;再让 proposer 去读这些历史,生成下一批 harness。
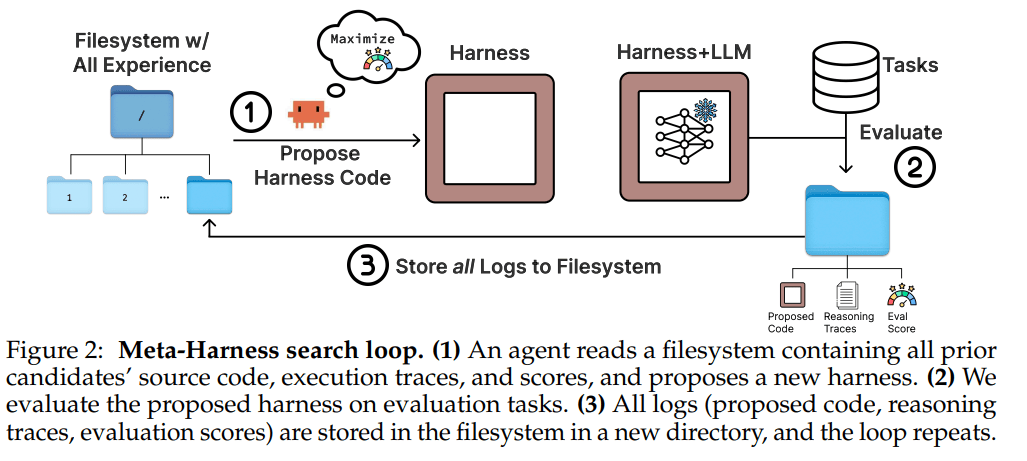
把这张图放进来之后,最值得注意的不是“有一个循环”,而是反馈通道是文件系统,不是单个提示框。这意味着 proposer 不是被动吃一个拼好的上下文,而是像真正的工程师一样,自己用 grep、cat 之类的方式查历史、读代码、翻轨迹、看分数,然后再决定改哪一层逻辑。随着搜索进行,历史会快速超出上下文窗口,所以这种“按需读取”不是锦上添花,而是必要条件。
这种设计带来两个直接结果。其一,搜索发生在代码空间里:可以改检索策略、记忆结构、提示构造逻辑,甚至整段控制流,而不是只对模板做局部填空。其二,proposer 可以做跨候选比较和因果归因:不是只知道“这个版本输了”,而是能看出“这轮失败到底是因为 prompt 重写,还是因为 completion 流程被改坏了”。
在一次 TerminalBench-2 搜索里,proposer 每轮中位数会读取 82 个文件,其中 41% 是旧 harness 源码,40% 是执行轨迹,只有 6% 是分数或摘要文件。这个比例很说明问题:它真正依赖的,不是结果表,而是原始诊断材料。
Meta-Harness 最有意思的地方,在于它最后产出的东西不像传统 prompt engineering 的“花式措辞”,而更像是面向任务结构的推理程序。
在在线文本分类任务中,Meta-Harness 没有只发现一套策略,而是找到了一条准确率和上下文成本之间的 Pareto 前沿。其中有两种特别有代表性。
一种是 Draft Verification。它先从记忆里取最相似的 5 个带标签例子,做一次初判;再以这个初判标签为条件,重新检索支持样本和反对样本,让模型在第二次调用里保留或修正答案。重点不在“两次调用”本身,而在第二次检索已经不再是盲目的近邻搜索,而是围绕模型当前的猜测去找证据和反证。
另一种是 Label-Primed Query。它把“有哪些可能标签”先明确列出来,再为每个标签放一个与当前查询最相关的代表样本,最后补上一组“很相似但标签不同”的对比对。这等于同时给模型三层信息:完整标签空间、每类的代表例子、局部决策边界。
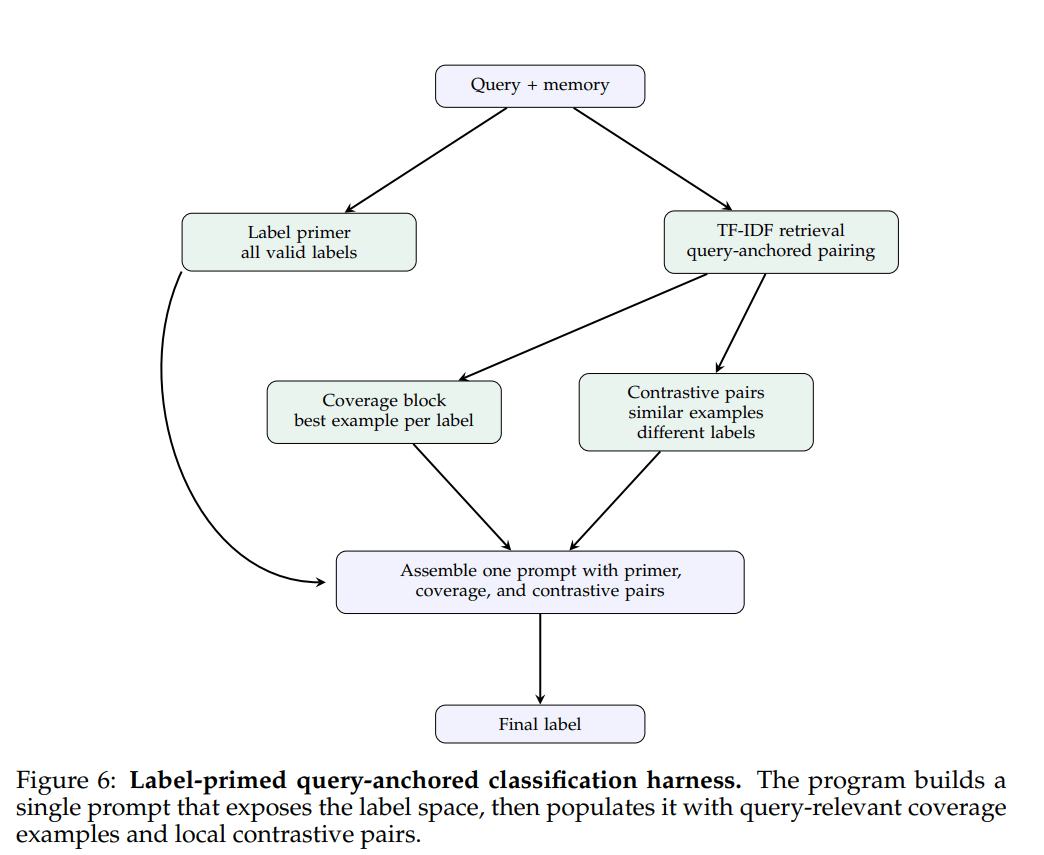
