自动机怎样把正则表达式变成真正可用的词法分析器
发布于 • 作者: Ethan
词法分析看起来像一件很朴素的事:把一串字符切成一个个 token。真正把这件事做成可运行、可扩展、还能高效处理冲突的程序时,问题就不再只是“某个字符串是否匹配某个正则表达式”了。更准确地说,一个成熟的词法分析器生成过程,本质上就是一次小型编译:先用正则表达式描述 token 语言,再把它系统地翻译成自动机,接着做确定化和最小化,最后生成执行代码。
理解这条主线之后,很多看似分散的问题都会连起来:为什么 NFA 和 DFA 会成为词法分析的核心中间表示,为什么 $\epsilon$ 转移很重要,为什么 DFA 运行快但可能很大,以及为什么真实的 lexer 还必须处理“最长匹配”和“规则优先级”这两类歧义。
词法分析器的任务,是从左到右扫描输入程序,把字符流分组成更高层的 token。手写这类代码往往枯燥、容易出错,所以实践里更常见的做法,是把 lexer generator 看成一种面向词法规则的编译器。
这条流水线可以分成几步。先设计一种词法规则语言,通常就是“正则表达式加上动作代码”;再给这些规则定义语义,也就是每个正则表达式对应一个形式语言;然后把这些规则翻译成自动机,先得到 NFA,再把 NFA 变成 DFA,并进一步最小化,最后输出真正执行扫描的代码。
这里最关键的一点是,正则表达式的语义不是“某种模糊匹配技巧”,而是一个语言。一个正则表达式由空串 $\epsilon$、空语言、单个字符、并集、连接和 Kleene 星号这些构件组成,它表示的是所有合法输入串的一个集合。对单个正则表达式来说,可以实现一个识别器,把字符串映射成布尔值:输入属于这个语言就返回 true,否则返回 false。
但 lexer 不能停在这里。它面对的不是一个正则表达式,而是很多个 token 规则同时存在的场景。它不仅要回答“能不能匹配”,还要回答“当前位置该切出多长的 lexeme”“如果多个规则都能匹配,该选哪一个”。这也是为什么词法分析需要自动机之外,再加上一整套冲突处理策略。
词法分析之所以能自动化,很大程度上是因为正则语言和有限自动机正好严丝合缝地对应起来。一个有限自动机可以理解成一个有限状态的识别过程:它有一组状态、一个起始状态、一组接受状态,以及若干条转移边。每条转移边要么消耗一个输入字符,要么什么都不消耗,也就是 $\epsilon$ 转移。
自动机处理输入时,会随着读入的字符不断改变当前所处的状态。等输入读完后,如果落在接受状态,就接受这个字符串;否则拒绝。这个模型非常适合描述 token,因为 token 本来就是一种局部、有限记忆的模式识别问题。