这张图的价值在于,它把高准确率版本的逻辑讲得非常清楚。单看文字,很容易把它误解成“多放点例子”;但图里能看出来,它真正做的是三件不同的事:先暴露答案空间,再做覆盖,最后做对比。覆盖解决的是“别漏类”,对比解决的是“别分错邻近类”,这就是它比普通 few-shot 更像一个分类程序的地方。
在 IMO 级数学题上,简单地“加检索”并不稳定。问题不在于检索无用,而在于检索策略太粗时,往往拿不到对的例子,也不知道该给模型什么形态的参考。
Meta-Harness 找到的最终版本,是一个四路由的 BM25 检索程序。它会先用轻量级词法规则把题目分到组合、几何、数论和默认路线中的一条,然后在各自路线里用不同策略取例子。
组合路线会先取 20 个 BM25 候选,再去重到 8 个,按词法分数和难度重排,最后保留 3 个;几何路线反而偏好一个固定高难参考加两个原始 BM25 邻居;数论路线会额外偏向那些一开始就明确点出技巧的解答;默认路线则根据检索分数是否集中,自适应决定放几个例子。
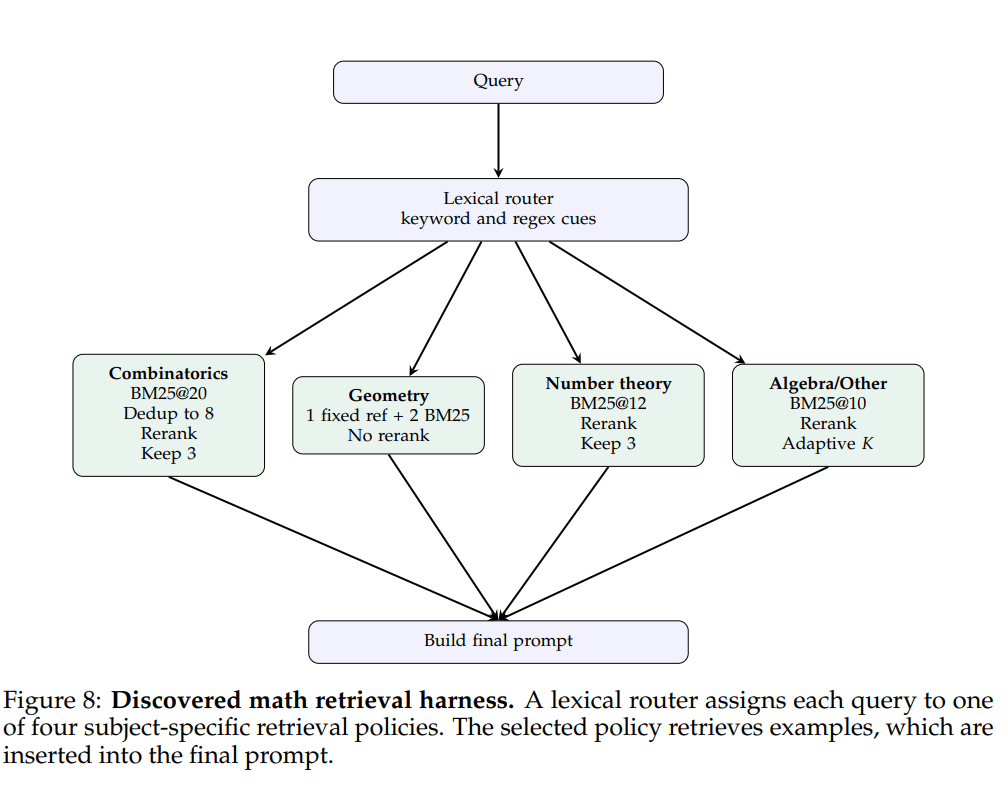
图里的关键信息是,它不是“一个检索器加一个 prompt”,而是先路由,再按领域策略检索。这非常像传统系统里的 mixture-of-experts,只不过这里的 expert 不是模型权重,而是不同的 harness 逻辑。最后的效果也说明这种结构是有意义的:在 200 道未见过的 IMO 级题目上,这套 harness 在五个未参与搜索的模型上都优于无检索基线,平均提升 4.7 个点,整体平均也比固定 BM25 高 1.3 个点。更重要的是,它避开了 dense retrieval 和随机 few-shot 在部分模型上的明显回退。
在线文本分类的结果最容易说明问题。最终选中的高准确率 harness 在三个测试集上的平均准确率达到 48.6%,超过 ACE 的 40.9% 和 MCE 的 40.0%。但这不是靠堆上下文换来的:它只用了 11.4K 的额外上下文,而 ACE 要 50.8K,MCE 要 28.5K。
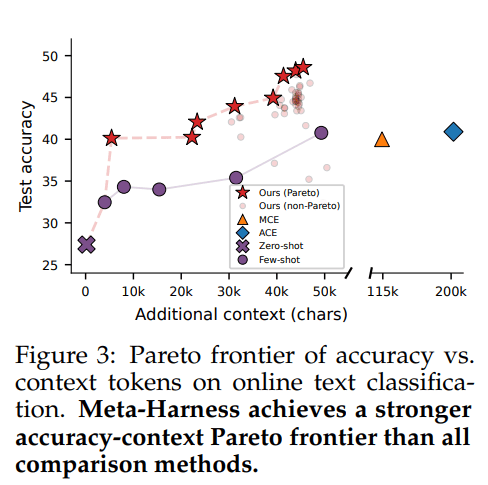
这张 Pareto 图特别值得看,因为它说明 Meta-Harness 的收益不是“把上下文喂得更多”,而是把同样甚至更少的上下文组织得更有效。图上能看到,它把准确率—上下文成本这条前沿整体往右上角推了出去,给了系统设计者更多可选 operating point,而不是只给一个孤立最优点。
更夸张的是搜索效率。在同等评测预算下,Meta-Harness 只用大约十分之一的完整评测次数,就能追平 OpenEvolve 和 TTT-Discover 的最终水平,最后还比它们高出 10 多个点。把 proposer 接口做消融之后,差距更直观:只给分数时,中位准确率是 34.6,最好 41.3;给分数加摘要,也只有 34.9 和 38.7;完整 Meta-Harness 接口拿到的是 50.0 的中位数和 56.7 的最好成绩。这里最关键的结论很明确:原始执行轨迹不是可有可无的细节,它就是搜索能不能成的主要信息源。
而且它没有只在搜索集上讨巧。换到九个完全没见过的数据集上,平均准确率仍然有 73.1%,高于 ACE 的 70.2%。一个很有意思的现象是,few-shot 例子不是越多越好,超过 32 个以后,九个任务里有七个反而下降。这从侧面说明,harness 的价值不在“多塞样本”,而在怎么组织样本。
数学部分的结果说明了另一个重点:检索增强并不是“加一个检索器”就结束了。真正重要的是,什么题走什么检索路线、取多少例子、怎么重排、什么时候宁可少给也不要乱给。
Meta-Harness 在 25 万级搜索集之外,用超过 53.5 万道已解题目构建检索语料,然后在 40 轮搜索中得到 109 个候选 harness,最后选出一个能够跨模型迁移的四路由版本。这意味着被优化的不是某个模型专属 prompt,而是一套更接近“任务程序”的策略。
在 TerminalBench-2 上,Meta-Harness 的表现更像一个会复盘的工程师。
最终结果上,Opus 4.6 版本达到 76.4% 通过率,超过手工设计的 Terminus-KIRA 的 74.7%;Haiku 4.5 版本达到 37.6%,超过 Goose 的 35.5%,在已报告的 Haiku 4.5 智能体里排到第一。
但更有意思的是它是怎么走到这一步的。早期几轮搜索里,proposer 把结构性 bug 修复和 prompt 改写绑在一起,结果连续回退。随后它从历史轨迹里看出,问题可能不在结构修复本身,而在那版“清理导向”的 prompt 会让 agent 在任务尚未完成前删掉关键状态。于是它开始把变量拆开测,先隔离结构修复,再逐步收缩风险,最后转向一个更保守、但更有效的改法:在 agent 循环开始前,先采集环境快照并注入初始提示,让模型一开始就知道操作系统、可用语言、包管理器和 /app 内容,从而减少前几轮无谓探索。
这段搜索轨迹说明的,不只是“它找到了一个好点子”,而是它已经在做某种因果层面的失败分析:先识别混杂项,再做隔离测试,再转向更安全的增量改动。这正是“读完整历史”与“只看摘要”之间的本质差异。