NFA 和 DFA 的区别,主要在“当前状态是否唯一”以及“是否允许 $\epsilon$ 转移”。DFA 的每个状态在每个输入字符上最多只有一条出边,也不允许 $\epsilon$ 转移,所以运行时完全没有分支选择。NFA 则可以在同一个状态上对同一个输入字符有多条转移,也可以包含 $\epsilon$ 转移,因此它在概念上像是会“同时走多条路”。
这种非确定性通常会被形容为一种“天使式”非确定性:只要存在一条成功路径,就认为识别成功。现实硬件当然不会替你预知未来,所以实现时要么显式模拟这些分支,要么把 NFA 预先转换成不需要猜测的 DFA。
两者的表达能力并没有差别。NFA 和 DFA 识别的都是正则语言,也就是说,对任意 NFA,都存在一个等价的 DFA;反过来也成立。真正的差别在成本上:DFA 执行时更快,因为每一步都只是查一次转移;但它可能比对应的 NFA 大得多。
把正则表达式变成自动机时,最经典的方法是 Thompson 构造。它的核心思想很简单:不给整个表达式一次性“猜”一个状态机,而是先为每种最基本的构件准备好固定模板,再按运算符优先级把这些模板用 $\epsilon$ 转移拼起来。
单个字符有自己的小 NFA,连接操作把前一个片段的末尾接到后一个片段的开头,并集操作从一个新起点分叉到两个候选分支,Kleene 星号则额外补上“重复”和“跳过”的通路。这样做的好处不是图足够简洁,而是构造过程完全机械化,适合程序生成。
以 $a(b \mid c)^*$ 为例,构造时不会直接从“人眼最简状态机”出发,而是先得到 a、b、c 的基本片段,再把 b \mid c 拼出来,最后对它套上星号,再与前面的 a 连接。自动生成的结果可能不如人工设计的状态机紧凑,但它统一、可靠,而且便于后续继续做算法处理。
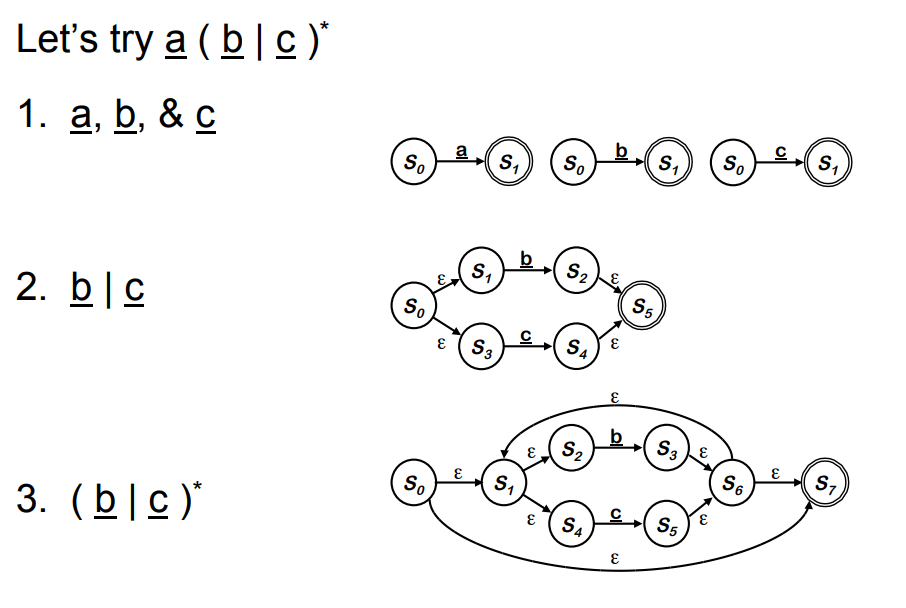
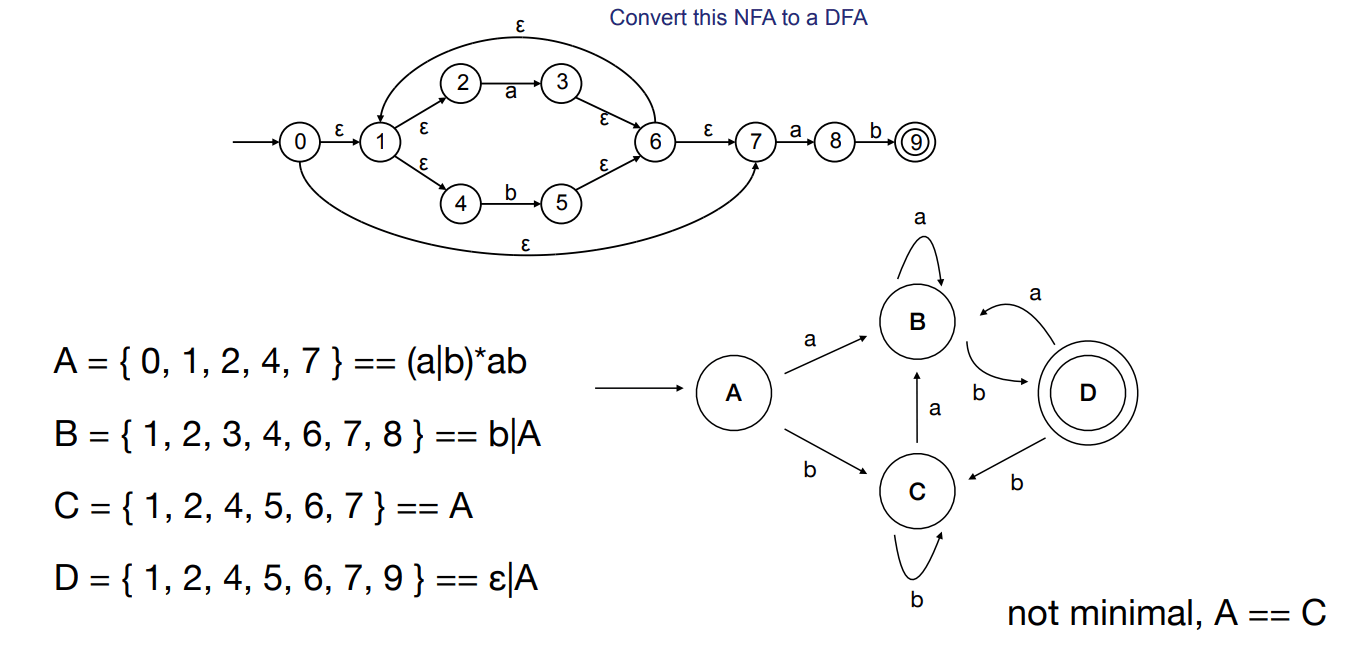
有了 NFA 之后,下一步通常不是直接执行它,而是做确定化,也就是子集构造。这个过程的关键观察是:NFA 在某一时刻可能同时处于多个状态,那么 DFA 就干脆把“这一组可能状态”本身当成一个新状态。于是,DFA 的每个状态,其实都是 NFA 状态集合的一个子集。
构造开始时,DFA 的起始状态不是 NFA 的单个起点,而是 NFA 起点经过所有 $\epsilon$ 转移后能到达的整组状态,也就是它的 $\epsilon$-closure。之后,每读入一个字符,就从当前集合里所有状态同时出发,收集能走到的目标状态,再把这些目标状态继续做一次 $\epsilon$-closure,得到新的 DFA 状态。