把这些结果放在一起看,会发现 Meta-Harness 的真正贡献不是“又一个优化器”,而是把 harness engineering 从手工艺推向了一种更系统的流程。
它给出的经验很具体:
第一,skill 写得好不好,比多跑几轮更重要。 proposer 需要一段自然语言 skill 来说明目录结构、允许修改什么、产物格式是什么,但这段 skill 最好约束输出和安全边界,而不是把诊断过程写死。
第二,搜索集必须对基线足够难。 如果初始 harness 已经把任务吃得太干净,外循环就几乎没有优化空间。
第三,日志必须可查询。 代码、分数、执行轨迹最好都用统一且可 grep 的格式保存。否则 proposer 不是在做搜索,而是在做文件考古。
第四,昂贵评测前要有轻量验证。 先跑导入测试、接口测试、小样本 smoke test,能把大量无效候选挡在外面。
第五,评测应当独立于 proposer。 proposer 负责提案,外部 harness 负责跑分和落盘,这样整个系统更稳定,也更便于复盘。
这些建议看起来像工程细节,但恰恰说明 Meta-Harness 不是一句“让模型自己改模型”就能落地的魔法。它需要的是一套让经验能被读取、比较、归因和复用的工作流。
Meta-Harness 已经给出一个很强的信号:当搜索空间足够可进入、历史经验足够可读取时,通用 coding agent 开始有机会在 harness 设计上超过人手工写的系统。
它的优势还不只是分数提升。搜索出来的 harness 是可读的、可迁移的,能跨数据集、跨模型复用;代码空间里的过拟合也更容易被肉眼发现,比如硬编码类别映射、脆弱的条件链,都比权重空间里的过拟合更可检查。一次搜索在几小时内就能完成,但产物可能能复用很久。
当然,它也还有明显边界。当前实验主要依赖一个很强的 proposer,底层模型权重是冻结的,未来很自然的方向会是同时共演化 harness 和模型权重:让“模型学什么”与“外部程序怎么组织上下文”一起被优化。另一个重要问题是,不同 proposer 的差异到底有多大,现在还没有被系统展开。
但即便只看现在的结果,Meta-Harness 已经把一个原本很模糊的念头说清楚了:大模型应用的下一轮优化,不一定发生在模型内部,也可能发生在模型外部那层代码里。 当这层代码也开始能被自动搜索,所谓的提示工程,就会越来越像真正的软件工程。