这一步从概念上是在“把并行分支收拢成单一步进”。只要一个 DFA 状态对应的 NFA 状态集合里包含接受状态,这个 DFA 状态就是接受状态。子集构造得到的 DFA 与原 NFA 识别同一个语言,区别只在于前者把所有“未来可能性”提前编码进了状态里。
代价也很直接。假设 NFA 有 $N$ 个状态,那么理论上最多可能出现 $2^N - 1$ 个非空子集状态。这里的 $N$ 是原始 NFA 的状态数,而 $2^N - 1$ 表示所有非空状态子集的数量。这就是为什么 DFA 虽然跑得快,但在某些语言上会比 NFA 大很多,甚至呈指数级膨胀。
确定化之后,通常还要做最小化。原因是子集构造得到的 DFA 往往包含冗余状态:它们名字不同,但对后续所有输入的反应完全一样。最小化的基本思路是先把状态粗分成“接受”和“非接受”两类,然后不断检查同一组里的状态是否会在某个输入下跳到不同组。如果会,就把这一组拆开。重复这个过程,直到再也拆不动,最终每个分组就对应最小 DFA 的一个状态。
这类最小化可以用 Hopcroft 这样的经典算法来做,本质上是在寻找“不可区分”的状态。讲得更直白一点:如果两个状态无论往后读什么字符,都会一起接受或者一起拒绝,那么它们就没有必要分开存在。
并不是所有扫描器都严格沿着“正则表达式 → NFA → DFA → 最小 DFA”这条经典路线实现。还有一种常见思路是使用正则表达式的导数,直接从正则表达式构造 DFA。它的优点是实现思路更直接,也更容易扩展到正则表达式的交、补这样的操作,因此常见于正则表达式解释器。缺点是要生成最小 DFA 时,计算成本通常并不便宜。
词法分析器最终不是为了展示自动机,而是为了快速扫描输入。DFA 在这一步特别有优势,因为它可以非常自然地实现成一张二维转移表。
设表项 $T[i, a] = k$,它表示“当前处于状态 $i$,读到输入字符 $a$ 时,下一步跳到状态 $k$”。这里的 $i$ 是状态编号,$a$ 是输入符号,$k$ 是目标状态编号。这样一来,执行过程几乎就变成了一个简单循环:读字符、查表、更新状态、继续前进。
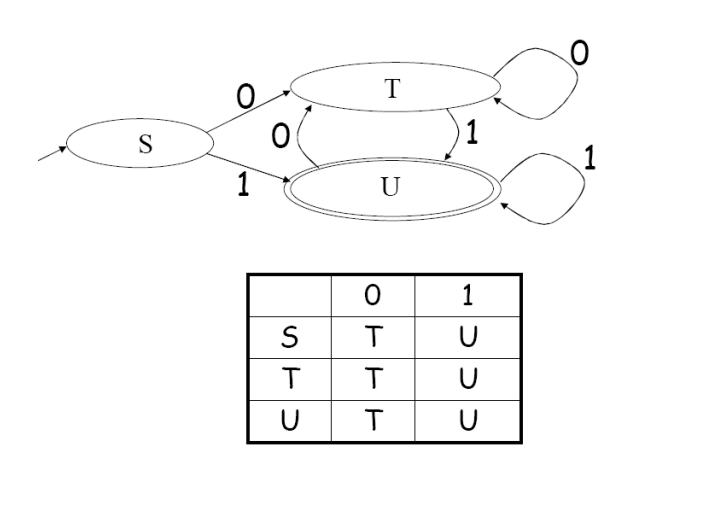
这种实现方式的好处是速度稳定而且非常直接,没有回溯搜索,也不需要在运行时维护一堆并行分支。这也是为什么很多 lexer generator 都愿意花构造和优化的成本,把规则先变成 DFA,再生成最终代码。
当然,工程上不会只盯着速度。DFA 可能很大,尤其当 token 规则多、字符集大、状态数膨胀明显时,完整查表会消耗不少空间。所以像 lex、flex、ocamllex、Rust 生态里的 logos 和 lalrpop 这类工具,实际实现时往往会在速度和空间之间做权衡,选择更紧凑的 NFA 或 DFA 表示法,而不是一味追求最直接的“大而全”表格。
只要系统里同时存在多条 token 规则,歧义就会出现。比如关键字 for 和标识符规则 [A-Za-z_][A-Za-z0-9_]* 明显会冲突,因为字符串 for 同时满足两者。词法分析器必须给出可重复、可实现、而且足够高效的决策规则。
最基本的规则是从左到右扫描,并采用 maximal munch,也就是最长匹配。它的意思不是“尽快匹配到一个合法 token 就停”,而是“在当前位置上,尽可能吃掉最长的前缀”。只有这样,lexer 才不会过早截断输入。
实现 maximal munch 的一个直接方法,是把所有 token 正则表达式都转成 NFA,然后在扫描时并行运行这些自动机,同时记住“最近一次成功匹配”的位置和对应 token。一旦继续往前读时,所有自动机都走不动了,就回退到最近一次成功匹配的位置,输出那个 token,再从那里重新开始扫描。
这个策略非常重要,因为很多时候“最早接受”并不是正确答案。比如同时存在 do、double 和单字母规则时,扫描前缀时可能很早就已经遇到一个可接受状态,但后面仍然还有机会延长匹配长度。只有等所有候选路径都彻底失败,才能确定最近一次接受的位置就是当前位置应该输出的 lexeme 终点。
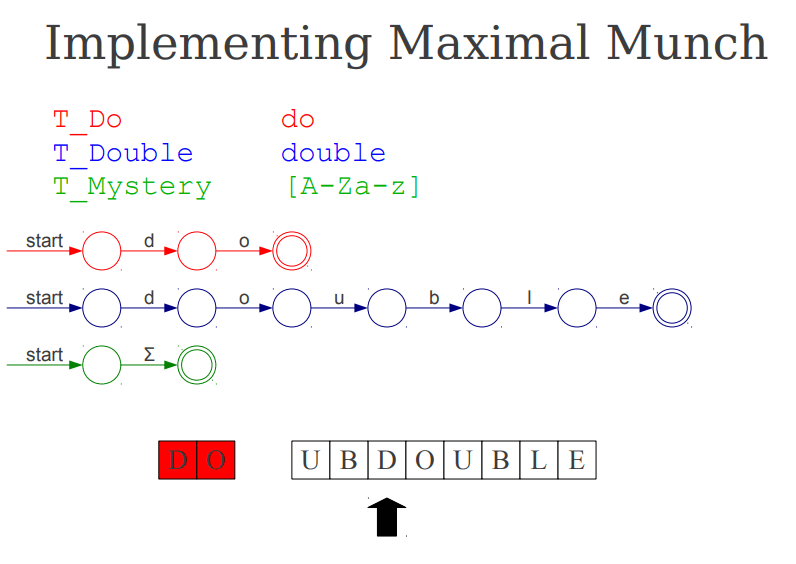
最长匹配解决的是“吃多长”的问题,但它还不能解决“同样长时选谁”的问题。仍然以前面的例子来说,double 既可能是一个关键字,也可能满足标识符规则;它们匹配的长度完全一样。这时就需要第二层规则:显式优先级,通常由规则书写顺序决定。把关键字规则放在标识符规则之前,就能保证 double 被识别成关键字而不是普通标识符。
这也说明了一个经常被忽略的事实:lexer 并不是单纯的“正则表达式匹配器”。它是在一组正则语言之上,再叠加最长匹配、优先级和执行策略后,得到的一个完整决策系统。
如果只看表面,词法分析好像只是“拿几个正则表达式去扫字符串”。但把整个过程连起来看,它其实是一条非常完整的编译链路:用正则表达式描述 token 语言,用有限自动机承载中间表示,用子集构造消除运行时分支,用最小化去掉冗余状态,再把最终结果压成高效的查表代码。遇到多个规则并存时,再用最长匹配和规则优先级把歧义消解掉。
这条路线之所以经典,不是因为它唯一,而是因为它把“理论上可证明正确”和“工程上足够高效”很好地结合在了一起。它也同时划清了 lexer 的边界:词法分析器非常适合识别正则语言,擅长把字符流切成 token,却还不够强大,不能替代后续的语法分析和语义分析。